Reverse Image Retrieval Cues Parametric Memory in Multimodal LLMs
作者: Jialiang Xu, Michael Moor, Jure Leskovec
分类: cs.CL
发布日期: 2024-05-29
💡 一句话要点
利用反向图像检索提示增强多模态LLM的参数记忆,提升知识密集型任务性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 反向图像检索 知识增强 视觉问答 提示学习
📋 核心要点
- 现有MLLM在知识密集型任务中表现不足,无法充分利用自身参数中存储的知识。
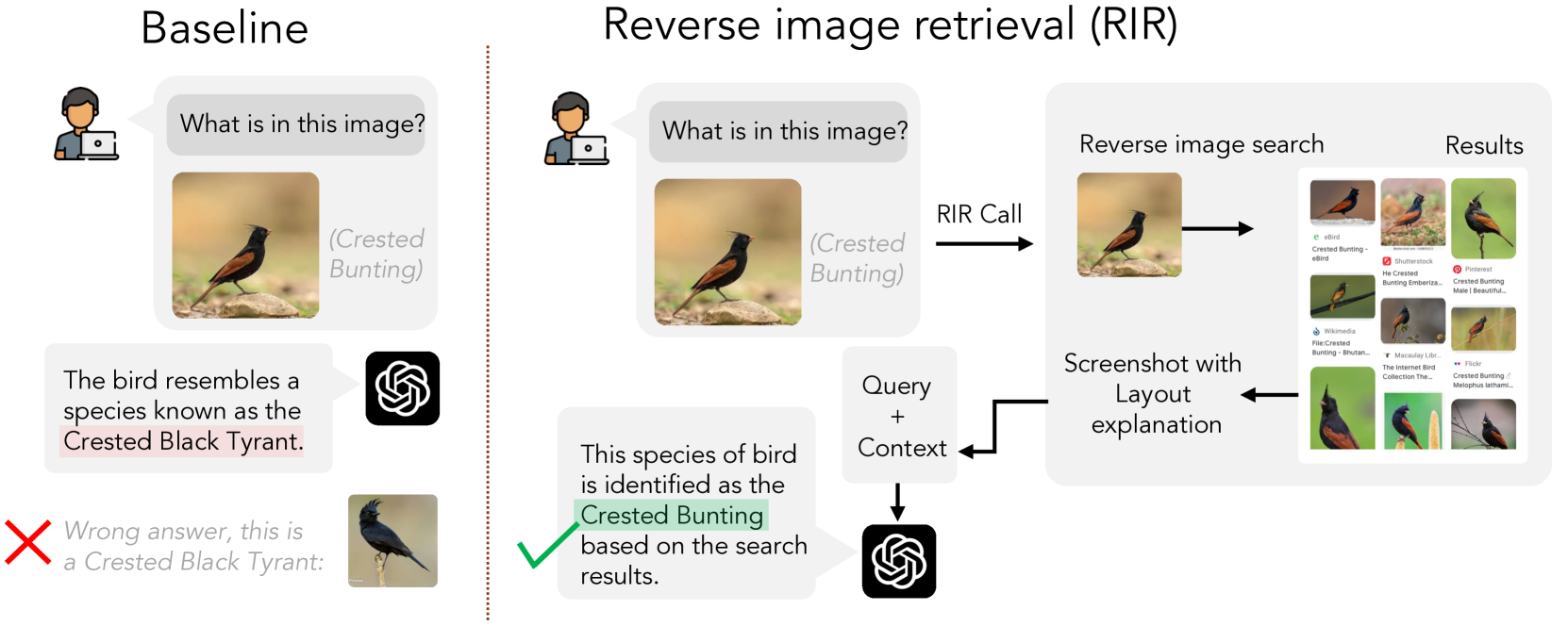
- 提出反向图像检索(RIR)增强生成,通过检索相关图像及其文本描述来补充MLLM的输入。
- 实验表明,RIR显著提升了GPT-4系列模型在视觉问答任务中的性能,最高提升达43%。
📝 摘要(中文)
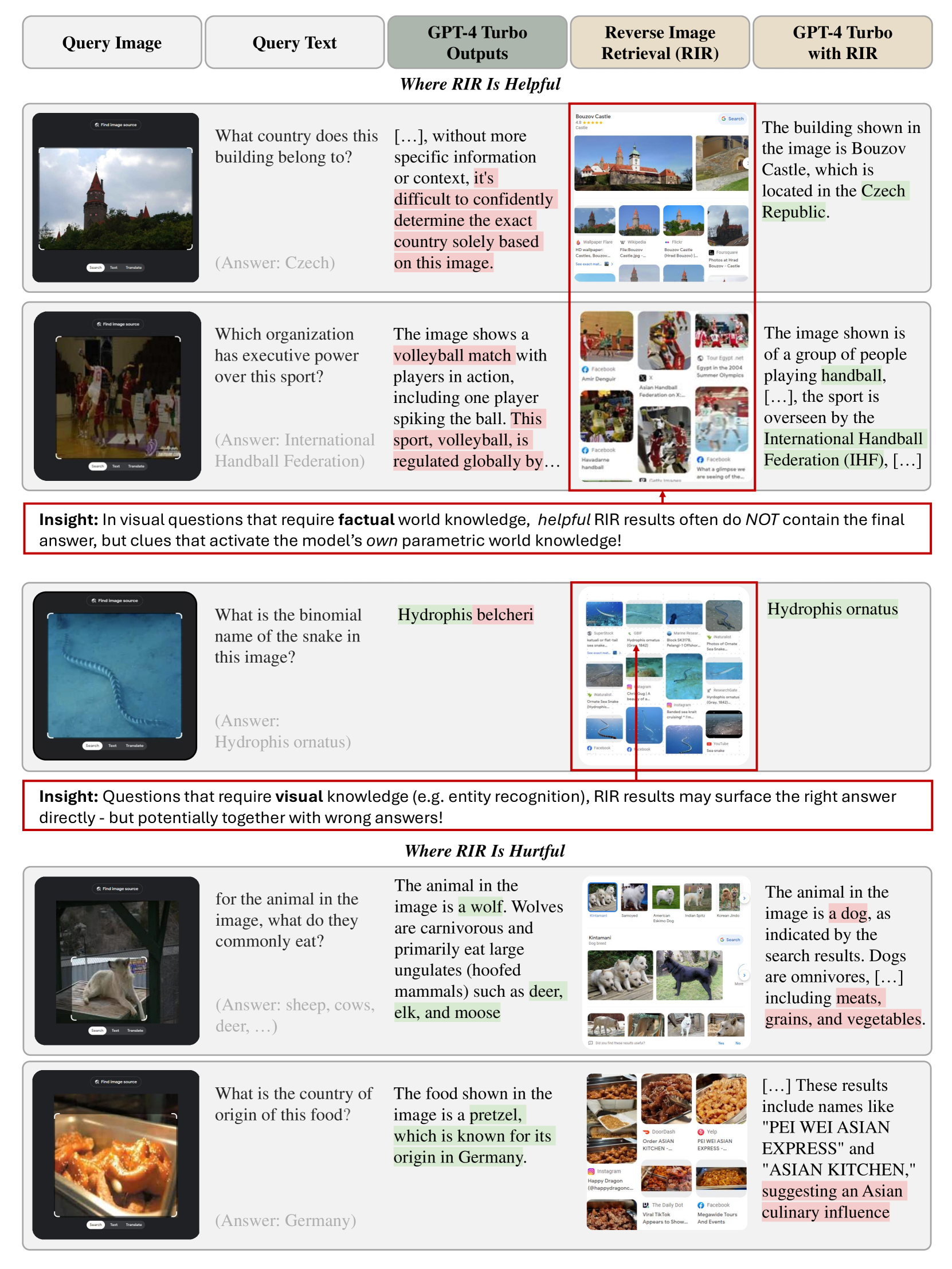
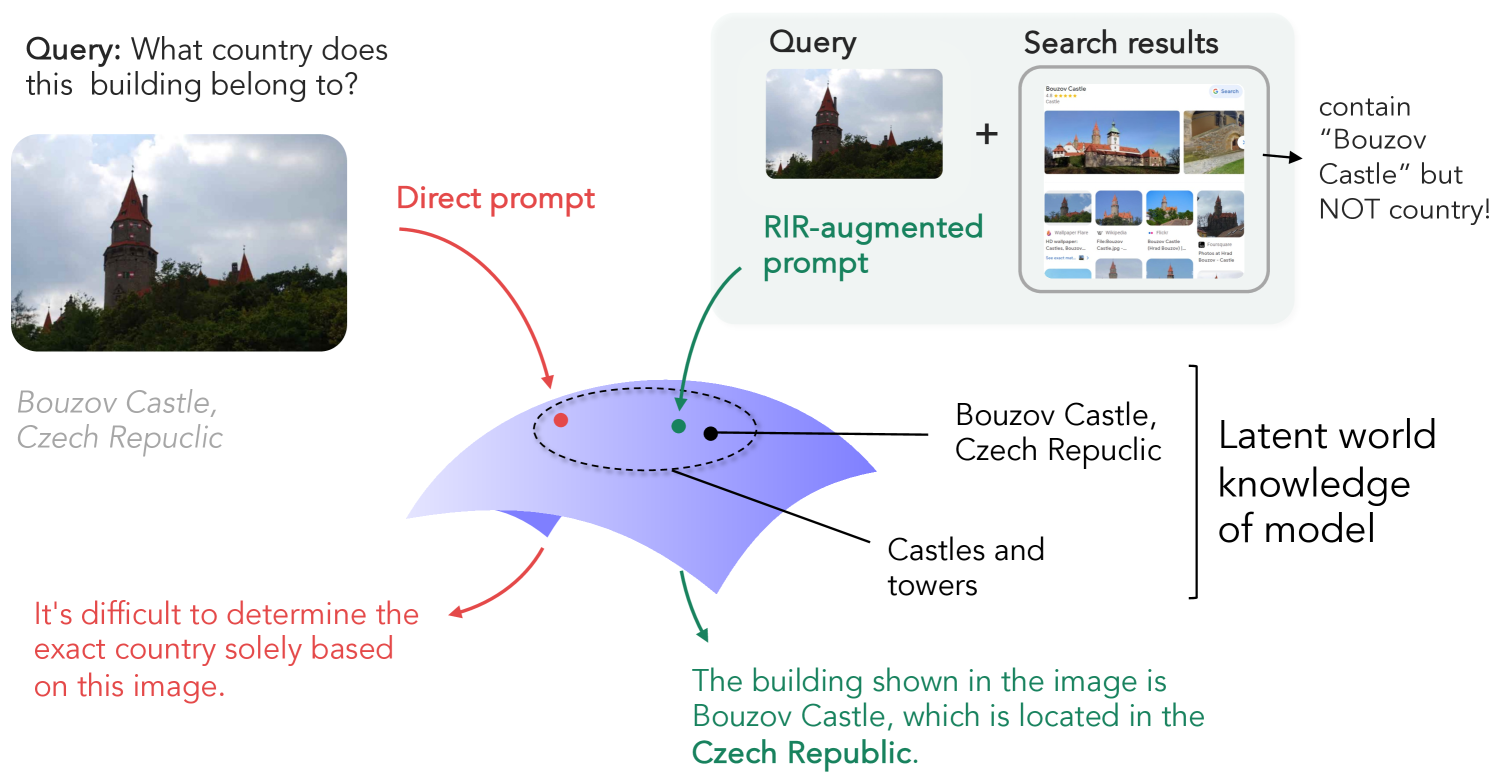
尽管多模态大型语言模型(MLLM)取得了显著进展,但GPT-4系列等最先进的模型在知识密集型任务中仍然面临挑战。为了解决这个问题,我们考虑了反向图像检索(RIR)增强生成,这是一种简单而有效的策略,可以使用网络规模的反向图像搜索结果来增强MLLM。RIR在开放式VQA评估指标方面,显著提高了GPT-4V(37-43%)、GPT-4 Turbo(25-27%)和GPT-4o(18-20%)的知识密集型视觉问答(VQA)性能。令人惊讶的是,我们发现RIR有助于模型更好地访问其自身的先验知识。