Prompting or Fine-tuning? Exploring Large Language Models for Causal Graph Validation
作者: Yuni Susanti, Nina Holsmoelle
分类: cs.CL, cs.AI
发布日期: 2024-05-29 (更新: 2025-04-09)
期刊: Causal-NeSy @ ESWC 2025
💡 一句话要点
探索大语言模型在因果图验证中的应用:微调优于提示学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果图验证 大型语言模型 提示学习 微调 因果关系预测 自然语言处理 生物医学 自动化
📋 核心要点
- 传统因果图验证依赖领域专家手动评估,效率低且成本高昂。
- 利用大语言模型理解文本上下文,自动推断变量间的因果关系。
- 实验表明,微调后的语言模型在因果关系预测任务中显著优于基于提示的方法。
📝 摘要(中文)
本研究探索了大型语言模型(LLM)评估因果图中因果关系的能力,这些因果图由传统的统计因果发现方法生成。该任务传统上依赖于人类领域专家的手动评估。为了弥合因果关系评估中的这一差距,我们利用LLM通过确定变量对之间的因果关系是否可以从文本上下文中推断出来,从而评估因果关系。我们的研究比较了两种方法:(1)基于提示的方法,用于零样本和少样本因果推理;(2)微调语言模型,用于因果关系预测任务。虽然基于提示的LLM已在各种NLP任务中展示了通用性,但我们在生物医学和通用领域数据集上的实验表明,微调模型始终优于它们,在F1得分上提高了高达20.5个百分点——即使使用参数较小的语言模型也是如此。这些发现为因果图评估中两种方法的优势和局限性提供了宝贵的见解。
🔬 方法详解
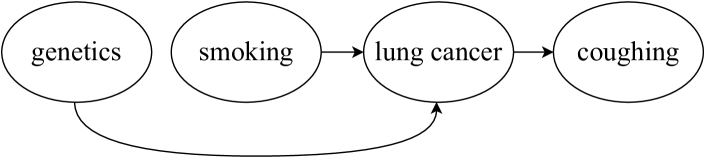
问题定义:论文旨在解决因果图验证的问题。现有的统计因果发现方法生成的因果图,需要领域专家进行手动验证,以确认因果关系的合理性。这种人工验证方式耗时耗力,且容易受到主观因素的影响。因此,如何自动化且高效地验证因果图的因果关系是亟待解决的问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)的自然语言理解能力,从文本上下文中推断变量之间的因果关系。通过让LLM判断文本描述是否支持给定的因果连接,从而实现对因果图的自动验证。论文比较了两种利用LLM的方法:基于提示学习和基于微调。
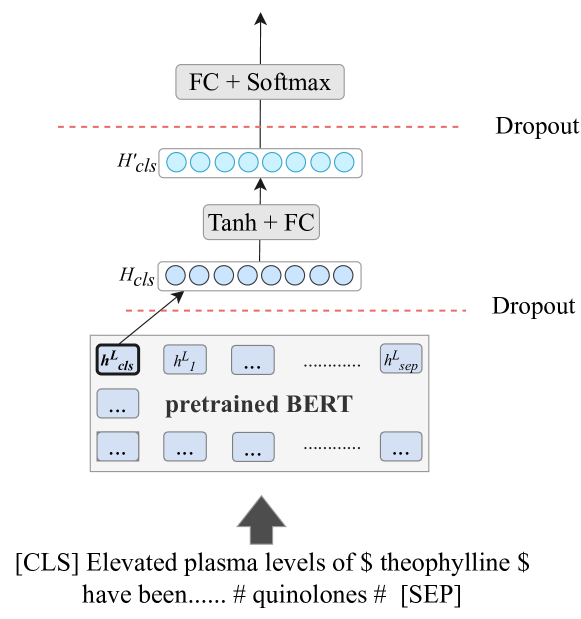
技术框架:整体框架包含两个主要分支:基于提示学习和基于微调。基于提示学习的方法直接利用预训练LLM的知识,通过设计合适的提示语,引导LLM进行因果关系判断。基于微调的方法则使用标注好的因果关系数据集,对LLM进行微调,使其更适应因果关系预测任务。两种方法都以变量对和相关的文本上下文作为输入,输出该因果关系是否成立的判断。
关键创新:论文的关键创新在于比较了基于提示学习和基于微调两种方法在因果图验证任务中的性能。实验结果表明,即使使用参数量较小的语言模型,微调后的模型也能显著优于基于提示学习的模型。这表明,对于特定的因果关系预测任务,微调能够更好地利用LLM的知识。
关键设计:在基于提示学习的方法中,关键在于设计合适的提示语,以引导LLM进行正确的推理。在基于微调的方法中,关键在于选择合适的预训练模型和微调策略。论文使用了标准的交叉熵损失函数进行训练,并对超参数进行了优化。具体使用的预训练模型和数据集在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在生物医学和通用领域数据集上,微调后的语言模型在因果关系预测任务中始终优于基于提示学习的模型,F1得分最高提升了20.5个百分点。即使使用参数量较小的语言模型进行微调,也能取得显著的性能提升,证明了微调方法在特定任务上的有效性。
🎯 应用场景
该研究成果可应用于生物医学、社会科学、经济学等多个领域,帮助研究人员更高效地验证因果关系,加速科学发现。通过自动化因果图验证,可以减少对领域专家的依赖,降低研究成本,并提高研究效率。未来,该方法可进一步扩展到更复杂的因果关系推理任务中。
📄 摘要(原文)
This study explores the capability of Large Language Models (LLMs) to evaluate causality in causal graphs generated by conventional statistical causal discovery methods-a task traditionally reliant on manual assessment by human subject matter experts. To bridge this gap in causality assessment, LLMs are employed to evaluate the causal relationships by determining whether a causal connection between variable pairs can be inferred from textual context. Our study compares two approaches: (1) prompting-based method for zero-shot and few-shot causal inference and, (2) fine-tuning language models for the causal relation prediction task. While prompt-based LLMs have demonstrated versatility across various NLP tasks, our experiments on biomedical and general-domain datasets show that fine-tuned models consistently outperform them, achieving up to a 20.5-point improvement in F1 score-even when using smaller-parameter language models. These findings provide valuable insights into the strengths and limitations of both approaches for causal graph evaluation.