DGRC: An Effective Fine-tuning Framework for Distractor Generation in Chinese Multi-choice Reading Comprehension
作者: Runfeng Lin, Dacheng Xu, Huijiang Wang, Zebiao Chen, Yating Wang, Shouqiang Liu
分类: cs.CL, cs.AI
发布日期: 2024-05-29
💡 一句话要点
提出DGRC框架,用于提升中文多项选择阅读理解中干扰项生成的质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 干扰项生成 多项选择题 阅读理解 预训练语言模型 多任务学习
📋 核心要点
- 自然问题干扰项生成(NQDG)任务中,预训练语言模型难以生成既合理又符合知识和考试风格的干扰项。
- DGRC框架通过硬链式思考、多任务学习和生成掩码模式,引导模型生成更合理、上下文相关的干扰项。
- 实验结果表明,DGRC框架显著提升了干扰项生成的性能,BLEU值提升超过2.5倍。
📝 摘要(中文)
在评估学习者的知识水平时,多项选择题是一种高效且广泛使用的形式。然而,生成这些问题,特别是合理的干扰项(错误选项),是一个相当大的挑战。通常,干扰项生成可以分为完形填空式干扰项生成(CDG)和自然问题干扰项生成(NQDG)。与CDG相比,利用预训练语言模型(PLM)进行NQDG面临三个主要挑战:(1)PLM通常被训练来生成“正确”的内容,如答案,而很少被训练来生成“合理”的内容,如干扰项;(2)PLM通常难以生成与特定知识和考试风格良好对齐的内容;(3)NQDG需要模型生成更长、上下文相关且与问题相关的干扰项。在本研究中,我们提出了一个名为DGRC的微调框架,用于从真实的中文多项选择阅读理解考试中生成干扰项。DGRC包括三个主要组成部分:硬链式思考、多任务学习和生成掩码模式。实验结果表明,DGRC显著提高了生成性能,BLEU分数提高了2.5倍以上。
🔬 方法详解
问题定义:论文旨在解决中文多项选择阅读理解中,自然问题干扰项生成(NQDG)任务的难题。现有方法,特别是直接使用预训练语言模型(PLM)的方法,存在以下痛点:PLM更擅长生成正确答案而非合理的干扰项;生成内容难以与特定知识和考试风格对齐;难以生成长文本、上下文相关且与问题相关的干扰项。
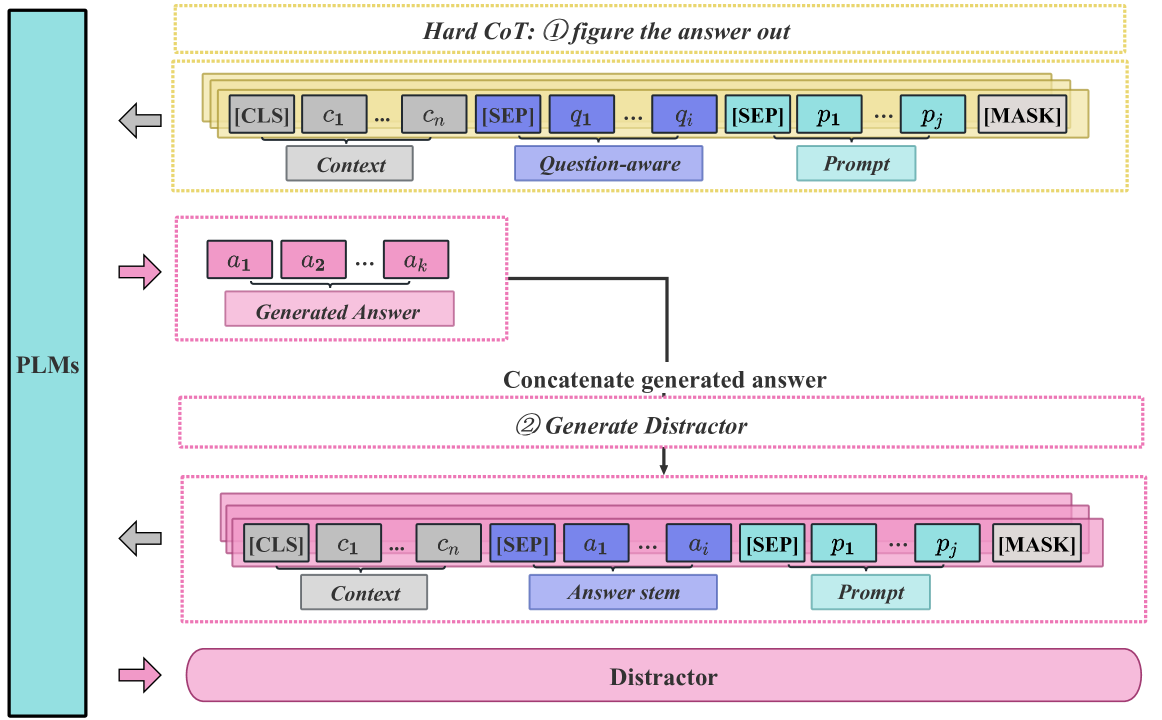
