Is In-Context Learning Sufficient for Instruction Following in LLMs?
作者: Hao Zhao, Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-05-30 (更新: 2025-04-18)
备注: Accepted at ICLR 2025. This camera-ready version v3 adds multi-turn alignment via ICL, revisiting main results on instruct models, and simple mechanistic study. Updates in the v2: experiment with decoding schemes, scaling in-context alignment, ICL vs IFT for instruction following. Code at https://github.com/tml-epfl/icl-alignment
🔗 代码/项目: GITHUB
💡 一句话要点
研究表明,上下文学习在指令跟随任务中仍逊于指令微调,并揭示了解码参数的关键作用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 指令跟随 大型语言模型 指令微调 解码参数 模型对齐 低数据学习
📋 核心要点
- 现有方法URIAL虽然能通过少量上下文示例对齐LLM,但在指令跟随任务上,尤其是在更强大的LLM上,性能仍低于指令微调。
- 论文通过分析发现,解码参数在上下文学习对齐中起着关键作用,并提出可以通过添加高质量的上下文演示来提升ICL的性能。
- 论文首次系统比较了低数据状态下ICL和指令微调在指令跟随任务中的表现,为ICL作为IFT的替代方案提供了依据。
📝 摘要(中文)
上下文学习(ICL)允许大型语言模型(LLM)在不改变模型权重的情况下从示例中学习,对于能够从大量示例中学习的长上下文LLM来说,这是一个非常有前景的能力。最近,Lin等人(2024)提出了URIAL,一种仅使用三个上下文示例来对齐基础LLM的方法,实现了显著的指令跟随性能。本文表明,虽然有效,但与在已建立的MT-Bench基准上进行指令微调相比,使用URIAL进行ICL对齐仍然表现不佳,尤其是在更强大的基础LLM上。然后,我们揭示了成功进行上下文对齐的最相关因素,发现了解码参数的关键作用。基于这些见解,我们表明,URIAL的方法确实可以通过在上下文中添加高质量的演示(可能通过贪婪搜索精心选择)来改进,从而更接近指令模型的性能。最后,我们首次对ICL和指令微调(IFT)在低数据状态下进行指令跟随进行了系统的比较,在这种情况下,ICL可能是IFT的可行替代方案。总的来说,我们的工作提高了对ICL作为一种对齐技术及其与IFT关系的理解。我们在https://github.com/tml-epfl/icl-alignment提供了我们的代码。
🔬 方法详解
问题定义:论文旨在研究上下文学习(ICL)在指令跟随任务中的有效性,并将其与指令微调(IFT)进行比较。现有方法,如URIAL,虽然能够通过少量上下文示例对齐LLM,但在性能上仍然落后于指令微调,尤其是在使用更强大的基础LLM时。此外,现有研究对ICL和IFT在低数据状态下的比较还不够系统。
核心思路:论文的核心思路是通过深入分析影响ICL性能的关键因素,特别是解码参数,来提升ICL在指令跟随任务中的表现。同时,通过系统性的实验比较ICL和IFT在低数据状态下的性能,为选择合适的对齐方法提供指导。
技术框架:论文的技术框架主要包括以下几个部分:1) 使用URIAL方法进行ICL对齐,并与指令微调进行比较;2) 分析影响ICL性能的关键因素,特别是解码参数;3) 通过添加高质量的上下文演示来提升ICL的性能;4) 在MT-Bench基准上进行实验评估,比较ICL和IFT的性能。
关键创新:论文的关键创新在于:1) 揭示了解码参数在ICL对齐中的关键作用;2) 提出可以通过添加高质量的上下文演示来提升ICL的性能,使其更接近指令微调的性能;3) 首次系统比较了ICL和IFT在低数据状态下的指令跟随任务中的表现。
关键设计:论文的关键设计包括:1) 使用MT-Bench作为评估基准;2) 通过贪婪搜索选择高质量的上下文演示;3) 系统性地调整和评估解码参数对ICL性能的影响;4) 在低数据状态下,对比ICL和IFT的性能,并分析其优缺点。
🖼️ 关键图片
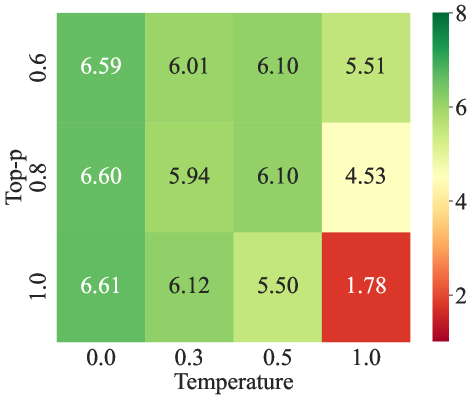


📊 实验亮点
实验结果表明,虽然URIAL方法有效,但ICL对齐在MT-Bench基准上仍然不如指令微调,尤其是在更强大的LLM上。通过优化解码参数和添加高质量的上下文演示,ICL的性能可以得到显著提升,更接近指令微调的水平。此外,论文首次系统比较了ICL和IFT在低数据状态下的性能,为实际应用中选择合适的对齐方法提供了重要参考。
🎯 应用场景
该研究成果可应用于各种需要指令跟随能力的自然语言处理任务,例如智能助手、聊天机器人、文本摘要、机器翻译等。通过优化上下文学习策略,可以提升LLM在资源受限场景下的性能,降低对大量标注数据的依赖,并为选择合适的模型对齐方法提供指导。
📄 摘要(原文)
In-context learning (ICL) allows LLMs to learn from examples without changing their weights: this is a particularly promising capability for long-context LLMs that can potentially learn from many examples. Recently, Lin et al. (2024) proposed URIAL, a method using only three in-context examples to align base LLMs, achieving non-trivial instruction following performance. In this work, we show that, while effective, ICL alignment with URIAL still underperforms compared to instruction fine-tuning on the established benchmark MT-Bench, especially with more capable base LLMs. We then uncover the most relevant elements for successful in-context alignment, finding the crucial role of the decoding parameters. Based on these insights, we show that the approach of URIAL can indeed be improved by adding high-quality, potentially carefully selected via greedy search, demonstrations in context, getting closer to the performance of instruct models. Finally, we provide the first, to our knowledge, systematic comparison of ICL and instruction fine-tuning (IFT) for instruction following in the low data regime, where ICL can be a viable alternative to IFT. Overall, our work advances the understanding of ICL as an alignment technique and its relationship to IFT. We provide our code at https://github.com/tml-epfl/icl-alignment.