Jina CLIP: Your CLIP Model Is Also Your Text Retriever
作者: Andreas Koukounas, Georgios Mastrapas, Michael Günther, Bo Wang, Scott Martens, Isabelle Mohr, Saba Sturua, Mohammad Kalim Akram, Joan Fontanals Martínez, Saahil Ognawala, Susana Guzman, Maximilian Werk, Nan Wang, Han Xiao
分类: cs.CL, cs.AI, cs.CV, cs.IR
发布日期: 2024-05-30 (更新: 2024-06-26)
备注: 4 pages, MFM-EAI@ICML2024
💡 一句话要点
提出多任务对比学习方法,使CLIP模型同时具备优秀的图文和文本检索能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CLIP模型 多模态检索 对比学习 文本检索 图像检索 多任务学习 信息检索
📋 核心要点
- 现有CLIP模型在文本检索任务中表现不如专门的文本模型,导致信息检索系统需要维护多个模型。
- 论文提出一种多任务对比训练方法,旨在提升CLIP模型在文本检索任务中的性能,使其同时擅长图文和文本检索。
- 实验结果表明,使用该方法训练的jina-clip-v1模型在文本-图像和文本-文本检索任务上均达到了最先进的性能。
📝 摘要(中文)
对比语言-图像预训练(CLIP)被广泛用于训练模型,通过将图像和文本映射到固定大小的向量,从而在公共嵌入空间中对齐它们。这些模型是多模态信息检索和相关任务的关键。然而,与专门的文本模型相比,CLIP模型在纯文本任务中的表现通常不佳。这为信息检索系统带来了效率问题,因为它们需要为纯文本和多模态任务维护单独的嵌入和模型。我们提出了一种新颖的多任务对比训练方法来解决这个问题,并使用该方法训练了jina-clip-v1模型,使其在文本-图像和文本-文本检索任务上均实现了最先进的性能。
🔬 方法详解
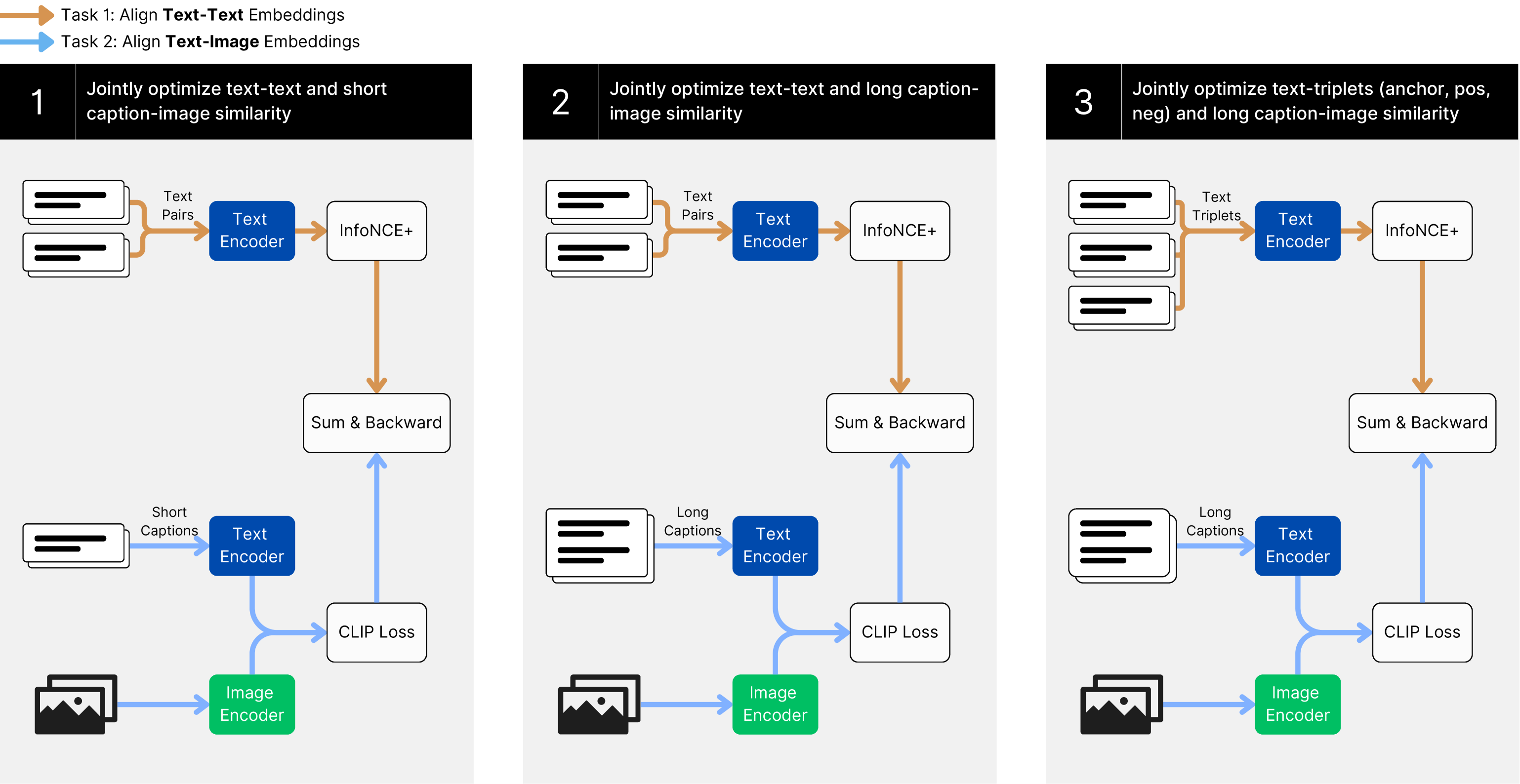
问题定义:CLIP模型在图文检索任务中表现出色,但在纯文本检索任务中性能不如专门的文本模型。这导致需要维护两个独立的模型,增加了系统复杂性和资源消耗。论文旨在解决CLIP模型在文本检索方面的不足,使其能够同时胜任图文和文本检索任务。
核心思路:论文的核心思路是采用多任务对比学习,同时优化模型在图文和文本检索任务上的性能。通过共享底层表示,使模型能够更好地理解文本语义,从而提升文本检索能力。这样,一个模型就可以同时处理两种类型的检索任务,简化系统架构。
技术框架:该方法基于CLIP模型,并对其训练过程进行改进。主要包括以下几个阶段:1) 数据准备:构建包含图文对和文本对的训练数据集。2) 模型训练:使用多任务对比损失函数,同时优化模型在图文和文本检索任务上的性能。3) 模型评估:在标准数据集上评估模型的性能,包括图文检索和文本检索。