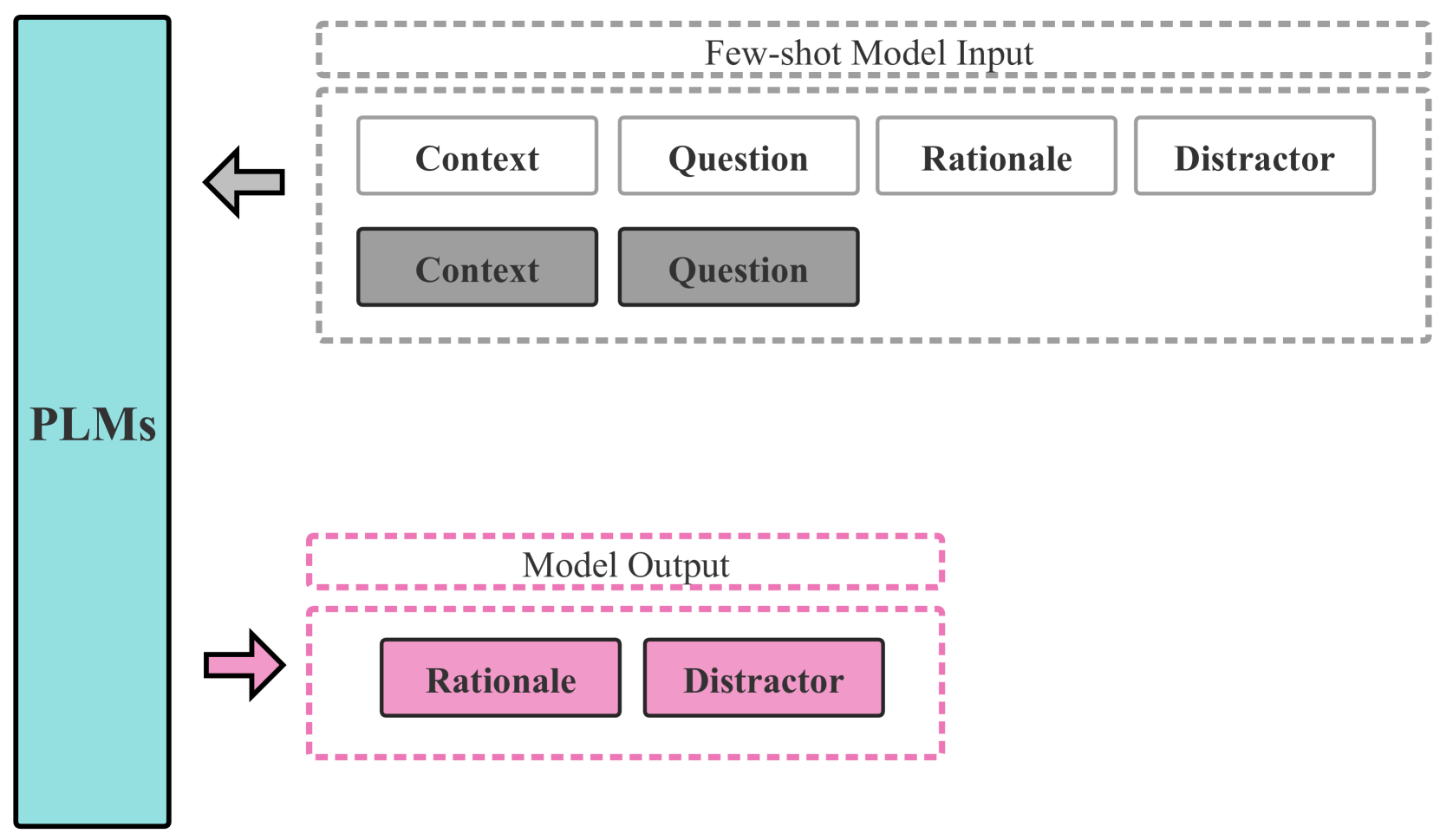
核心思路:论文的核心思路是通过引入硬链式思考(hard chain-of-thought)、多任务学习和生成掩码模式,来引导PLM生成更符合要求的干扰项。硬链式思考模拟了人类思考的过程,帮助模型更好地理解问题和上下文。多任务学习则通过辅助任务来提升模型生成干扰项的能力。生成掩码模式则控制生成过程,使其更符合考试风格。
技术框架:DGRC框架包含三个主要模块:1) 硬链式思考模块:通过prompting的方式,让模型逐步推理生成干扰项的理由。2) 多任务学习模块:除了干扰项生成任务外,还引入了辅助任务,例如问题类型分类、关键词抽取等,以提升模型的泛化能力。3) 生成掩码模式模块:通过预定义的掩码模式,控制生成干扰项的长度、句式结构等,使其更符合考试风格。
关键创新:DGRC的关键创新在于其综合利用了硬链式思考、多任务学习和生成掩码模式,从而有效地解决了PLM在NQDG任务中的固有缺陷。与现有方法相比,DGRC更注重引导模型进行推理和学习,而非仅仅依赖PLM的生成能力。
关键设计:硬链式思考模块使用了特定的prompt模板,引导模型逐步生成干扰项的理由。多任务学习模块中,各个任务的权重需要根据实验结果进行调整。生成掩码模式模块中,掩码模式的设计需要根据具体的考试类型和风格进行调整。损失函数方面,使用了交叉熵损失函数来优化生成结果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DGRC框架在中文多项选择阅读理解的干扰项生成任务中取得了显著的性能提升,BLEU分数提高了2.5倍以上。这表明DGRC框架能够有效地生成更合理、上下文相关且与问题相关的干扰项,优于现有的基于PLM的生成方法。
🎯 应用场景
该研究成果可应用于智能教育领域,例如自动生成高质量的练习题和模拟试题,从而减轻教师的工作负担,并为学生提供更个性化的学习体验。此外,该技术还可以应用于智能客服、问答系统等领域,生成更具迷惑性的错误答案,以评估用户对知识的掌握程度。
📄 摘要(原文)
When evaluating a learner's knowledge proficiency, the multiple-choice question is an efficient and widely used format in standardized tests. Nevertheless, generating these questions, particularly plausible distractors (incorrect options), poses a considerable challenge. Generally, the distractor generation can be classified into cloze-style distractor generation (CDG) and natural questions distractor generation (NQDG). In contrast to the CDG, utilizing pre-trained language models (PLMs) for NQDG presents three primary challenges: (1) PLMs are typically trained to generate
correct'' content, like answers, while rarely trained to generateplausible" content, like distractors; (2) PLMs often struggle to produce content that aligns well with specific knowledge and the style of exams; (3) NQDG necessitates the model to produce longer, context-sensitive, and question-relevant distractors. In this study, we introduce a fine-tuning framework named DGRC for NQDG in Chinese multi-choice reading comprehension from authentic examinations. DGRC comprises three major components: hard chain-of-thought, multi-task learning, and generation mask patterns. The experiment results demonstrate that DGRC significantly enhances generation performance, achieving a more than 2.5-fold improvement in BLEU scores.