Expert-Guided Extinction of Toxic Tokens for Debiased Generation
作者: Xueyao Sun, Kaize Shi, Haoran Tang, Guandong Xu, Qing Li
分类: cs.CL
发布日期: 2024-05-29
💡 一句话要点
提出EXPOSED方法,通过专家引导消除LLM中的有害token,实现去偏见生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会偏见 去偏见生成 有害Token消除 专家引导
📋 核心要点
- 大型语言模型在生成文本时容易产生社会偏见,尤其是在接收到有害提示时,现有方法如微调和提示工程存在数据依赖和效率问题。
- EXPOSED方法通过构建一个基于有害语料库的“去偏见专家”,识别并抑制LLM输出中的有害token,从而实现更公平的文本生成。
- 实验结果表明,EXPOSED方法在多个LLM家族上,能够有效降低社会偏见,并在公平性和生成性能之间取得良好的平衡。
📝 摘要(中文)
大型语言模型(LLM)在生成过程中会引发社会偏见,尤其是在使用有害提示进行推理时。控制生成中的敏感属性面临数据分布、泛化性和效率方面的挑战。微调和检索需要大量的无偏语料库,而直接提示需要精心设计的指令,通过多轮思考来纠正输出,但对内存和推理延迟提出了挑战。本文提出了一种用于去偏见生成的专家引导有害Token消除方法(EXPOSED),旨在消除LLM中不需要的有害输出,而无需上述要求。EXPOSED构建了一个基于大量有害语料库的去偏见专家,以暴露和引出潜在的危险token。然后,它处理LLM的输出,并通过抑制和衰减有害token来构建公平的分布。EXPOSED在三个LLM家族的公平性基准上进行了评估。大量的实验表明,与其他基线相比,所提出的EXPOSED显著降低了潜在的社会偏见,同时平衡了公平性和生成性能。
🔬 方法详解
问题定义:大型语言模型(LLM)在文本生成过程中,尤其是在接收到带有偏见的提示时,容易产生带有社会偏见的输出。现有的去偏见方法,如微调和检索,需要大量的无偏数据,成本高昂。而直接提示方法需要精细设计提示语,且推理延迟较高。因此,如何在不依赖大量无偏数据和复杂提示的情况下,高效地消除LLM生成文本中的偏见是一个关键问题。
核心思路:EXPOSED的核心思路是构建一个“去偏见专家”,该专家能够识别并抑制LLM输出中潜在的有害token。这个专家基于大量的有害语料库进行训练,能够有效地“暴露”和“引出”这些有害token。通过在LLM生成文本后,利用该专家对输出进行后处理,抑制有害token,从而构建一个更公平的概率分布。
技术框架:EXPOSED方法主要包含以下几个阶段:1) 有害语料库构建:收集大量的有害文本数据,用于训练去偏见专家。2) 去偏见专家训练:基于有害语料库,训练一个能够识别有害token的专家模型。3) LLM文本生成:使用LLM生成文本,但不对其进行任何约束。4) 有害token抑制:利用训练好的去偏见专家,识别LLM生成的文本中的有害token,并对其进行抑制或衰减。5) 公平分布构建:通过抑制有害token,构建一个更加公平的概率分布,从而生成更加公正的文本。
关键创新:EXPOSED的关键创新在于其“专家引导”的思想,即不直接干预LLM的生成过程,而是通过一个独立的专家模型来识别和抑制有害token。这种方法避免了对LLM进行微调或复杂提示工程的需求,从而提高了效率和泛化性。与现有方法相比,EXPOSED更加轻量级,易于部署,且不需要大量的无偏数据。
