Aligning to Thousands of Preferences via System Message Generalization
作者: Seongyun Lee, Sue Hyun Park, Seungone Kim, Minjoon Seo
分类: cs.CL
发布日期: 2024-05-28 (更新: 2024-11-05)
备注: Accepted to NeurIPS 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出Janus,通过系统消息泛化实现LLM对用户个性化偏好的对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化对齐 系统消息 偏好学习 价值观 泛化能力 指令遵循
📋 核心要点
- 现有LLM对齐方法难以扩展到个体用户偏好,因为需要为每个用户重复获取偏好数据并训练新的奖励模型和LLM。
- 论文提出通过在系统消息中指定用户价值观来引导LLM生成,使其与用户意图对齐,从而实现个性化偏好对齐。
- 通过Multifaceted Collection数据集训练的Janus模型,在多个基准测试中超越了Mistral 7B、GPT-3.5 Turbo和GPT-4等模型。
📝 摘要(中文)
当前的大型语言模型(LLM)对齐方法通常假设与公众偏好对齐是最优的,但人类的价值观本质上是多样的。针对LLM对齐中个性化方法缺乏可扩展性的问题,本文提出了一种新范式:用户在系统消息中指定其最看重的价值观,从而引导LLM的生成行为,使其更好地与用户意图对齐。为了提高LLM对不同系统消息的泛化能力,本文构建了一个包含19.2万个价值观组合的偏好数据集Multifaceted Collection,涵盖6.5万条用户指令。基于此数据集,训练了一个7B的LLM模型Janus,并在来自5个基准测试(AlpacaEval 2.0、FLASK、Koala、MT-Bench和Self-Instruct)的921个提示上进行了测试,通过添加反映用户偏好的各种未见过的系统消息。实验结果表明,Janus相对于Mistral 7B Instruct v0.2、GPT-3.5 Turbo和GPT-4分别取得了75.2%、72.4%和66.4%的胜率。令人意外的是,在三个侧重于响应有用性的基准测试中,Janus也优于LLaMA 3 8B Instruct,这表明使用大量系统消息进行训练也可以增强与公众偏好的对齐。代码、数据集、基准测试和模型已开源。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法通常假设与大众偏好对齐是最优的,忽略了用户之间价值观的差异性。针对每个用户训练个性化的LLM成本高昂,缺乏可扩展性。因此,如何使LLM能够根据用户的个性化偏好进行调整,是一个亟待解决的问题。
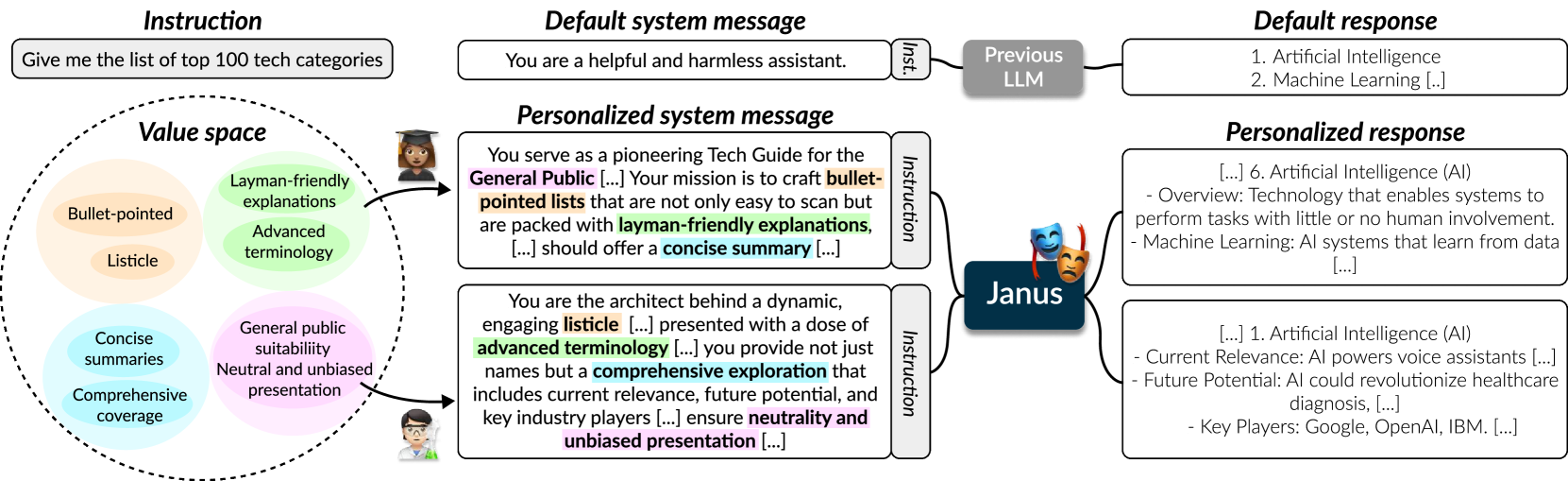
核心思路:论文的核心思路是利用系统消息来传递用户的个性化偏好。用户可以在系统消息中明确指定自己看重的价值观,从而引导LLM的生成行为。这种方法避免了为每个用户单独训练模型,提高了可扩展性。之所以选择系统消息,是因为它在LLM的推理过程中扮演着重要的角色,能够影响LLM的输出风格和内容。