具体而言,我们的实验表明,RIR增强通过提供进一步的视觉和文本提示来发挥作用,而无需包含查询的直接答案。此外,我们阐明了RIR可能损害性能的情况,并进行了人工评估。最后,我们发现使用RIR的总体优势使得一个可以选择使用RIR的智能体,难以胜过默认设置RIR的方法。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLM)在处理知识密集型视觉问答(VQA)任务时,虽然具备一定的世界知识,但无法有效利用这些知识。模型可能缺乏必要的视觉或文本提示来激活和检索相关信息,导致回答不准确或不完整。现有方法难以充分利用模型自身参数中蕴含的知识。
核心思路:论文的核心思路是通过反向图像检索(RIR)来增强MLLM的输入。具体来说,对于给定的图像和问题,首先使用图像搜索引擎检索与该图像相关的图像和文本描述。然后,将检索到的信息作为额外的上下文输入到MLLM中,帮助模型更好地理解问题并检索相关知识。这种方法的核心在于,即使检索到的图像和文本不包含直接答案,它们也可以提供额外的视觉和文本提示,从而激活模型自身的知识。
技术框架:整体框架包括以下几个主要步骤:1) 输入图像和问题;2) 使用图像搜索引擎(例如Google Images)执行反向图像检索,获取Top-K个相关图像和对应的文本描述;3) 将原始图像、问题以及检索到的图像和文本描述拼接成一个统一的输入;4) 将拼接后的输入送入MLLM(例如GPT-4V)进行推理,得到最终答案。
关键创新:该方法最重要的创新点在于利用外部知识源(反向图像检索)来增强MLLM的内部知识。与传统的知识增强方法不同,RIR并不直接将知识注入到模型中,而是通过提供额外的上下文提示来帮助模型更好地利用自身已有的知识。此外,该方法简单有效,易于实现,并且可以应用于各种MLLM。
