Semantic are Beacons: A Semantic Perspective for Unveiling Parameter-Efficient Fine-Tuning in Knowledge Learning
作者: Renzhi Wang, Piji Li
分类: cs.CL
发布日期: 2024-05-28
备注: Accepted at Findings of ACL 2024
💡 一句话要点
针对知识学习,提出基于语义感知的参数高效微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 知识学习 语义视角 数据过滤 重加权学习
📋 核心要点
- 现有参数高效微调方法在知识学习任务中表现不佳,无法准确学习事实知识。
- 论文从语义角度出发,通过数据过滤和重加权学习,使模型更关注语义距离。
- 实验结果表明,该方法在开源大型语言模型上有效,验证了PEFT在知识学习中的语义挑战。
📝 摘要(中文)
参数高效微调(PEFT)方法能够有效地将大型语言模型(LLM)适应于各种下游应用。然而,当下游任务需要准确学习事实知识时,PEFT的有效性会显著降低。本文采用语义视角来研究这种现象,揭示了PEFT在知识学习任务中存在局限性的原因。研究结果表明:(1) PEFT存在使模型偏离预期知识目标的显著风险;(2) 多重知识相互干扰,这种干扰抑制了知识特征的学习和表达。基于这些见解,我们提出了一种数据过滤策略,以排除不利于知识学习的数据,以及一种重新加权的策略,使模型在知识学习过程中关注语义距离。实验结果表明,该方法在开源大型语言模型上的有效性,进一步验证了PEFT中的语义挑战,从而为未来的研究铺平了道路。
🔬 方法详解
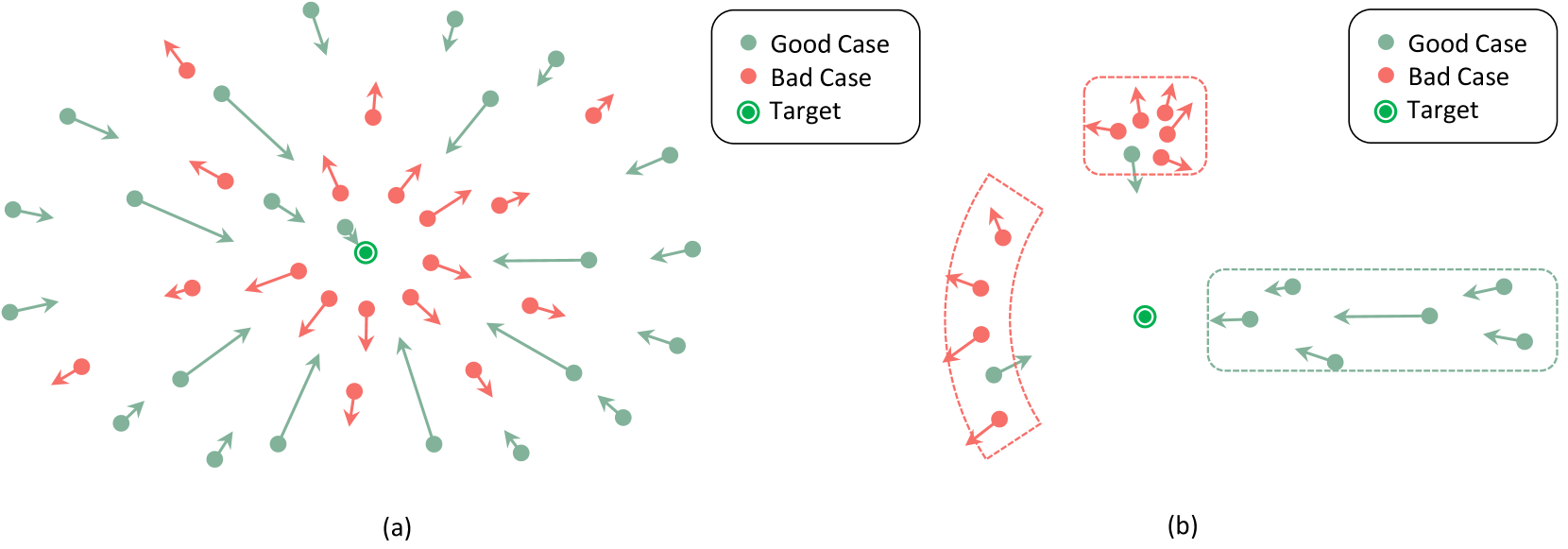
问题定义:论文旨在解决参数高效微调(PEFT)方法在知识学习任务中的不足。现有PEFT方法在需要准确学习事实性知识的下游任务中表现不佳,其痛点在于容易使模型偏离正确的知识目标,并且不同知识之间存在干扰,抑制了知识特征的学习和表达。
核心思路:论文的核心思路是从语义角度出发,通过数据过滤和重加权学习来提升PEFT在知识学习任务中的性能。具体来说,首先过滤掉不利于知识学习的数据,然后通过重加权学习,使模型在学习过程中更加关注语义距离,从而减少知识间的干扰,提高知识学习的准确性。
技术框架:论文提出的方法主要包含两个阶段:数据过滤和重加权学习。数据过滤阶段旨在排除对知识学习有害的数据。重加权学习阶段则通过调整损失函数,使模型在学习过程中更加关注语义距离。整体流程是:首先对训练数据进行过滤,然后使用过滤后的数据进行重加权学习,最后评估模型在知识学习任务上的性能。
关键创新:论文的关键创新在于从语义角度分析了PEFT在知识学习中的局限性,并提出了相应的数据过滤和重加权学习策略。与现有方法不同,该方法不是简单地调整PEFT的参数,而是从数据和学习过程入手,通过语义信息来引导模型的学习,从而更有效地学习知识。
关键设计:数据过滤策略的具体实现未知,论文中提到排除不利于知识学习的数据,但未明确给出具体的过滤规则或算法。重加权学习策略的具体实现也未知,论文中提到使模型在知识学习过程中关注语义距离,但未明确给出如何计算语义距离以及如何将其融入损失函数的细节。这些细节是影响方法性能的关键因素。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在开源大型语言模型上取得了显著的性能提升,验证了其有效性。具体性能数据和对比基线未知,但论文强调该方法能够有效解决PEFT在知识学习中面临的语义挑战,为未来的研究奠定了基础。
🎯 应用场景
该研究成果可应用于各种需要知识学习的自然语言处理任务,例如问答系统、知识图谱构建、信息检索等。通过提升参数高效微调方法在知识学习方面的性能,可以降低模型训练成本,提高模型在实际应用中的准确性和效率,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of Large Language Models (LLMs) to various downstream applications. However, the effectiveness of the PEFT diminishes notably when downstream tasks require accurate learning of factual knowledge. In this paper, we adopt a semantic perspective to investigate this phenomenon, uncovering the reasons behind PEFT's limitations in knowledge learning task. Our findings reveal that: (1) PEFT presents a notable risk of pushing the model away from the intended knowledge target; (2) multiple knowledge interfere with each other, and such interference suppresses the learning and expression of knowledge features. Based on these insights, we introduce a data filtering strategy to exclude data that is detrimental to knowledge learning and a re-weighted learning strategy to make the model attentive to semantic distance during knowledge learning. Experimental results demonstrate the effectiveness of the proposed method on open-source large language model, further validate the semantic challenge in PEFT, thus paving the way for future research.