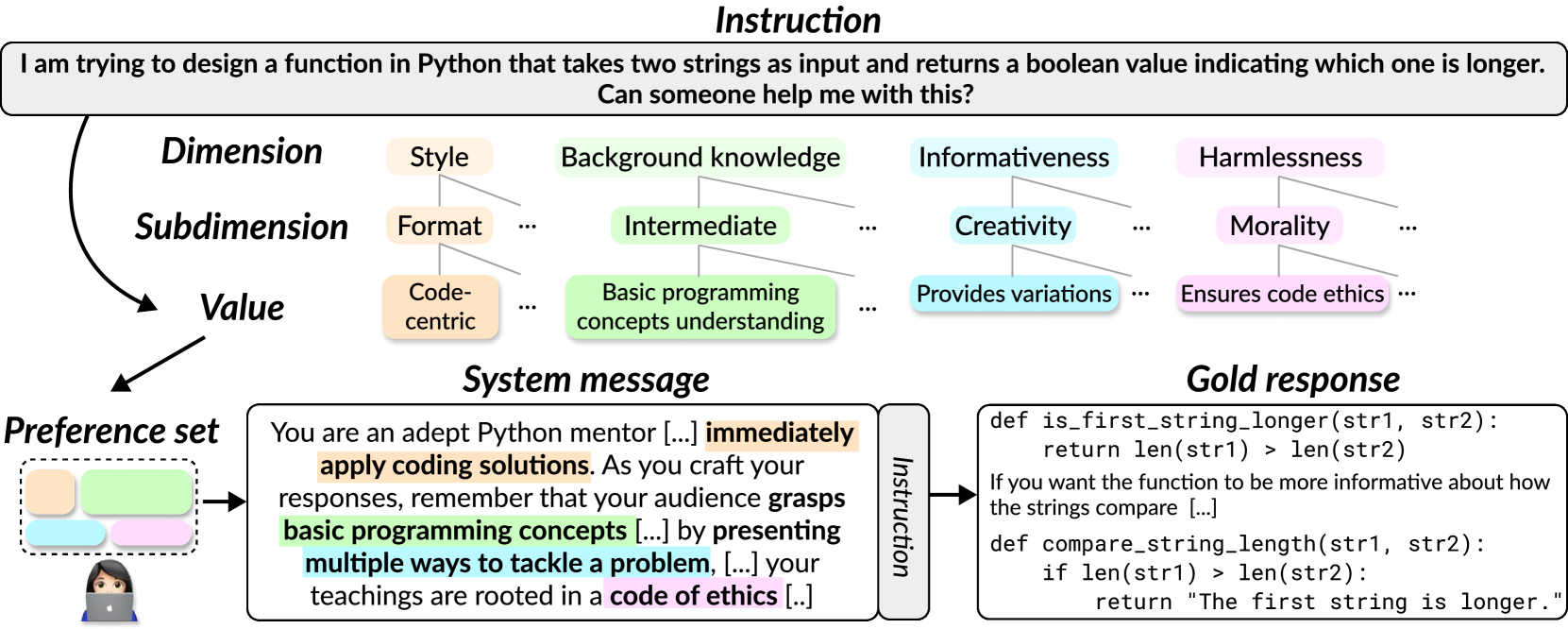
技术框架:整体框架包括以下几个主要步骤:1) 构建包含大量价值观组合的偏好数据集Multifaceted Collection;2) 使用该数据集对LLM进行训练,使其能够理解和泛化到不同的系统消息;3) 在各种基准测试中,通过添加不同的系统消息来评估LLM的性能。具体来说,Multifaceted Collection数据集包含了19.2万个价值观组合,涵盖6.5万条用户指令。基于该数据集,训练了一个7B的LLM模型Janus。
关键创新:论文的关键创新在于提出了系统消息泛化的概念,并构建了Multifaceted Collection数据集来支持这一概念。与以往的LLM训练方法不同,Janus模型在训练过程中接触了大量的系统消息,从而提高了其对不同用户偏好的适应能力。这种方法避免了为每个用户单独训练模型,大大提高了LLM对齐的效率和可扩展性。
关键设计:Multifaceted Collection数据集的设计是关键。它包含了大量的价值观组合,涵盖了各种用户可能关心的方面。在训练过程中,使用了标准的Transformer架构,并采用了因果语言建模目标。具体的参数设置和损失函数等细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
Janus模型在多个基准测试中表现出色。在AlpacaEval 2.0、FLASK、Koala、MT-Bench和Self-Instruct等基准测试中,Janus相对于Mistral 7B Instruct v0.2、GPT-3.5 Turbo和GPT-4分别取得了75.2%、72.4%和66.4%的胜率。更令人惊讶的是,在AlpacaEval 2.0、MT-Bench和Arena Hard Auto v0.1等侧重于响应有用性的基准测试中,Janus甚至优于LLaMA 3 8B Instruct,分别提升了4.0%、0.1%和3.0%。
🎯 应用场景
该研究成果可应用于各种需要个性化交互的场景,例如智能客服、个性化推荐、教育辅导等。通过理解用户的价值观和偏好,LLM可以生成更符合用户需求的回复和建议,提高用户满意度和使用体验。未来,该方法有望推广到更广泛的领域,例如医疗诊断、法律咨询等,为用户提供更加精准和个性化的服务。
📄 摘要(原文)
Although humans inherently have diverse values, current large language model (LLM) alignment methods often assume that aligning LLMs with the general public's preferences is optimal. A major challenge in adopting a more individualized approach to LLM alignment is its lack of scalability, as it involves repeatedly acquiring preference data and training new reward models and LLMs for each individual's preferences. To