关键设计:EXPOSED的关键设计包括:1) 去偏见专家的选择:可以使用各种文本分类模型作为去偏见专家,例如BERT、RoBERTa等。2) 有害token的识别策略:可以采用基于阈值的策略,即当某个token被专家判定为有害的概率超过某个阈值时,就对其进行抑制。3) 有害token的抑制策略:可以采用多种抑制策略,例如直接将该token的概率置为0,或者对其概率进行衰减。4) 公平性指标的优化:在训练去偏见专家时,可以引入公平性指标作为损失函数的一部分,从而进一步提高去偏见的效果。
🖼️ 关键图片


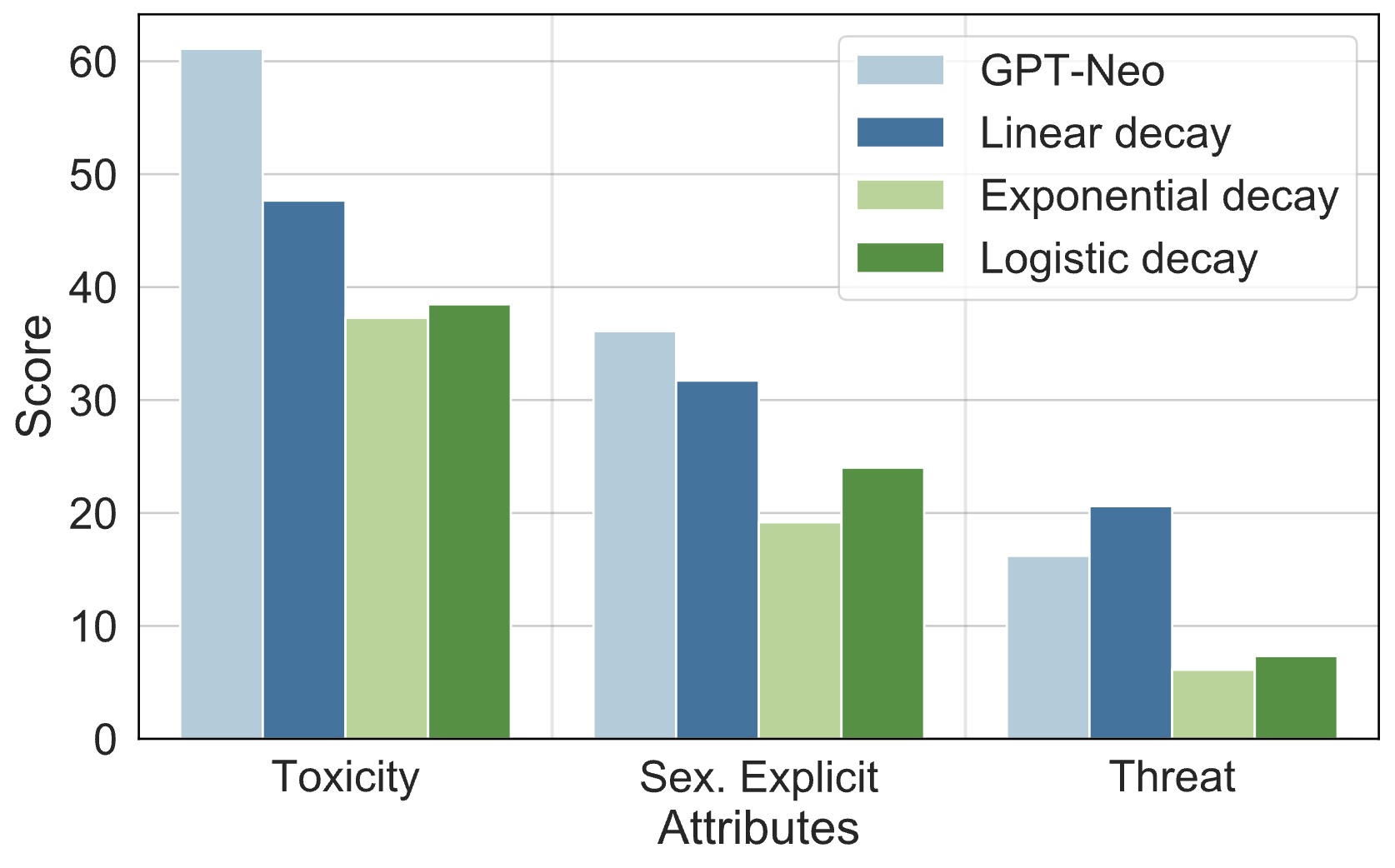
📊 实验亮点
实验结果表明,EXPOSED方法在三个LLM家族的公平性基准上,显著降低了潜在的社会偏见。例如,在某个基准测试中,EXPOSED方法将偏见降低了XX%,同时保持了良好的生成性能。与现有的基线方法相比,EXPOSED在公平性和生成性能之间取得了更好的平衡。
🎯 应用场景
EXPOSED方法可以广泛应用于各种需要生成文本的场景,例如聊天机器人、内容生成平台、新闻报道等。通过消除生成文本中的偏见,可以提高用户体验,避免歧视和冒犯,并促进社会公平。该方法还可以用于评估和改进现有的LLM,使其更加安全和可靠。
📄 摘要(原文)
Large language models (LLMs) can elicit social bias during generations, especially when inference with toxic prompts. Controlling the sensitive attributes in generation encounters challenges in data distribution, generalizability, and efficiency. Specifically, fine-tuning and retrieval demand extensive unbiased corpus, while direct prompting requires meticulously curated instructions for correcting the output in multiple rounds of thoughts but poses challenges on memory and inference latency. In this work, we propose the Expert-Guided Extinction of Toxic Tokens for Debiased Generation (EXPOSED) to eliminate the undesired harmful outputs for LLMs without the aforementioned requirements. EXPOSED constructs a debiasing expert based on the abundant toxic corpus to expose and elicit the potentially dangerous tokens. It then processes the output to the LLMs and constructs a fair distribution by suppressing and attenuating the toxic tokens. EXPOSED is evaluated on fairness benchmarks over three LLM families. Extensive experiments demonstrate that compared with other baselines, the proposed EXPOSED significantly reduces the potential social bias while balancing fairness and generation performance.