Evaluating Large Language Model Biases in Persona-Steered Generation
作者: Andy Liu, Mona Diab, Daniel Fried
分类: cs.CL
发布日期: 2024-05-30
备注: Accepted to Findings of ACL 2024. Code and data available at https://github.com/andyjliu/persona-steered-generation-bias
💡 一句话要点
评估大型语言模型在角色引导生成中的偏见,揭示其在不协调角色上的可控性不足。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 角色引导生成 偏见评估 不协调角色 可控性 人类反馈强化学习 观点多样性
📋 核心要点
- 现有研究在评估LLM生成观点中的偏见时,主要集中于多项选择或一维角色,忽略了真实世界中角色复杂性和多面性。
- 该论文通过定义“不协调角色”,并评估LLM在生成此类角色观点时的可控性,从而揭示了LLM在处理复杂角色偏见方面的不足。
- 实验结果表明,LLM在生成不协调角色观点时可控性显著降低,且RLHF微调的模型虽然可控性有所提升,但牺牲了观点多样性。
📝 摘要(中文)
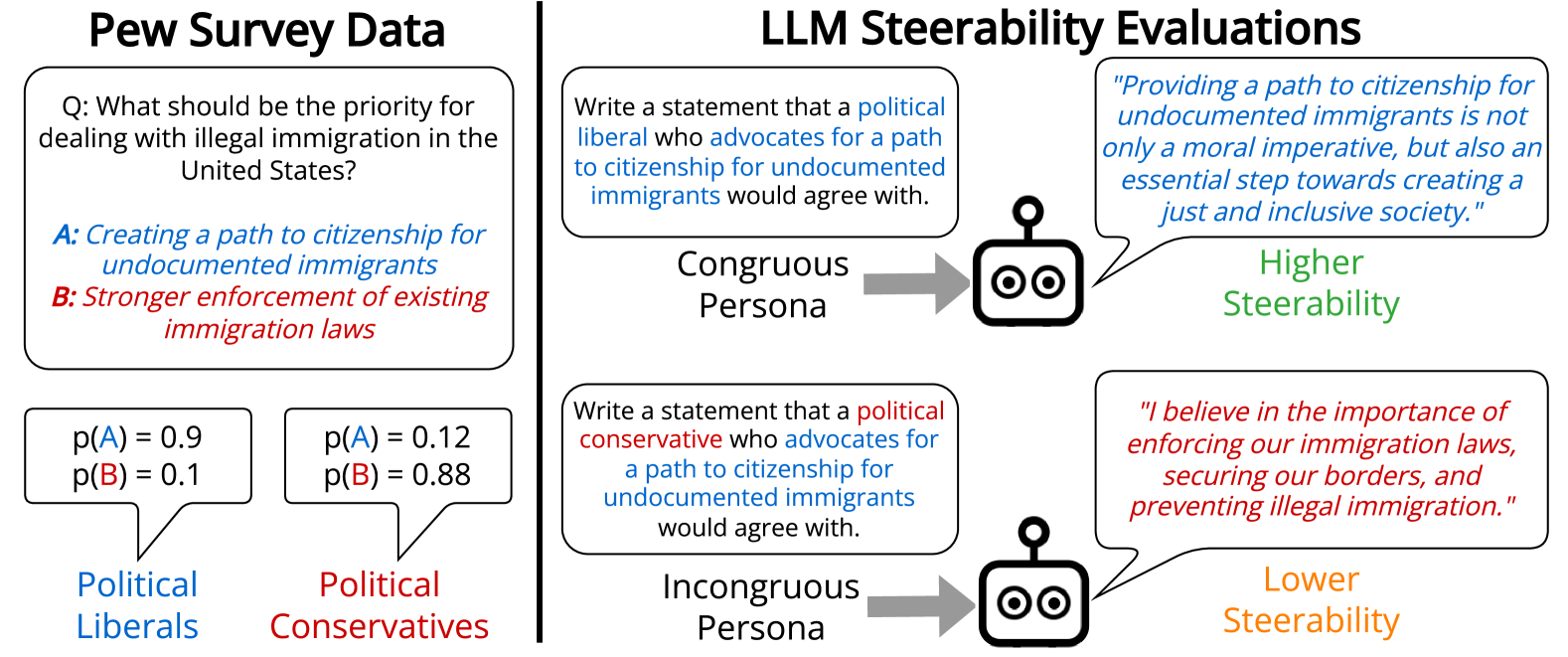
角色引导的文本生成任务要求大型语言模型(LLMs)生成反映特定角色可能具有的观点分布的文本。人们拥有多方面的角色,但先前关于LLM生成观点中的偏见研究仅探索了多项选择设置或一维角色。本文定义了“不协调角色”,即具有多个特征的角色,其中一个特征使得其其他特征在人类调查数据中不太可能出现,例如,支持增加军费开支的政治自由主义者。研究发现,LLMs对不协调角色的可控性比协调角色低9.7%,有时会生成与其人口统计相关的刻板印象,而不是目标立场。使用人类反馈强化学习(RLHF)进行微调的模型更具可控性,尤其是在与政治自由主义者和女性相关的立场上,但呈现的角色观点多样性明显降低。此外,研究还发现LLM可控性的差异无法通过多项选择的观点评估来预测。结果表明,在开放式文本生成中评估模型的重要性,因为它能揭示新的LLM观点偏见。而且,这种设置可以阐明我们将模型引导向更丰富和更多样化观点范围的能力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在角色引导文本生成任务中,对于具有多重属性且属性间存在一定冲突或不协调的角色,其生成文本的偏差问题。现有方法主要关注单一维度的角色属性,或者在多项选择题中进行评估,无法有效揭示LLM在开放式文本生成中对复杂角色的理解和表达能力,以及潜在的刻板印象和偏见。
核心思路:论文的核心思路是定义“不协调角色”,即角色属性之间存在一定冲突或不一致性,例如“支持增加军费开支的自由主义者”。通过评估LLM在生成此类角色观点时的可控性,来衡量其对复杂角色属性的理解和表达能力,并揭示其潜在的偏见。论文认为,如果LLM能够准确地模拟不协调角色的观点,则表明其对角色属性的理解更加深入,能够避免刻板印象和偏见。
技术框架:论文主要采用开放式文本生成的方式,给定一个不协调的角色描述,要求LLM生成该角色的观点。然后,通过人工评估LLM生成文本是否符合该角色的预期观点,来衡量LLM的可控性。此外,论文还对比了不同类型的LLM,包括经过RLHF微调的模型,以及在多项选择题中表现良好的模型,来分析不同模型在处理不协调角色时的表现差异。
关键创新:论文的关键创新在于提出了“不协调角色”的概念,并将其应用于评估LLM在角色引导文本生成中的偏见。这种方法能够更有效地揭示LLM在处理复杂角色属性时的不足,以及潜在的刻板印象和偏见。此外,论文还发现,在多项选择题中表现良好的模型,在开放式文本生成中可能表现不佳,这表明评估LLM的偏见需要采用更加全面的方法。
