Online Merging Optimizers for Boosting Rewards and Mitigating Tax in Alignment
作者: Keming Lu, Bowen Yu, Fei Huang, Yang Fan, Runji Lin, Chang Zhou
分类: cs.CL, cs.LG
发布日期: 2024-05-28
💡 一句话要点
提出在线融合优化器,提升奖励并缓解对齐中的能力退化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 人类反馈 模型对齐 能力退化 在线优化 梯度融合 对齐税
📋 核心要点
- RLHF对齐过程中,模型能力退化(对齐税)是挑战,简单插值RLHF和SFT模型参数虽可缓解,但会降低奖励。
- 提出在线融合优化器,在RLHF优化步骤中融合RL策略和SFT模型,持续调节训练方向,提升奖励。
- 实验表明,该优化器在多种模型、算法和模型融合方法上有效,显著提升奖励并缓解对齐税,提高整体性能。
📝 摘要(中文)
在强化学习中,如何有效地将大型语言模型(LLMs)与以人为本的价值观对齐,同时防止通过预训练和监督微调(SFT)获得的能力退化,是一个核心挑战。本文首先发现,插值RLHF和SFT模型参数可以调整人类偏好和基本能力之间的权衡,从而以对齐奖励为代价来减少对齐税。受此启发,我们提出在RLHF的每个优化步骤中集成RL策略和SFT模型,以持续调节训练方向,引入在线融合优化器。具体来说,我们将梯度与SFT和预训练模型之间的参数差异融合,有效地将梯度导向在SFT优化方向上最大化奖励。我们证明了我们的优化器适用于不同的LLM系列,如Qwen和LLaMA,跨越从1.8B到8B的各种模型大小,各种RLHF算法(如DPO和KTO)以及现有的模型融合方法。它显著提高了对齐奖励,同时减轻了对齐税,在14个基准测试中实现了更高的整体性能。
🔬 方法详解
问题定义:论文旨在解决在利用人类反馈进行强化学习(RLHF)对齐大型语言模型时,模型能力退化(即“对齐税”)的问题。现有方法,如直接使用RLHF,会导致模型在对齐人类偏好的同时,丧失部分预训练和监督微调阶段获得的通用能力。简单的模型参数插值可以在一定程度上缓解这个问题,但会牺牲对齐奖励。
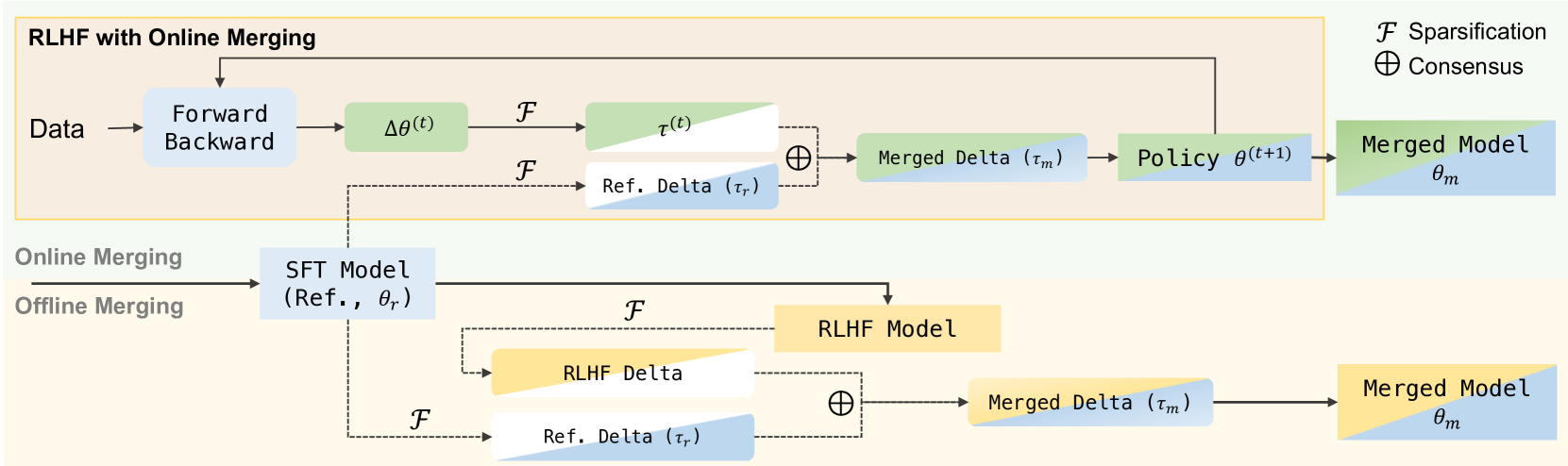
核心思路:核心思路是在RLHF训练过程中,动态地将RL策略的梯度与SFT模型的优化方向进行融合。通过这种方式,优化器能够在最大化奖励的同时,保持模型的部分SFT能力,从而缓解对齐税。关键在于利用SFT模型和预训练模型之间的参数差异来引导RL策略的更新方向。
技术框架:整体框架是在标准的RLHF训练流程中,替换原有的优化器为提出的在线融合优化器。该优化器在每个优化步骤中,计算RL策略的梯度,并将其与基于SFT模型和预训练模型参数差异计算出的梯度方向进行融合。融合后的梯度用于更新RL策略的参数。
关键创新:最重要的创新点在于在线融合优化器的设计,它能够动态地平衡RLHF的奖励和SFT的能力。与传统的RLHF方法相比,该方法不是简单地优化奖励,而是同时考虑了模型与SFT模型的相似性,从而避免了过度拟合人类偏好而导致的能力退化。与离线模型融合方法相比,该方法在训练过程中持续进行融合,能够更有效地调节训练方向。