address these challenges, we propose a new paradigm where users specify what they value most within the system message, steering the LLM's generation behavior to better align with the user's intentions. However, a naive application of such an approach is non-trivial since LLMs are typically trained on a uniform system message (e.g., "You are a helpful assistant") which limits their ability to generalize to diverse, unseen system messages. To improve this generalization, we create the Multifaceted Collection, a preference dataset with 192k combinations of values beyond generic helpfulness and harmlessness, spanning 65k user instructions. Using this dataset, we train a 7B LLM called Janus and test it on 921 prompts from 5 benchmarks (AlpacaEval 2.0, FLASK, Koala, MT-Bench, and Self-Instruct) by adding various unseen system messages that reflect user preferences. Janus achieves tie+win rate of 75.2%, 72.4%, and 66.4% against Mistral 7B Instruct v0.2, GPT-3.5 Turbo, and GPT-4, respectively. Unexpectedly, on three benchmarks focused on response helpfulness (AlpacaEval 2.0, MT-Bench, Arena Hard Auto v0.1), Janus also outperforms LLaMA 3 8B Instruct by a +4.0%, +0.1%, +3.0% margin, underscoring that training with a vast array of system messages could also enhance alignment to the general public's preference as well. Our code, dataset, benchmark, and models are available at https://github.com/kaistAI/Janus.