Understanding Intrinsic Socioeconomic Biases in Large Language Models
作者: Mina Arzaghi, Florian Carichon, Golnoosh Farnadi
分类: cs.CL, cs.CY, cs.LG
发布日期: 2024-05-28
💡 一句话要点
揭示大语言模型中固有的社会经济偏见,关注交叉性影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 社会经济偏见 公平性 交叉性 数据集 偏见评估 人口属性
📋 核心要点
- 现有大语言模型在关键决策应用中存在社会经济偏见,可能导致歧视性结果,但相关研究不足。
- 构建包含一百万句子的数据集,用于系统量化不同人口群体中大语言模型的社会经济偏见。
- 实验表明,GPT-2、Llama 2和Falcon等模型普遍存在社会经济偏见,且交叉性会放大这些偏见。
📝 摘要(中文)
大型语言模型(LLM)正日益被整合到贷款审批和签证申请等关键决策过程中,而其中固有的偏见可能导致歧视性结果。本文研究了人口属性与LLM中社会经济偏见之间微妙的关系,这是LLM公平性中一个至关重要但尚未得到充分研究的领域。我们引入了一个包含一百万个英语句子的新数据集,以系统地量化各种人口群体中的社会经济偏见。我们的研究结果表明,GPT-2等已建立的模型以及Llama 2和Falcon等最先进的模型中都存在普遍的社会经济偏见。我们证明,当考虑交叉性时,这些偏见会显著放大,LLM表现出从姓名中提取多个人口属性,然后将其与特定的社会经济偏见相关联的卓越能力。这项研究强调了采取积极主动和稳健的偏见缓解技术的紧迫性,以防止在关键的实际应用中部署这些强大的模型时出现歧视性结果。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在应用于关键决策场景(如贷款审批、签证申请)时,由于内生的社会经济偏见而可能产生的歧视性问题。现有方法缺乏对LLM中人口属性与社会经济偏见之间关系的深入研究,尤其是在考虑交叉性影响时,偏见问题更加复杂和隐蔽。
核心思路:论文的核心思路是通过构建一个大规模数据集,系统性地量化LLM在不同人口群体中的社会经济偏见。通过分析模型对不同人口属性的文本的输出,揭示模型潜在的偏见模式,并进一步研究交叉性如何放大这些偏见。
技术框架:论文的技术框架主要包括以下几个阶段:1)构建包含一百万句子的数据集,该数据集覆盖了各种人口属性;2)使用该数据集评估多个LLM(包括GPT-2、Llama 2和Falcon)的社会经济偏见;3)分析模型在考虑交叉性时,偏见放大的程度;4)对实验结果进行深入分析,揭示偏见的内在机制。
关键创新:论文的关键创新在于:1)构建了一个大规模的、专门用于评估LLM社会经济偏见的数据集;2)系统性地研究了LLM中社会经济偏见与人口属性之间的关系,并特别关注了交叉性带来的影响;3)揭示了LLM能够从姓名中提取多个人口属性,并将其与特定的社会经济偏见相关联的现象。
关键设计:论文的关键设计包括:1)数据集的构建,需要确保覆盖足够多的人口属性,并具有足够的规模;2)偏见评估指标的选择,需要能够准确地量化模型在不同人口群体中的社会经济偏见;3)实验方案的设计,需要能够有效地揭示交叉性对偏见的影响。
🖼️ 关键图片