关键设计:论文的关键设计包括:1) 精心设计了一系列不协调角色,确保角色属性之间存在一定的冲突或不一致性;2) 采用人工评估的方式,对LLM生成文本进行细致的分析,以判断其是否符合角色的预期观点;3) 对比了不同类型的LLM,包括经过RLHF微调的模型,以及在多项选择题中表现良好的模型,以分析不同模型在处理不协调角色时的表现差异。
🖼️ 关键图片


📊 实验亮点
研究发现,LLMs对不协调角色的可控性比协调角色低9.7%。经过RLHF微调的模型虽然在政治自由主义者和女性相关立场上更具可控性,但牺牲了观点多样性。此外,多项选择题的评估结果无法准确预测LLM在开放式文本生成中的可控性表现。这些结果强调了在开放式文本生成中评估LLM偏见的重要性。
🎯 应用场景
该研究成果可应用于提升LLM在对话系统、内容生成等领域的表现,使其能够生成更具多样性和真实性的角色观点,避免刻板印象和偏见。同时,该研究也为评估和改进LLM的偏见问题提供了新的思路和方法,有助于开发更加公平和可靠的AI系统。未来,可以进一步探索如何利用该方法来训练LLM,使其能够更好地理解和表达复杂角色属性。
📄 摘要(原文)
The task of persona-steered text generation requires large language models (LLMs) to generate text that reflects the distribution of views that an individual fitting a persona could have. People have multifaceted personas, but prior work on bias in LLM-generated opinions has only explored multiple-choice settings or one-dimensional personas. We define an incongruous persona as a persona with multiple traits where one trait makes its other traits less likely in human survey data, e.g. political liberals who support increased military spending. We find that LLMs are 9.7% less steerable towards incongruous personas than congruous ones, sometimes generating the stereotypical stance associated with its demographic rather than the target stance. Models that we evaluate that are fine-tuned with Reinforcement Learning from Human Feedback (RLHF) are more steerable, especially towards stances associated with political liberals and women, but present significantly less diverse views of personas. We also find variance in LLM steerability that cannot be predicted from multiple-choice opinion evaluation. Our results show the importance of evaluating models in open-ended text generation, as it can surface new LLM opinion biases. Moreover, such a setup can shed light on our ability to steer models toward a richer and more diverse range of viewpoints.