Weak-to-Strong Search: Align Large Language Models via Searching over Small Language Models
作者: Zhanhui Zhou, Zhixuan Liu, Jie Liu, Zhichen Dong, Chao Yang, Yu Qiao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-05-29 (更新: 2024-11-19)
备注: NeurIPS 2024
💡 一句话要点
提出弱到强搜索方法,通过小模型搜索提升大语言模型的对齐效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型对齐 弱监督学习 模型搜索 指令遵循 AlpacaEval 计算效率 贪婪搜索
📋 核心要点
- 现有方法直接微调大语言模型以对齐人类偏好,但计算成本高昂且面临优化挑战。
- 论文提出弱到强搜索,利用小模型的对数概率差指导大模型的生成,无需直接微调大模型。
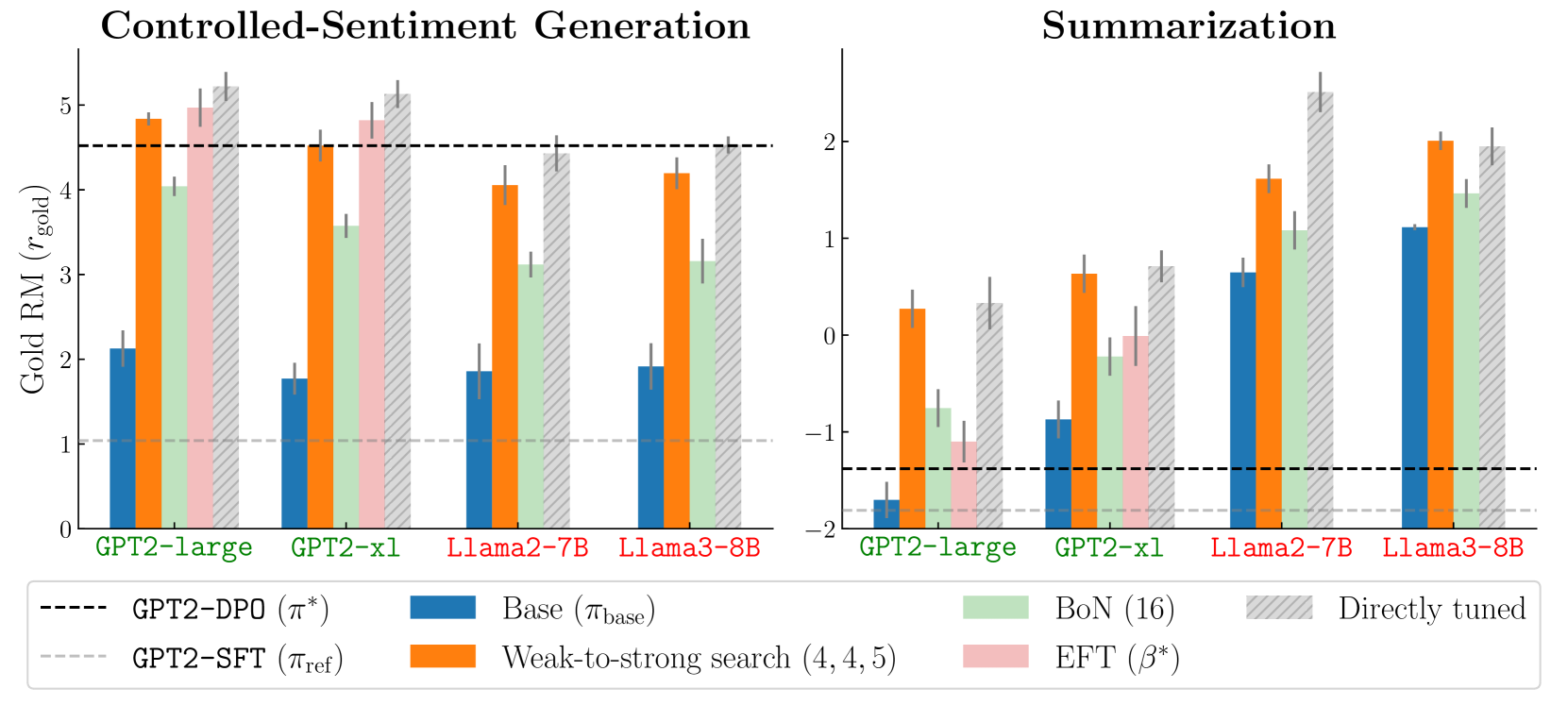
- 实验表明,该方法在情感生成、摘要和指令遵循任务中均能有效提升大模型的对齐效果。
📝 摘要(中文)
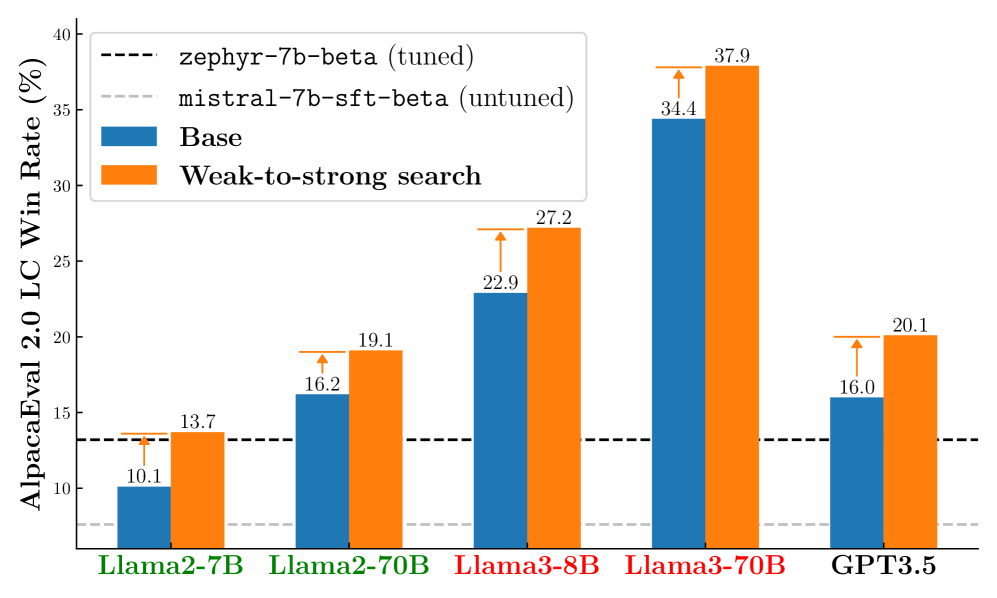
大型语言模型通常需要进行微调以与人类偏好对齐。然而,微调大型语言模型具有挑战性。本文提出了一种名为“弱到强搜索”的方法,将大型语言模型的对齐过程转化为一个测试时的贪婪搜索,旨在最大化已调优的小模型和未调优的小模型之间的对数概率差,同时从冻结的大型模型中进行采样。该方法既可以作为一种计算高效的模型放大策略,避免直接调整大型模型,也可以作为一种弱到强泛化的实例,利用弱模型的测试时指导来增强强模型。实验结果表明,弱到强搜索在不同任务中具有灵活性。在受控情感生成和摘要任务中,我们使用已调优和未调优的gpt2模型来提高大型模型的对齐效果,而无需额外的训练。更重要的是,在一个更具挑战性的指令遵循基准AlpacaEval 2.0中,我们表明,重用现成的的小型模型(例如,zephyr-7b-beta及其未调优版本)可以提高白盒和黑盒大型模型在长度控制下的胜率,使其对抗gpt-4-turbo(例如,Llama-3-70B-Instruct的胜率从34.4%提高到37.9%,gpt-3.5-turbo-instruct的胜率从16.0%提高到20.1%),尽管小型模型的胜率仅约为10.0%。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法通常需要直接对大模型进行微调,这带来了巨大的计算开销和优化难度。此外,如何有效地利用较小模型的知识来指导大型模型的生成也是一个挑战。