关键设计:关键设计包括:1) 选择合适的图像搜索引擎和检索策略;2) 如何有效地将检索到的图像和文本描述与原始输入进行拼接;3) 如何控制检索结果的数量(Top-K)以避免引入噪声;4) 如何设计合适的提示语(prompt)来引导MLLM利用检索到的信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RIR能够显著提升GPT-4V、GPT-4 Turbo和GPT-4o在知识密集型VQA任务中的性能。具体而言,RIR将GPT-4V的性能提高了37-43%,GPT-4 Turbo的性能提高了25-27%,GPT-4o的性能提高了18-20%。这些结果表明,RIR是一种简单而有效的知识增强方法,可以显著提高MLLM在知识密集型任务中的性能。
🎯 应用场景
该研究成果可广泛应用于需要知识密集型视觉理解的场景,例如智能客服、图像搜索、教育辅助、医疗诊断等。通过RIR增强,MLLM能够更准确地理解图像内容并回答相关问题,从而提高用户体验和工作效率。未来,该方法可以进一步扩展到其他模态的数据,例如视频和音频,以实现更强大的多模态知识增强。
📄 摘要(原文)
Despite impressive advances in recent multimodal large language models (MLLMs), state-of-the-art models such as from the GPT-4 suite still struggle with knowledge-intensive tasks. To address this, we consider Reverse Image Retrieval (RIR) augmented generation, a simple yet effective strategy to augment MLLMs with web-scale reverse image search results. RIR robustly improves knowledge-intensive visual question answering (VQA) of GPT-4V by 37-43%, GPT-4 Turbo by 25-27%, and GPT-4o by 18-20% in terms of open-ended VQA evaluation metrics. To our surprise, we discover that RIR helps the model to better access its own world knowledge. Concretely, our experiments suggest that RIR augmentation helps by providing further visual and textual cues without necessarily containing the direct answer to a query. In addition, we elucidate cases in which RIR can hurt performance and conduct a human evaluation. Finally, we find that the overall advantage of using RIR makes it difficult for an agent that can choose to use RIR to perform better than an approach where RIR is the default setting.