Recent Advances of Foundation Language Models-based Continual Learning: A Survey
作者: Yutao Yang, Jie Zhou, Xuanwen Ding, Tianyu Huai, Shunyu Liu, Qin Chen, Yuan Xie, Liang He
分类: cs.CL
发布日期: 2024-05-28 (更新: 2024-11-29)
备注: Accepted by ACM Computing Survey
💡 一句话要点
综述:基于大语言模型的持续学习研究进展与方法分类
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 大型语言模型 预训练语言模型 灾难性遗忘 迁移学习
📋 核心要点
- 现有预训练语言模型在持续学习中面临灾难性遗忘问题,无法有效适应新任务并保留旧知识。
- 本综述旨在系统地整理和分类现有的基于持续学习的语言模型改进方法,弥补了该领域缺乏系统性研究的空白。
- 文章将持续学习方法分为离线和在线两大类,并详细分析了各类方法在不同任务边界设置下的表现。
📝 摘要(中文)
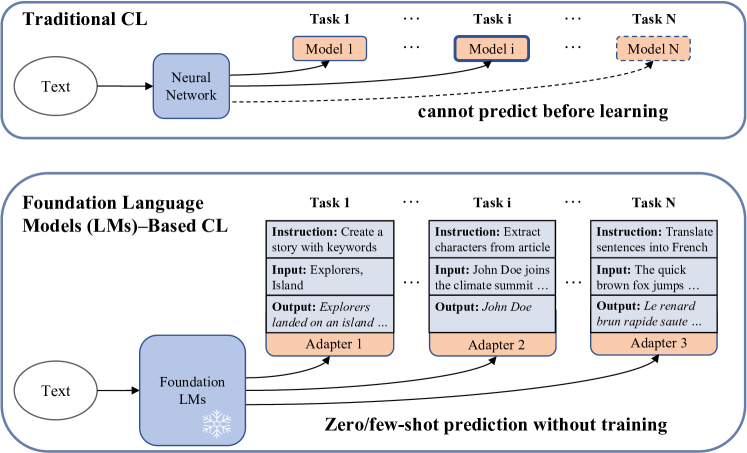
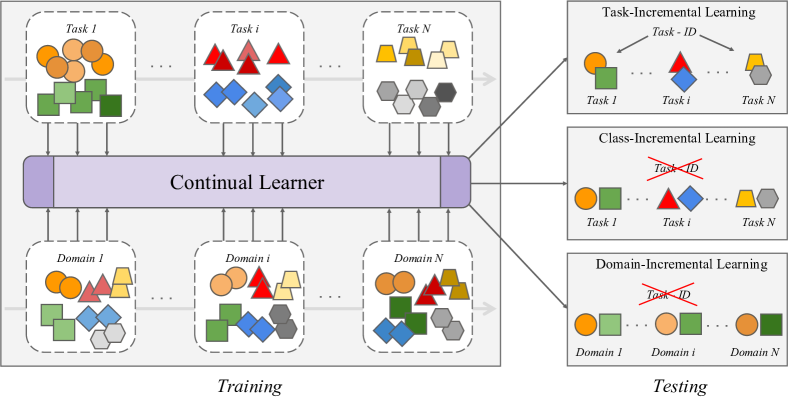
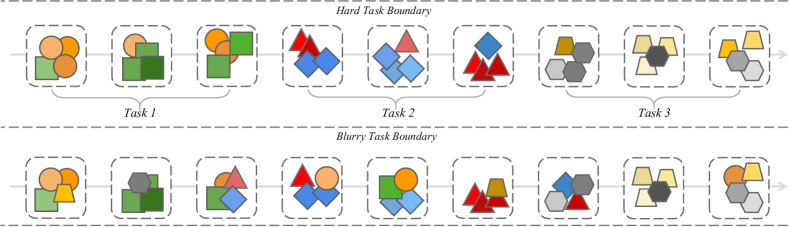
近年来,预训练语言模型(LMs)在自然语言处理(NLP)和计算机视觉(CV)领域取得了显著成就。与传统神经网络模型不同,LMs通过在大量无监督数据集上进行预训练,并拥有庞大的参数量,获得了强大的迁移学习能力,从而获取了丰富的常识知识。然而,由于灾难性遗忘的存在,它们仍然无法模拟人类的持续学习能力。因此,人们开发了各种基于持续学习(CL)的方法来改进LMs,使其能够在适应新任务的同时不忘记先前的知识。然而,目前仍然缺乏对现有方法的系统分类和性能比较,这正是本综述旨在填补的空白。我们深入研究、总结和分类了现有关于应用于LMs(如预训练语言模型(PLMs)、大型语言模型(LLMs)和视觉语言模型(VLMs))的基于CL方法的相关文献。我们将这些研究分为离线CL和在线CL,其中离线CL包括领域增量学习、任务增量学习和类别增量学习,而在线CL又细分为硬任务边界和模糊任务边界设置。此外,我们概述了CL研究中使用的典型数据集和指标,并详细分析了基于LMs的持续学习所面临的挑战和未来工作。
🔬 方法详解
问题定义:论文旨在解决预训练语言模型(PLMs)、大型语言模型(LLMs)和视觉语言模型(VLMs)在持续学习过程中遇到的灾难性遗忘问题。现有方法要么无法有效保留先前学习的知识,要么在新任务上的适应性较差,难以实现真正的持续学习。
核心思路:论文的核心思路是对现有基于持续学习的语言模型改进方法进行系统性的分类、总结和比较,从而为研究人员提供一个全面的视角,了解不同方法的优缺点和适用场景。通过对离线和在线持续学习方法的细致划分,揭示了不同任务边界设置下方法的性能差异。
技术框架:论文将现有方法分为两大类:离线持续学习和在线持续学习。离线持续学习进一步细分为领域增量学习、任务增量学习和类别增量学习。在线持续学习则根据任务边界的清晰程度分为硬任务边界和模糊任务边界两种设置。针对每种分类,论文都详细介绍了相关方法,并分析了其优缺点。
关键创新:论文的主要创新在于对现有基于持续学习的语言模型改进方法进行了系统性的分类和总结,并针对不同的持续学习场景(离线 vs. 在线,硬任务边界 vs. 模糊任务边界)进行了细致的分析。这种分类方法有助于研究人员更好地理解不同方法的适用性和局限性。
关键设计:论文并没有提出新的算法或模型,而是侧重于对现有方法的梳理和分析。关键的设计在于其分类框架,该框架能够清晰地展示不同方法之间的关系和差异。论文还详细介绍了CL研究中常用的数据集和评价指标,为后续研究提供了参考。
🖼️ 关键图片
📊 实验亮点
该综述系统地整理了基于大语言模型的持续学习方法,并根据离线/在线学习以及任务边界的清晰程度进行了细致的分类。通过对各类方法的优缺点进行分析,为研究人员提供了有价值的参考,有助于他们选择合适的持续学习策略来解决实际问题。该综述还总结了常用的数据集和评价指标,为后续研究提供了便利。
