Cross-Modal Safety Alignment: Is textual unlearning all you need?
作者: Trishna Chakraborty, Erfan Shayegani, Zikui Cai, Nael Abu-Ghazaleh, M. Salman Asif, Yue Dong, Amit K. Roy-Chowdhury, Chengyu Song
分类: cs.CL, cs.CR, cs.LG
发布日期: 2024-05-27 (更新: 2025-10-14)
备注: Accepted by EMNLP 2024 Findings
💡 一句话要点
跨模态安全对齐:文本领域知识遗忘足以应对多模态攻击吗?
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨模态安全 知识遗忘 视觉-语言模型 安全对齐 文本遗忘
📋 核心要点
- 现有的视觉-语言模型安全训练方法难以应对多模态攻击,且收集多模态安全训练数据成本高昂。
- 该论文提出仅通过在文本领域进行知识遗忘,即可有效提升视觉-语言模型在跨模态场景下的安全性。
- 实验结果表明,文本知识遗忘显著降低了攻击成功率,同时保持了模型效用,且计算成本更低。
📝 摘要(中文)
最近的研究表明,将新的模态集成到大型语言模型(LLM)中,例如视觉-语言模型(VLM),会创建一个新的攻击面,绕过现有的安全训练技术,如监督微调(SFT)和基于人类反馈的强化学习(RLHF)。虽然可以在多模态设置中进行进一步的基于SFT和RLHF的安全训练,但收集多模态训练数据集构成了一个重大挑战。受到最近多模态模型结构设计的启发,无论输入模态的组合如何,所有输入最终都会融合到语言空间中,我们旨在探索仅在文本领域进行知识遗忘是否对跨模态安全对齐有效。我们对六个数据集的评估经验表明了可迁移性——VLM中的文本知识遗忘显著降低了攻击成功率(ASR),对于基于文本和基于视觉-文本的攻击,ASR降低到低于8%,在某些情况下甚至接近2%,同时保留了模型的效用。此外,我们的实验表明,使用多模态数据集进行知识遗忘没有潜在的好处,但会显著增加计算需求,可能高达6倍。
🔬 方法详解
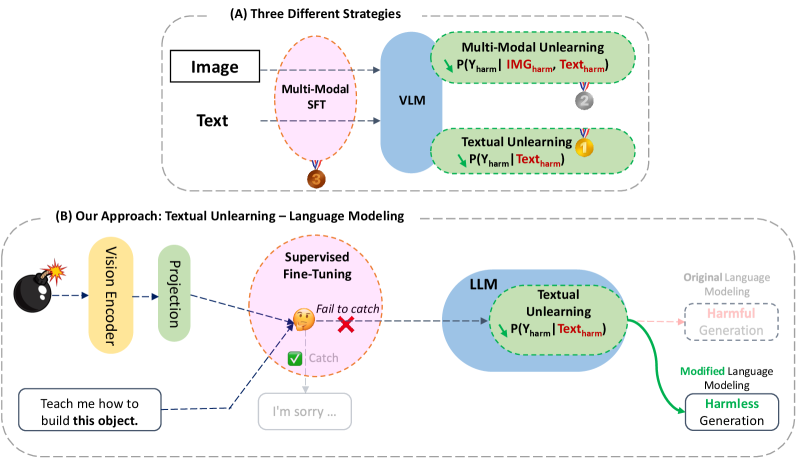
问题定义:现有的视觉-语言模型(VLM)容易受到跨模态攻击,攻击者可以通过图像或图像与文本的组合来绕过模型的安全机制。传统的安全训练方法,如监督微调(SFT)和基于人类反馈的强化学习(RLHF),在多模态场景下需要大量标注数据,成本高昂。因此,如何高效地提升VLM的跨模态安全性是一个关键问题。
核心思路:该论文的核心思路是利用VLM的结构特性,即所有模态的输入最终都会融合到语言空间中。因此,作者假设仅在文本领域进行知识遗忘(unlearning)就可以有效地提升VLM的跨模态安全性,而无需收集和训练多模态安全数据集。这种方法旨在通过消除模型在文本领域中学习到的有害知识,从而降低其对跨模态攻击的敏感性。
技术框架:该论文的技术框架主要包括以下几个步骤:1) 选择一个预训练的VLM作为基础模型;2) 构建或选择用于知识遗忘的文本数据集;3) 使用知识遗忘算法在文本数据集上对VLM进行微调,以消除有害知识;4) 使用一系列跨模态攻击数据集评估模型的安全性,并与基线方法进行比较。
关键创新:该论文最重要的技术创新点在于提出了仅通过文本知识遗忘来实现跨模态安全对齐的思想。与传统的需要大量多模态数据进行安全训练的方法相比,该方法更加高效且易于实现。此外,该论文还通过实验验证了文本知识遗忘在降低跨模态攻击成功率方面的有效性,并证明了其在保持模型效用方面的优势。
关键设计:论文中关键的设计包括:1) 选择了合适的知识遗忘算法,例如基于梯度的遗忘方法;2) 精心构建了用于知识遗忘的文本数据集,确保其包含足够多的有害知识;3) 使用了多种跨模态攻击数据集进行评估,以全面衡量模型的安全性;4) 详细分析了知识遗忘对模型性能的影响,并进行了消融实验以验证不同因素的作用。
🖼️ 关键图片
📊 实验亮点
实验结果表明,仅通过文本知识遗忘,VLM的攻击成功率(ASR)显著降低,对于基于文本和基于视觉-文本的攻击,ASR降低到低于8%,在某些情况下甚至接近2%。同时,该方法保持了模型的效用。此外,与使用多模态数据集进行知识遗忘相比,该方法计算成本更低,效率更高。
🎯 应用场景
该研究成果可应用于提升各种视觉-语言模型的安全性,例如图像字幕生成、视觉问答、图像检索等。通过文本知识遗忘,可以有效降低模型被恶意利用的风险,保障用户安全。此外,该方法还可以推广到其他多模态模型,为构建更加安全可靠的人工智能系统提供技术支持。
📄 摘要(原文)
Recent studies reveal that integrating new modalities into Large Language Models (LLMs), such as Vision-Language Models (VLMs), creates a new attack surface that bypasses existing safety training techniques like Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF). While further SFT and RLHF-based safety training can be conducted in multi-modal settings, collecting multi-modal training datasets poses a significant challenge. Inspired by the structural design of recent multi-modal models, where, regardless of the combination of input modalities, all inputs are ultimately fused into the language space, we aim to explore whether unlearning solely in the textual domain can be effective for cross-modality safety alignment. Our evaluation across six datasets empirically demonstrates the transferability -- textual unlearning in VLMs significantly reduces the Attack Success Rate (ASR) to less than 8\% and in some cases, even as low as nearly 2\% for both text-based and vision-text-based attacks, alongside preserving the utility. Moreover, our experiments show that unlearning with a multi-modal dataset offers no potential benefits but incurs significantly increased computational demands, possibly up to 6 times higher.