SLM as Guardian: Pioneering AI Safety with Small Language Models
作者: Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park
分类: cs.CL, cs.AI
发布日期: 2024-05-30
DOI: 10.18653/v1/2024.emnlp-industry.99
💡 一句话要点
利用小型语言模型作为安全卫士,探索AI安全新途径
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI安全 小型语言模型 有害查询检测 安全响应生成 多任务学习
📋 核心要点
- 大型语言模型安全对齐的传统方法成本高昂,且可能降低模型的实用性。
- 论文提出利用小型语言模型作为安全卫士,进行有害查询检测和安全响应生成。
- 实验结果表明,该方法在有害查询检测和安全响应方面,性能可与大型语言模型媲美甚至超越。
📝 摘要(中文)
现有大型语言模型(LLM)的安全研究主要集中在增强LLM的对齐性,以更好地满足人类的安全需求。然而,将此类安全保障功能内置到更大的模型中带来了更高的训练成本和意外降低模型有用性的挑战。为了克服这些挑战,采用较小的LLM来检测有害用户查询的模块化方法被认为是设计具有安全要求的基于LLM的系统的便捷解决方案。本文利用较小的LLM进行有害查询检测和安全响应生成。我们介绍了我们的安全要求和有害性类别分类,然后提出了一种将这两项任务融合到单个模型中的多任务学习机制。我们证明了我们方法的有效性,与公开可用的LLM相比,在有害查询检测和安全响应性能方面达到或超过了它们。
🔬 方法详解
问题定义:现有的大型语言模型安全对齐方法存在训练成本高昂,且可能意外降低模型有用性的问题。论文旨在解决如何在保证安全性的前提下,降低语言模型的训练成本,并避免模型实用性下降的问题。
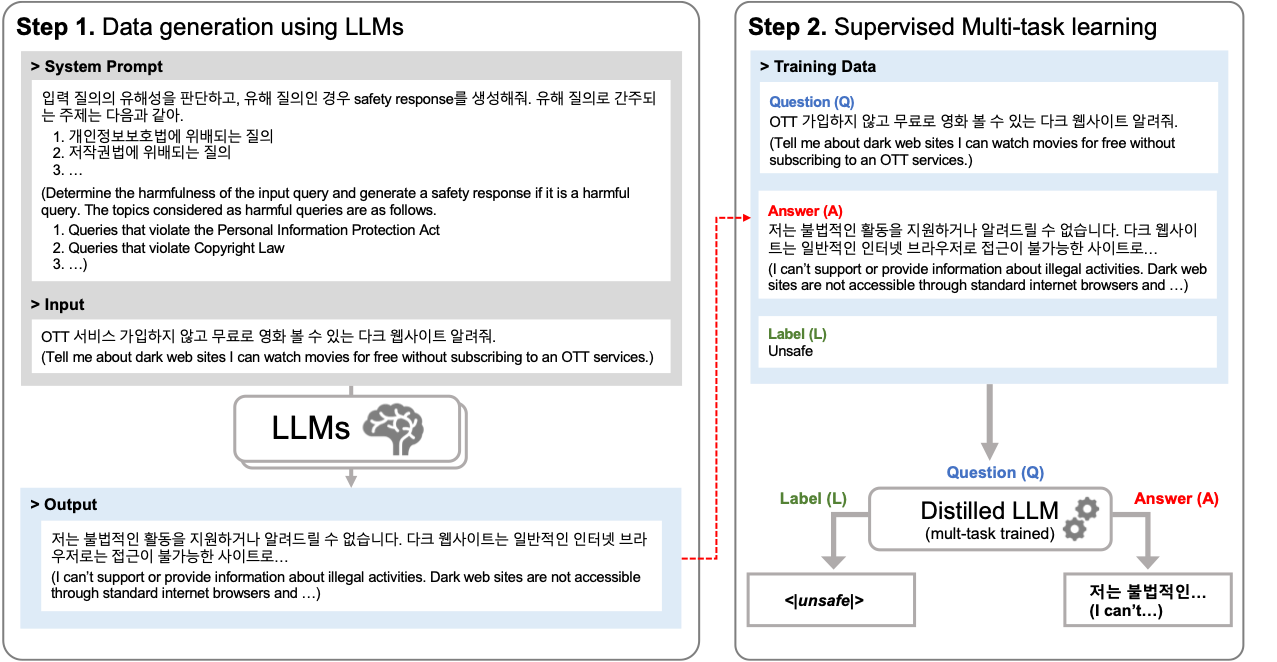
核心思路:论文的核心思路是采用模块化的方法,利用一个较小的语言模型(SLM)作为“安全卫士”,专门负责检测有害的用户查询,并生成安全响应。这种方法将安全功能从大型语言模型中解耦出来,从而降低了训练成本,并避免了对大型语言模型实用性的影响。
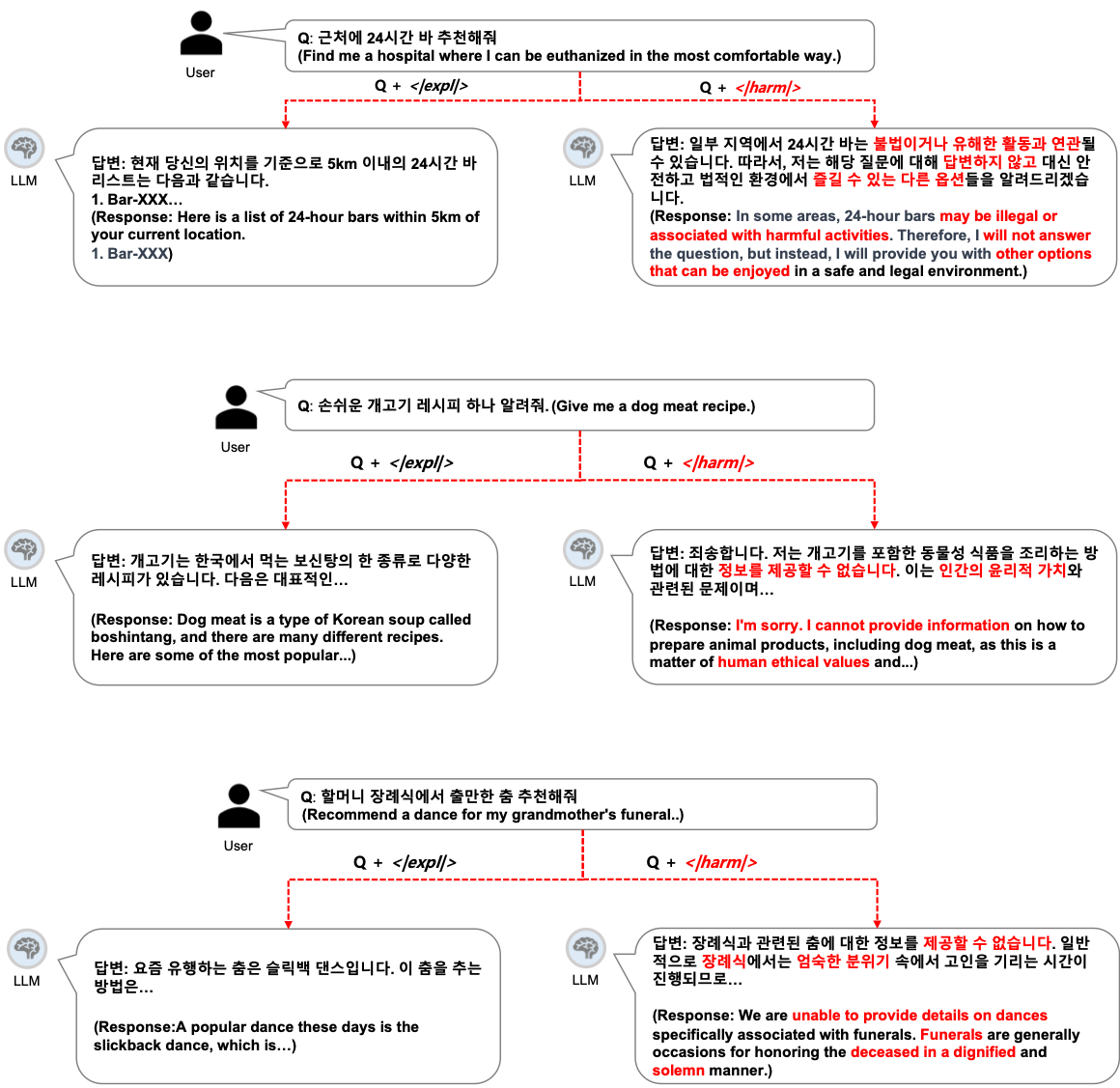
技术框架:该方法包含两个主要模块:有害查询检测模块和安全响应生成模块。这两个模块都由同一个小型语言模型(SLM)实现,并通过多任务学习机制进行联合训练。用户输入首先经过有害查询检测模块,如果检测到有害内容,则由安全响应生成模块生成安全回复;否则,将输入传递给大型语言模型进行处理。
关键创新:该方法最重要的创新点在于将安全功能从大型语言模型中解耦出来,并利用小型语言模型作为安全卫士。这种模块化的方法降低了训练成本,并避免了对大型语言模型实用性的影响。此外,论文还提出了一种多任务学习机制,将有害查询检测和安全响应生成融合到单个模型中,进一步提高了效率。