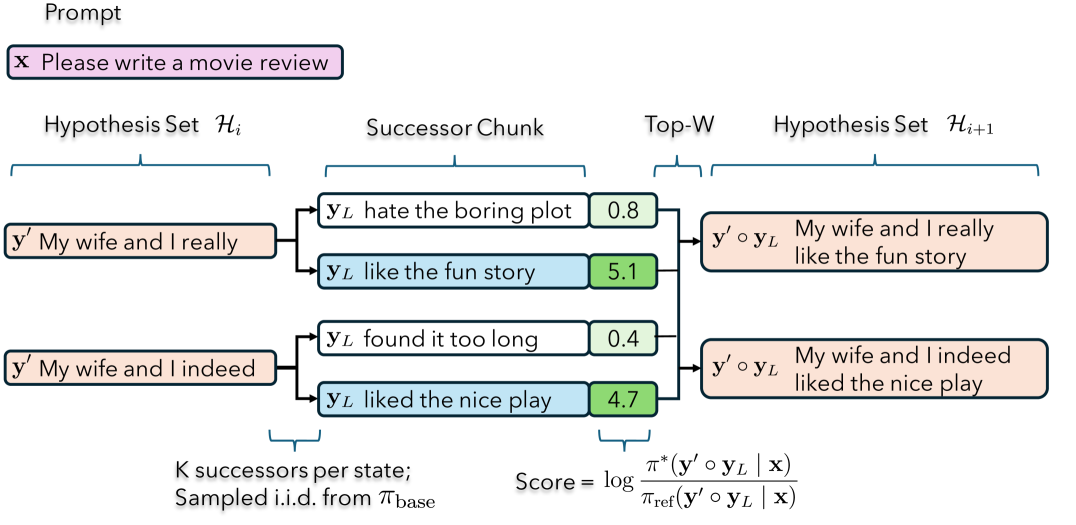
核心思路:论文的核心思路是将大型语言模型的对齐问题转化为一个搜索问题。具体来说,通过搜索那些能够最大化已调优小模型和未调优小模型之间对数概率差异的文本,来引导大型模型的生成。这种方法利用了小模型对人类偏好的判断能力,从而在不直接微调大模型的情况下,提升其对齐效果。
技术框架:弱到强搜索方法主要包含以下几个步骤:1. 使用已调优和未调优的小型语言模型。2. 从冻结的大型语言模型中进行采样生成候选文本。3. 计算每个候选文本在已调优和未调优小模型中的对数概率,并计算二者之差。4. 选择对数概率差最大的文本作为最终生成结果。这个过程可以看作是在大型模型的生成空间中,利用小模型作为弱监督信号进行搜索。
关键创新:该方法最重要的创新在于将大模型的对齐问题转化为一个测试时的搜索问题,避免了直接微调大模型带来的计算开销。此外,该方法还巧妙地利用了小模型对人类偏好的判断能力,通过最大化已调优和未调优小模型之间的对数概率差,来引导大模型的生成。
关键设计:关键设计在于如何有效地计算已调优和未调优小模型之间的对数概率差,并将其作为搜索的优化目标。具体来说,论文使用贪婪搜索算法,每次选择能够最大化对数概率差的token。此外,论文还探索了不同的采样策略,以提高搜索的效率和效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,弱到强搜索方法在AlpacaEval 2.0基准测试中,显著提高了大型模型的胜率。例如,Llama-3-70B-Instruct的胜率从34.4%提高到37.9%,gpt-3.5-turbo-instruct的胜率从16.0%提高到20.1%,均超过了GPT-4-Turbo。这些提升是在没有直接微调大模型的情况下实现的,突显了该方法的有效性和计算效率。
🎯 应用场景
该研究成果可应用于各种需要对齐人类偏好的大语言模型应用场景,例如对话系统、文本摘要、内容生成等。通过利用小型模型进行弱监督,可以降低大模型对齐的计算成本,并提高其生成质量和安全性。该方法还有助于提升大模型在资源受限环境下的部署能力。
📄 摘要(原文)
Large language models are usually fine-tuned to align with human preferences. However, fine-tuning a large language model can be challenging. In this work, we introduce $\textit{weak-to-strong search}$, framing the alignment of a large language model as a test-time greedy search to maximize the log-probability difference between small tuned and untuned models while sampling from the frozen large model. This method serves both as (1) a compute-efficient model up-scaling strategy that avoids directly tuning the large model and as (2) an instance of weak-to-strong generalization that enhances a strong model with weak test-time guidance. Empirically, we demonstrate the flexibility of weak-to-strong search across different tasks. In controlled-sentiment generation and summarization, we use tuned and untuned $\texttt{gpt2}$s to improve the alignment of large models without additional training. Crucially, in a more difficult instruction-following benchmark, AlpacaEval 2.0, we show that reusing off-the-shelf small models (e.g., $\texttt{zephyr-7b-beta}$ and its untuned version) can improve the length-controlled win rates of both white-box and black-box large models against $\texttt{gpt-4-turbo}$ (e.g., $34.4\% \rightarrow 37.9\%$ for $\texttt{Llama-3-70B-Instruct}$ and $16.0\% \rightarrow 20.1\%$ for $\texttt{gpt-3.5-turbo-instruct}$), despite the small models' low win rates $\approx 10.0\%$.