Are PPO-ed Language Models Hackable?
作者: Suraj Anand, David Getzen
分类: cs.CL, cs.CR, cs.LG
发布日期: 2024-05-28
备注: 8 pages, 4 figures
💡 一句话要点
研究PPO对齐的语言模型是否易受攻击,并探索对抗方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型对齐 近端策略优化 机制可解释性 情感控制 模型攻击
📋 核心要点
- 大型语言模型对齐面临挑战,奖励函数设计不当易导致模型产生不良行为,如生成负面情感文本。
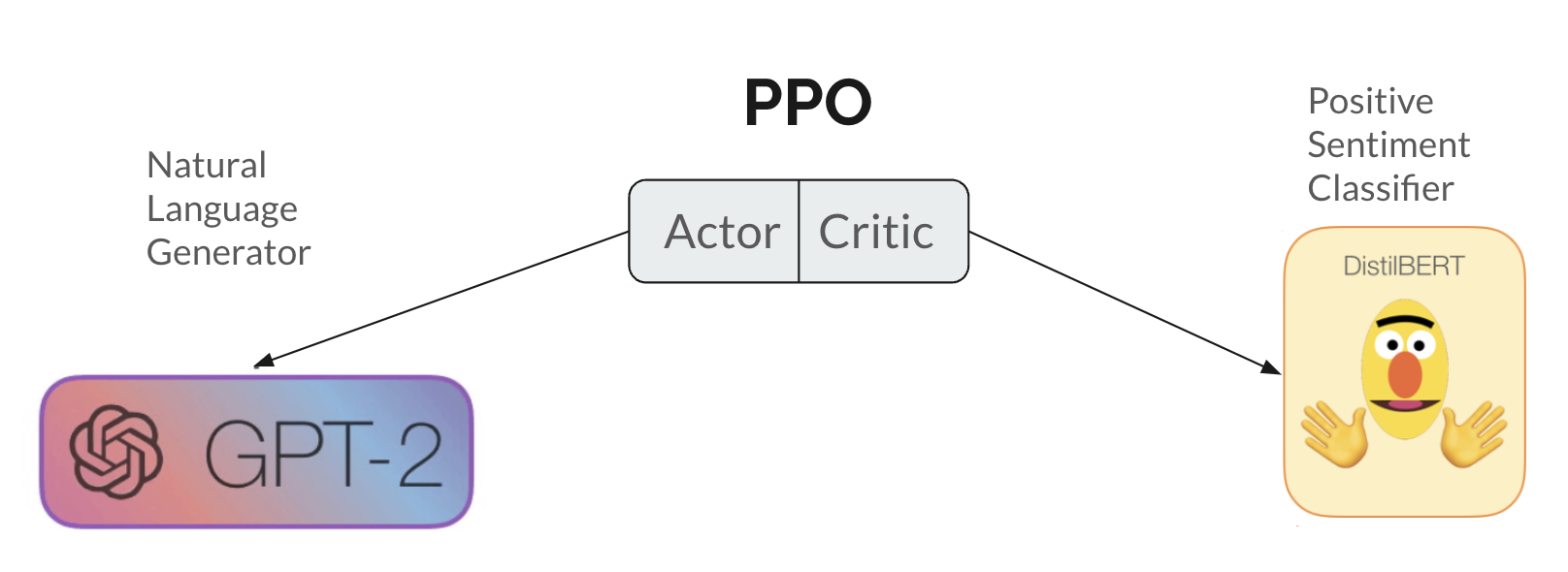
- 本文通过静态情感分类器作为奖励,研究PPO训练后的GPT-2模型在情感生成任务中的可攻击性。
- 通过机制可解释性分析,尝试攻击PPO模型生成负面情感,并修改奖励函数以改变负面权重。
📝 摘要(中文)
本文旨在研究通过近端策略优化(PPO)对齐的语言模型是否容易受到攻击,使其产生不良行为。由于大状态空间和设计合适的奖励函数的挑战,语言模型常常存在各种“越狱”现象。本文在一个受控的环境下,即积极情感语言生成,来检验奖励函数的影响。与基于人类反馈在线训练奖励模型不同,本文采用静态学习的情感分类器。同时,本文还考虑了模型权重和激活在训练后暴露给最终用户的情况。通过机制可解释性的视角,本文在应用PPO促进积极情感响应前后,对预训练的GPT-2模型进行了分析。基于这些分析,本文(1)尝试“攻击”经过PPO训练的模型,使其生成负面情感响应;(2)在奖励函数中添加一个项,试图改变“负面”权重。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法,例如使用PPO进行微调,旨在消除不良行为,但由于状态空间巨大和奖励函数设计的困难,模型仍然容易受到攻击,产生不希望的输出。本文关注的是情感控制任务,即如何防止模型生成负面情感的文本。