关键设计:关键设计在于梯度融合的策略。具体来说,优化器计算RL策略的梯度,以及SFT模型和预训练模型之间参数差异所代表的梯度方向。然后,通过一个可调节的权重参数,将这两个梯度方向进行加权融合。这个权重参数可以根据具体的任务和模型进行调整,以达到最佳的平衡效果。论文中可能还涉及学习率等超参数的调整,以适应在线融合优化器的特性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的在线融合优化器在多种LLM(Qwen、LLaMA)和RLHF算法(DPO、KTO)上均有效,显著提高了对齐奖励,并减轻了对齐税。在14个基准测试中,该方法实现了更高的整体性能,表明其具有良好的泛化能力和实用价值。具体的性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于各种需要与人类价值观对齐的大型语言模型应用场景,例如智能助手、对话系统、内容生成等。通过缓解对齐税,可以提升模型在实际应用中的可用性和可靠性,使其在满足用户偏好的同时,保持良好的通用能力。该方法还有助于降低模型训练的成本,提高训练效率。
📄 摘要(原文)
Effectively aligning Large Language Models (LLMs) with human-centric values while preventing the degradation of abilities acquired through Pre-training and Supervised Fine-tuning (SFT) poses a central challenge in Reinforcement Learning from Human Feedback (RLHF). In this paper, we first discover that interpolating RLHF and SFT model parameters can adjust the trade-off between human preference and basic capabilities, thereby reducing the alignment tax at the cost of alignment reward. Inspired by this, we propose integrating the RL policy and SFT models at each optimization step in RLHF to continuously regulate the training direction, introducing the Online Merging Optimizer. Specifically, we merge gradients with the parameter differences between SFT and pretrained models, effectively steering the gradient towards maximizing rewards in the direction of SFT optimization. We demonstrate that our optimizer works well with different LLM families, such as Qwen and LLaMA, across various model sizes ranging from 1.8B to 8B, various RLHF algorithms like DPO and KTO, and existing model merging methods. It significantly enhances alignment reward while mitigating alignment tax, achieving higher overall performance across 14 benchmarks.