关键创新:关键创新在于多任务对比学习方法的应用。传统的CLIP模型主要关注图文对齐,而该方法通过引入文本对齐任务,使模型能够更好地理解文本语义。这种多任务学习的方式可以有效提升模型在文本检索任务中的性能,同时保持在图文检索任务上的竞争力。
关键设计:论文中关键的设计包括:1) 多任务对比损失函数的设计,需要平衡图文对齐和文本对齐两个任务。2) 训练数据的选择,需要包含足够数量的图文对和文本对,以保证模型的训练效果。3) 模型结构的调整,可能需要对CLIP模型的结构进行微调,以适应多任务学习的需求。
🖼️ 关键图片
📊 实验亮点
该论文提出的方法在文本-图像和文本-文本检索任务上均取得了state-of-the-art的性能。具体性能数据和对比基线未在摘要中给出,但强调了jina-clip-v1模型在两个任务上的优越性,表明该方法在提升CLIP模型文本检索能力方面具有显著效果。
🎯 应用场景
该研究成果可广泛应用于多模态信息检索系统,例如搜索引擎、图像搜索引擎、推荐系统等。通过使用一个统一的CLIP模型,可以同时支持图文检索和文本检索,简化系统架构,提高检索效率。此外,该方法还可以应用于其他多模态任务,例如图像描述生成、视觉问答等。
📄 摘要(原文)
Contrastive Language-Image Pretraining (CLIP) is widely used to train models to align images and texts in a common embedding space by mapping them to fixed-sized vectors. These models are key to multimodal information retrieval and related tasks. However, CLIP models generally underperform in text-only tasks compared to specialized text models. This creates inefficiencies for information retrieval systems that keep separate embeddings and models for text-only and multimodal tasks. We propose a novel, multi-task contrastive training method to address this issue, which we use to train the jina-clip-v1 model to achieve the state-of-the-art performance on both text-image and text-text retrieval tasks.