Cracking the Code of Juxtaposition: Can AI Models Understand the Humorous Contradictions
作者: Zhe Hu, Tuo Liang, Jing Li, Yiren Lu, Yunlai Zhou, Yiran Qiao, Jing Ma, Yu Yin
分类: cs.CL, cs.CV
发布日期: 2024-05-29 (更新: 2024-10-28)
备注: NeurIPS 2024 (Oral)
💡 一句话要点
提出YesBut基准,评估AI模型理解矛盾叙事漫画幽默的能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 幽默理解 矛盾叙事 多模态学习 视觉语言模型 基准数据集
📋 核心要点
- 现有大型多模态模型难以理解通过并置产生的幽默,尤其是在非线性叙事中。
- 论文提出YesBut基准,包含不同难度的任务,评估AI识别和解释矛盾叙事漫画的能力。
- 实验结果表明,即使是最先进的模型在理解漫画幽默方面仍然落后于人类水平。
📝 摘要(中文)
大型多模态语言模型在各种任务中表现出卓越的能力。然而,这些模型在理解人类通过并置产生的幽默的细微之处方面仍然存在困难,尤其是在涉及构成许多笑话和幽默线索的非线性叙事时。本文通过关注具有矛盾叙事的漫画来研究这一挑战,其中每个漫画由两个面板组成,产生一种幽默的矛盾。我们引入了YesBut基准,该基准包含不同难度的任务,旨在评估AI在识别和解释这些漫画方面的能力,范围从字面内容理解到深度叙事推理。通过对最新的商业或开源大型(视觉)语言模型进行广泛的实验和分析,我们评估了它们理解这些漫画中固有的叙事幽默的复杂相互作用的能力。我们的结果表明,即使是最先进的模型在这项任务上的表现仍然落后于人类。我们的发现为AI在理解人类创造性表达方面的当前局限性和潜在改进提供了见解。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型难以理解人类幽默,特别是通过矛盾叙事(如漫画)表达的幽默这一问题。现有方法在处理非线性叙事和理解深层语义关联方面存在不足,导致无法准确识别和解释幽默。
核心思路:论文的核心思路是构建一个专门用于评估AI模型理解矛盾叙事幽默能力的基准数据集YesBut。通过设计不同难度的任务,从字面理解到深层推理,逐步考察模型对漫画中幽默元素的捕捉能力。这种方法旨在揭示现有模型在理解人类创造性表达方面的局限性。
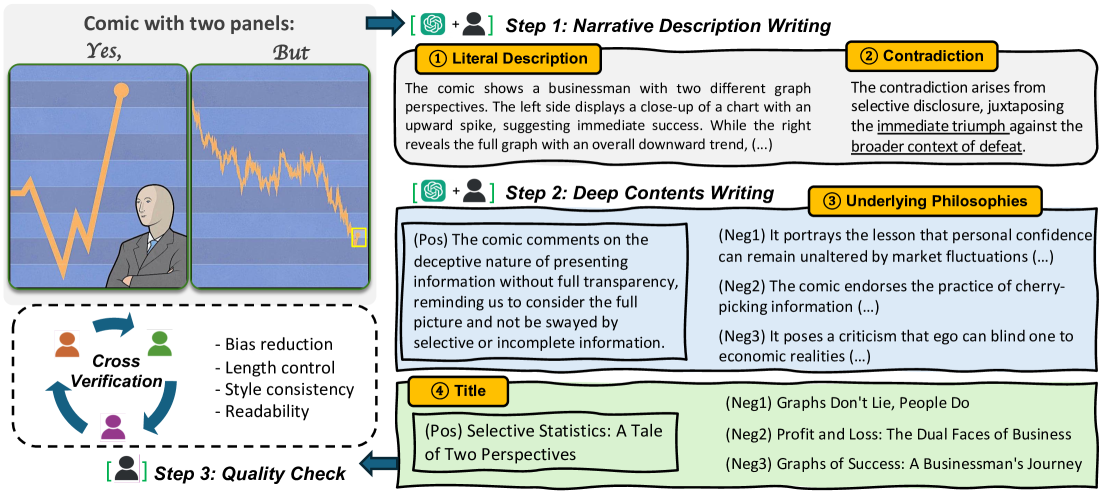
技术框架:YesBut基准包含一系列任务,这些任务围绕着由两个面板组成的矛盾叙事漫画展开。任务难度递增,包括:1) 字面内容理解:要求模型理解每个面板的文字和图像内容;2) 叙事关系识别:要求模型识别两个面板之间的叙事关系,例如因果、对比等;3) 幽默识别:要求模型判断漫画是否具有幽默感;4) 幽默解释:要求模型解释漫画的幽默之处。通过这些任务,全面评估模型对漫画幽默的理解能力。
关键创新:该论文的关键创新在于构建了一个专门针对矛盾叙事幽默理解的基准数据集YesBut。与以往的幽默理解研究不同,YesBut侧重于视觉和文本信息的结合,以及对非线性叙事的理解。此外,YesBut的任务设计由浅入深,能够更精细地评估模型的幽默理解能力。
关键设计:YesBut基准中的漫画选择和任务设计都经过精心考虑。漫画的选择需要保证具有一定的幽默感,并且叙事具有矛盾性。任务的设计需要覆盖不同的幽默理解层次,从字面理解到深层推理。此外,为了保证评估的公平性,YesBut还提供了详细的评估指标和基线模型。