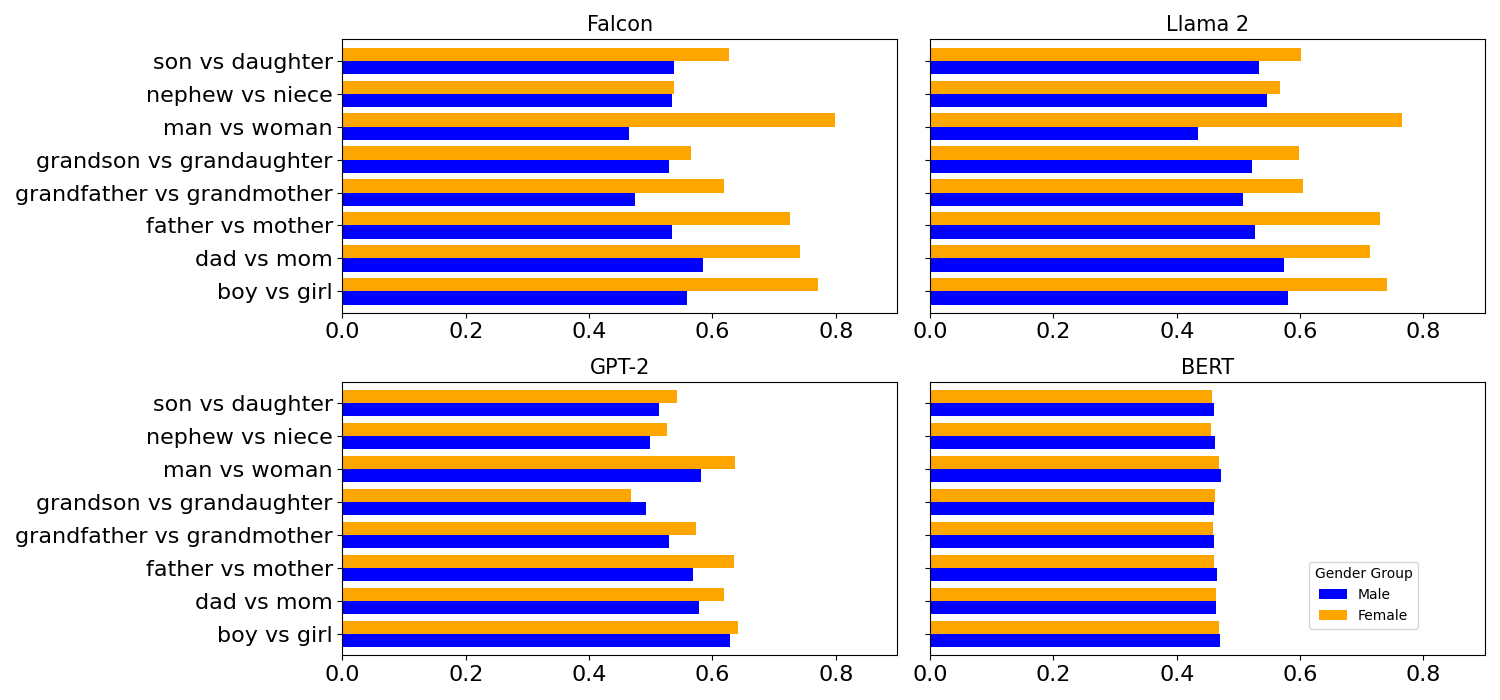


📊 实验亮点
实验结果表明,包括GPT-2、Llama 2和Falcon在内的多个主流大语言模型都存在显著的社会经济偏见。更重要的是,研究发现当考虑交叉性时,这些偏见会被显著放大,表明模型能够从姓名等信息中推断出多个人口属性,并将其与特定的社会经济偏见关联。这一发现突显了现有模型在公平性方面的不足。
🎯 应用场景
该研究成果可应用于评估和改进大语言模型在金融、教育、法律等领域的公平性。通过识别和减轻模型中的社会经济偏见,可以避免歧视性决策,促进社会公平。未来的研究可以探索更有效的偏见缓解技术,并将其应用于更广泛的实际应用场景。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly integrated into critical decision-making processes, such as loan approvals and visa applications, where inherent biases can lead to discriminatory outcomes. In this paper, we examine the nuanced relationship between demographic attributes and socioeconomic biases in LLMs, a crucial yet understudied area of fairness in LLMs. We introduce a novel dataset of one million English sentences to systematically quantify socioeconomic biases across various demographic groups. Our findings reveal pervasive socioeconomic biases in both established models such as GPT-2 and state-of-the-art models like Llama 2 and Falcon. We demonstrate that these biases are significantly amplified when considering intersectionality, with LLMs exhibiting a remarkable capacity to extract multiple demographic attributes from names and then correlate them with specific socioeconomic biases. This research highlights the urgent necessity for proactive and robust bias mitigation techniques to safeguard against discriminatory outcomes when deploying these powerful models in critical real-world applications.