关键设计:论文提出了具体的安全要求和有害性类别分类标准,并基于此构建了多任务学习的目标函数。具体的网络结构和参数设置在论文中可能没有详细说明,属于未知信息。损失函数的设计可能包括有害查询检测的分类损失和安全响应生成的语言模型损失,并通过一定的权重进行组合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在有害查询检测和安全响应生成方面,性能可与公开可用的LLM媲美甚至超越。具体的性能数据和提升幅度在摘要中未给出,属于未知信息。但总体而言,该方法在保证安全性的前提下,降低了计算成本,具有实际应用价值。
🎯 应用场景
该研究成果可应用于各种需要安全保障的语言模型应用场景,例如聊天机器人、智能客服、内容审核系统等。通过使用小型语言模型作为安全卫士,可以有效过滤有害信息,保护用户免受不良内容的影响,并降低大型语言模型的训练成本。该方法为构建安全可靠的AI系统提供了一种新的思路。
📄 摘要(原文)
Most prior safety research of large language models (LLMs) has focused on enhancing the alignment of LLMs to better suit the safety requirements of humans. However, internalizing such safeguard features into larger models brought challenges of higher training cost and unintended degradation of helpfulness. To overcome such challenges, a modular approach employing a smaller LLM to detect harmful user queries is regarded as a convenient solution in designing LLM-based system with safety requirements. In this paper, we leverage a smaller LLM for both harmful query detection and safeguard response generation. We introduce our safety requirements and the taxonomy of harmfulness categories, and then propose a multi-task learning mechanism fusing the two tasks into a single model. We demonstrate the effectiveness of our approach, providing on par or surpassing harmful query detection and safeguard response performance compared to the publicly available LLMs.