核心思路:本文的核心思路是通过可解释性分析理解PPO训练后的模型行为,然后利用这些理解来攻击模型,使其生成负面情感的文本。同时,尝试修改奖励函数,以直接影响模型中负责生成负面情感的部分。
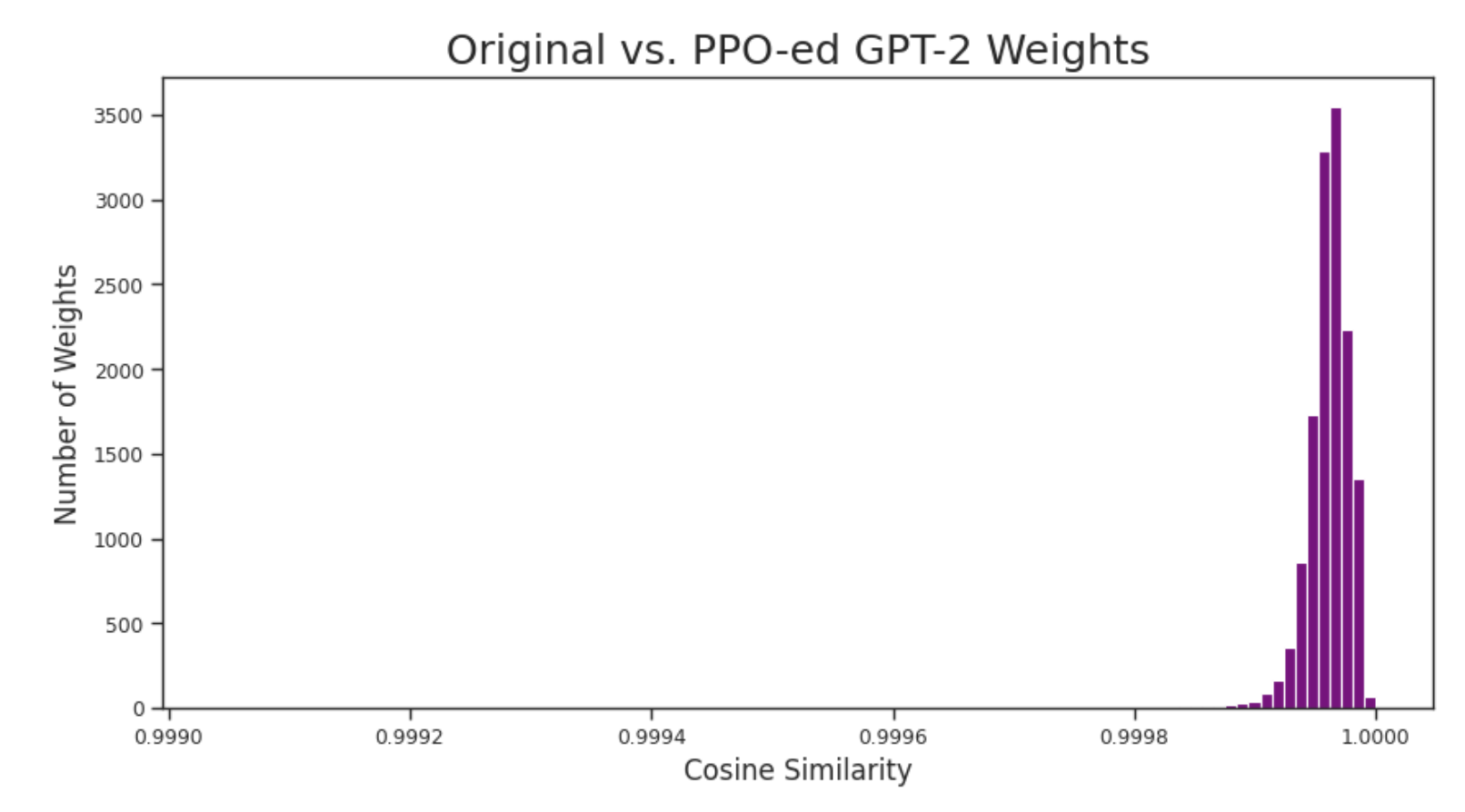
技术框架:本文的技术框架主要包括以下几个步骤:1) 使用预训练的GPT-2模型;2) 使用静态学习的情感分类器作为奖励函数,通过PPO对GPT-2进行微调,使其生成积极情感的文本;3) 使用机制可解释性方法分析PPO训练前后模型的行为变化;4) 基于可解释性分析的结果,设计攻击方法,尝试使模型生成负面情感的文本;5) 修改奖励函数,尝试直接改变模型中的负面权重。
关键创新:本文的关键创新在于将机制可解释性方法应用于分析PPO训练后的语言模型,并利用分析结果来设计攻击方法和修改奖励函数。这提供了一种理解和控制对齐语言模型的新视角。与传统的黑盒攻击方法不同,本文尝试理解模型内部的机制,并有针对性地进行攻击和防御。
关键设计:本文的关键设计包括:1) 使用静态情感分类器作为奖励函数,避免了在线训练奖励模型的复杂性;2) 使用机制可解释性方法,例如激活分析和权重分析,来理解模型内部的行为;3) 设计了特定的攻击方法,例如修改输入文本,以触发模型生成负面情感的文本;4) 在奖励函数中添加了一个额外的项,用于惩罚模型中的负面权重。
🖼️ 关键图片
📊 实验亮点
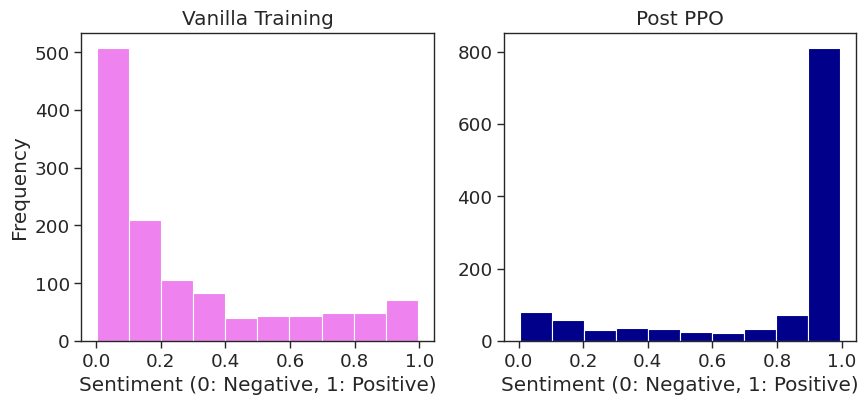
本文通过可解释性分析,成功地攻击了经过PPO训练的GPT-2模型,使其生成负面情感的文本。同时,通过修改奖励函数,初步探索了直接影响模型内部负面权重的方法。这些结果表明,即使经过对齐训练,语言模型仍然可能存在安全漏洞,需要进一步研究。
🎯 应用场景
该研究成果可应用于提升语言模型安全性,防止其生成有害或不当内容。通过理解和控制模型的内部机制,可以设计更有效的对齐方法,减少模型被攻击的风险。此外,该研究也为开发更可靠、更值得信赖的AI系统提供了新的思路。
📄 摘要(原文)
Numerous algorithms have been proposed to $\textit{align}$ language models to remove undesirable behaviors. However, the challenges associated with a very large state space and creating a proper reward function often result in various jailbreaks. Our paper aims to examine this effect of reward in the controlled setting of positive sentiment language generation. Instead of online training of a reward model based on human feedback, we employ a statically learned sentiment classifier. We also consider a setting where our model's weights and activations are exposed to an end-user after training. We examine a pretrained GPT-2 through the lens of mechanistic interpretability before and after proximal policy optimization (PPO) has been applied to promote positive sentiment responses. Using these insights, we (1) attempt to "hack" the PPO-ed model to generate negative sentiment responses and (2) add a term to the reward function to try and alter `negative' weights.