🎯 应用场景
该综述的研究成果可以应用于各种需要持续学习能力的自然语言处理和计算机视觉任务中,例如智能客服、机器翻译、自动驾驶等。通过选择合适的持续学习方法,可以使模型在不断学习新知识的同时,保持对先前知识的掌握,从而提高模型的泛化能力和鲁棒性。未来的影响在于推动开发更接近人类学习方式的AI系统。
📄 摘要(原文)
Recently, foundation language models (LMs) have marked significant achievements in the domains of natural language processing (NLP) and computer vision (CV). Unlike traditional neural network models, foundation LMs obtain a great ability for transfer learning by acquiring rich commonsense knowledge through pre-training on extensive unsupervised datasets with a vast number of parameters. However, they still can not emulate human-like continuous learning due to catastrophic forgetting. Consequently, various continual learning (CL)-based methodologies have been developed to refine LMs, enabling them to adapt to new tasks without forgetting previous knowledge. However, a systematic taxonomy of existing approaches and a comparison of their performance are still lacking, which is the gap that our survey aims to fill. We delve into a comprehensive review, summarization, and classification of the existing literature on CL-based approaches applied to foundation language models, such as pre-trained language models (PLMs), large language models (LLMs) and vision-language models (VLMs). We divide these studies into offline CL and online CL, which consist of traditional methods, parameter-efficient-based methods, instruction tuning-based methods and continual pre-training methods. Offline CL encompasses domain-incremental learning, task-incremental learning, and class-incremental learning, while online CL is subdivided into hard task boundary and blurry task boundary settings. Additionally, we outline the typical datasets and metrics employed in CL research and provide a detailed analysis of the challenges and future work for LMs-based continual learning.