Enhancing Emotion Recognition in Conversation through Emotional Cross-Modal Fusion and Inter-class Contrastive Learning
作者: Haoxiang Shi, Xulong Zhang, Ning Cheng, Yong Zhang, Jun Yu, Jing Xiao, Jianzong Wang
分类: cs.CL
发布日期: 2024-05-28
备注: Accepted by the 20th International Conference on Intelligent Computing (ICIC 2024)
💡 一句话要点
提出基于跨模态融合和类间对比学习的对话情感识别增强方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 对话情感识别 跨模态融合 类间对比学习 情感分析 多模态学习
📋 核心要点
- 现有对话情感识别方法在跨模态融合时存在信息冗余和模态差异忽略的问题。
- 提出一种基于向量连接的跨模态融合网络,并引入监督类间对比学习模块。
- 实验结果表明,该方法在IEMOCAP和MELD数据集上取得了优异的性能。
📝 摘要(中文)
本文旨在提升对话情感识别(ERC)的性能,通过上下文信息识别话语的情感类别。现有ERC方法在跨模态融合时依赖简单连接,忽略了模态间的信息差异,导致模型无法关注模态特定的情感信息,且未有效处理模态间的共享信息,造成信息冗余。为克服这些限制,本文提出了一种基于向量连接的跨模态融合情感预测网络,主要包括基于连接向量的多模态特征融合阶段和基于融合特征的情感分类阶段。此外,设计了一个基于情感标签的监督类间对比学习模块。实验结果表明,该方法有效,并在IEMOCAP和MELD数据集上表现出色。
🔬 方法详解
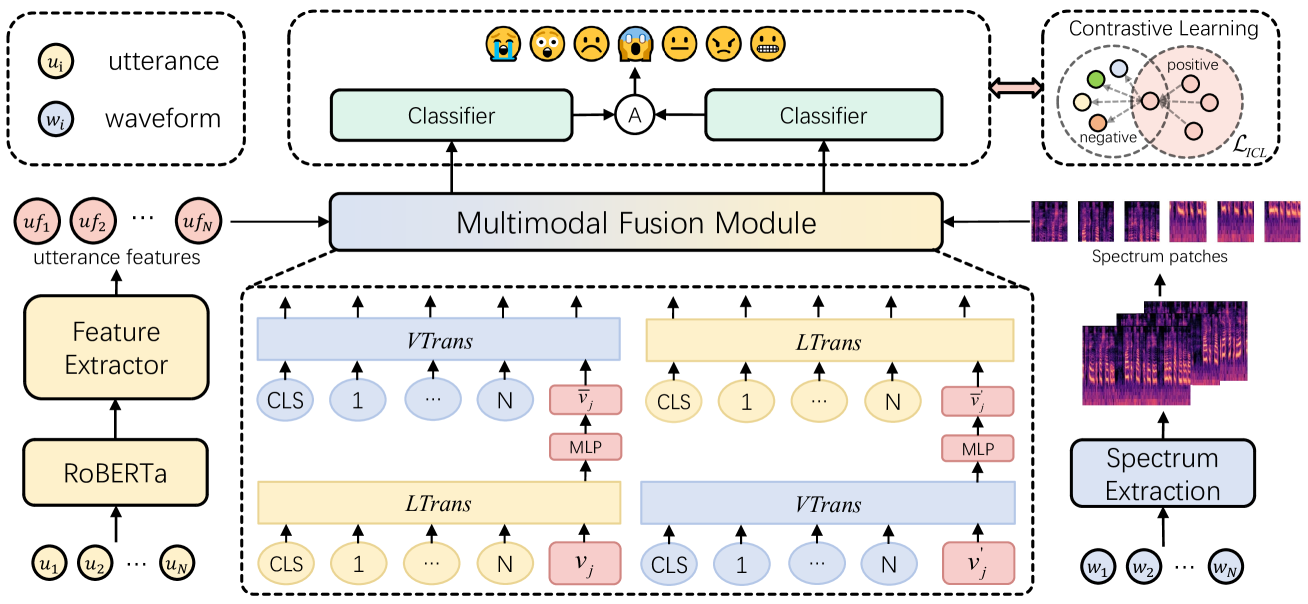
问题定义:对话情感识别(ERC)旨在根据对话上下文识别每个话语的情感类别。现有方法主要痛点在于跨模态融合方式简单,未能充分利用模态间的差异性信息,并且忽略了模态间的共享信息,导致信息冗余,影响情感识别的准确性。
核心思路:本文的核心思路是通过更精细的跨模态融合方式,有效利用模态特定信息和共享信息。同时,引入类间对比学习,使得模型能够更好地区分不同情感类别,从而提升情感识别的性能。
技术框架:该网络主要包含两个阶段:1) 基于连接向量的多模态特征融合阶段:该阶段旨在将不同模态的特征进行有效融合,突出模态特定信息,并减少信息冗余。2) 基于融合特征的情感分类阶段:该阶段利用融合后的特征进行情感分类。此外,还包含一个监督类间对比学习模块,用于优化特征表示。
关键创新:本文的关键创新在于:1) 提出了基于向量连接的跨模态融合方法,能够更好地捕捉模态间的差异性和相关性。2) 设计了监督类间对比学习模块,通过拉近同类样本距离、推远异类样本距离,提升模型的情感区分能力。
关键设计:在多模态特征融合阶段,具体采用了向量连接的方式来融合不同模态的特征,并可能使用了注意力机制来突出重要特征。在类间对比学习模块中,损失函数的设计至关重要,通常采用对比损失或三元组损失等,以实现类内紧凑、类间分离的效果。具体的网络结构细节和参数设置在论文中应该有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在IEMOCAP和MELD数据集上取得了显著的性能提升。具体提升幅度和对比基线需要在论文中查找(未知),但摘要明确指出该方法表现出色,验证了所提出方法的有效性。
🎯 应用场景
该研究成果可应用于智能客服、情感聊天机器人、心理健康评估等领域。通过准确识别对话中的情感,可以使机器更好地理解人类意图,提供更个性化、更贴心的服务,并有助于构建更和谐的人机交互关系。未来,该技术还可扩展到其他多模态情感分析任务中。
📄 摘要(原文)
The purpose of emotion recognition in conversation (ERC) is to identify the emotion category of an utterance based on contextual information. Previous ERC methods relied on simple connections for cross-modal fusion and ignored the information differences between modalities, resulting in the model being unable to focus on modality-specific emotional information. At the same time, the shared information between modalities was not processed to generate emotions. Information redundancy problem. To overcome these limitations, we propose a cross-modal fusion emotion prediction network based on vector connections. The network mainly includes two stages: the multi-modal feature fusion stage based on connection vectors and the emotion classification stage based on fused features. Furthermore, we design a supervised inter-class contrastive learning module based on emotion labels. Experimental results confirm the effectiveness of the proposed method, demonstrating excellent performance on the IEMOCAP and MELD datasets.