🖼️ 关键图片

📊 实验亮点
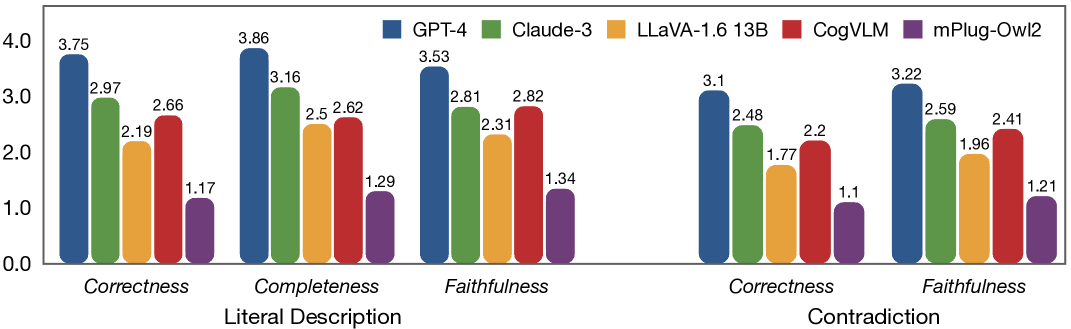
实验结果表明,即使是最先进的大型(视觉)语言模型在YesBut基准上的表现仍然显著低于人类水平。具体而言,模型在幽默识别和幽默解释等需要深层推理的任务上表现较差。这些结果表明,现有模型在理解人类创造性表达方面仍然存在很大的提升空间,尤其是在处理非线性叙事和矛盾信息时。
🎯 应用场景
该研究成果可应用于提升AI模型在人机交互中的情感理解能力,例如在智能客服、虚拟助手等领域,使AI能够更好地理解用户的幽默和情感表达,从而提供更自然、更人性化的服务。此外,该研究也有助于推动AI在创意内容生成方面的应用,例如自动生成幽默漫画或段子。
📄 摘要(原文)
Recent advancements in large multimodal language models have demonstrated remarkable proficiency across a wide range of tasks. Yet, these models still struggle with understanding the nuances of human humor through juxtaposition, particularly when it involves nonlinear narratives that underpin many jokes and humor cues. This paper investigates this challenge by focusing on comics with contradictory narratives, where each comic consists of two panels that create a humorous contradiction. We introduce the YesBut benchmark, which comprises tasks of varying difficulty aimed at assessing AI's capabilities in recognizing and interpreting these comics, ranging from literal content comprehension to deep narrative reasoning. Through extensive experimentation and analysis of recent commercial or open-sourced large (vision) language models, we assess their capability to comprehend the complex interplay of the narrative humor inherent in these comics. Our results show that even state-of-the-art models still lag behind human performance on this task. Our findings offer insights into the current limitations and potential improvements for AI in understanding human creative expressions.