Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering
作者: Hongyu Yang, Liyang He, Min Hou, Shuanghong Shen, Rui Li, Jiahui Hou, Jianhui Ma, Junda Zhao
分类: cs.CL, cs.AI
发布日期: 2024-05-27
💡 一句话要点
ALMupQA:通过多视角用户偏好排序反馈对LLM进行对齐,用于编程问答
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码问答 大型语言模型 用户偏好 强化学习 检索增强 多视角学习 代码生成
📋 核心要点
- 现有代码问答模型难以捕捉代码社区中用户偏好的多样性,尤其是在答案存在多种可能且API不断更新的情况下。
- ALMupQA框架通过多视角偏好排序对齐(MPRA)和检索增强的上下文学习(RIL)来解决用户偏好和答案过时的问题。
- 实验表明,ALMupQA在BLEU、BERTScore和CodeBERTScore等指标上均优于基线模型,证明了其有效性。
📝 摘要(中文)
代码社区问答(CCQA)旨在解决与编程相关的问题,从而提高软件工程和学术研究的生产力。来自人类反馈的强化学习(RLHF)的最新进展已经改变了大型语言模型(LLM)的微调过程,使其能够生成与人类行为非常相似的响应。将具有RLHF的LLM用于实际的CCQA应用已成为一个有希望的研究领域。与标准的代码问答任务不同,CCQA涉及多个可能的答案,每个响应的用户偏好各不相同。此外,代码社区通常表现出对新API的偏好。这些挑战阻止了LLM生成满足CCQA任务中用户多样化偏好的响应。为了解决这些问题,我们提出了一个名为ALMupQA的新框架,通过多视角用户偏好排序反馈对LLM进行对齐,以创建以用户为中心的响应。我们的方法从多视角偏好排序对齐(MPRA)开始,它基于代码社区答案的特征综合了不同的用户偏好。然后,我们引入了一个检索增强的上下文学习(RIL)模块,通过从问题库中检索类似问题的响应来缓解过时答案的问题。由于高质量、多答案CCQA数据集的可用性有限,我们还从真实的代码社区开发了一个名为StaCCQA的数据集。大量的实验证明了ALMupQA框架在准确性和用户偏好方面的有效性。与基础模型相比,ALMupQA在BLEU上提高了近11%,在BERTScore和CodeBERTScore上分别提高了20%和17.5%。
🔬 方法详解
问题定义:论文旨在解决代码社区问答(CCQA)中,大型语言模型(LLM)难以生成满足用户多样化偏好的答案的问题。现有方法无法有效捕捉用户对不同答案的偏好,尤其是在答案存在多种可能性,且代码社区对新API有较高偏好的情况下,导致生成的答案不够用户友好。
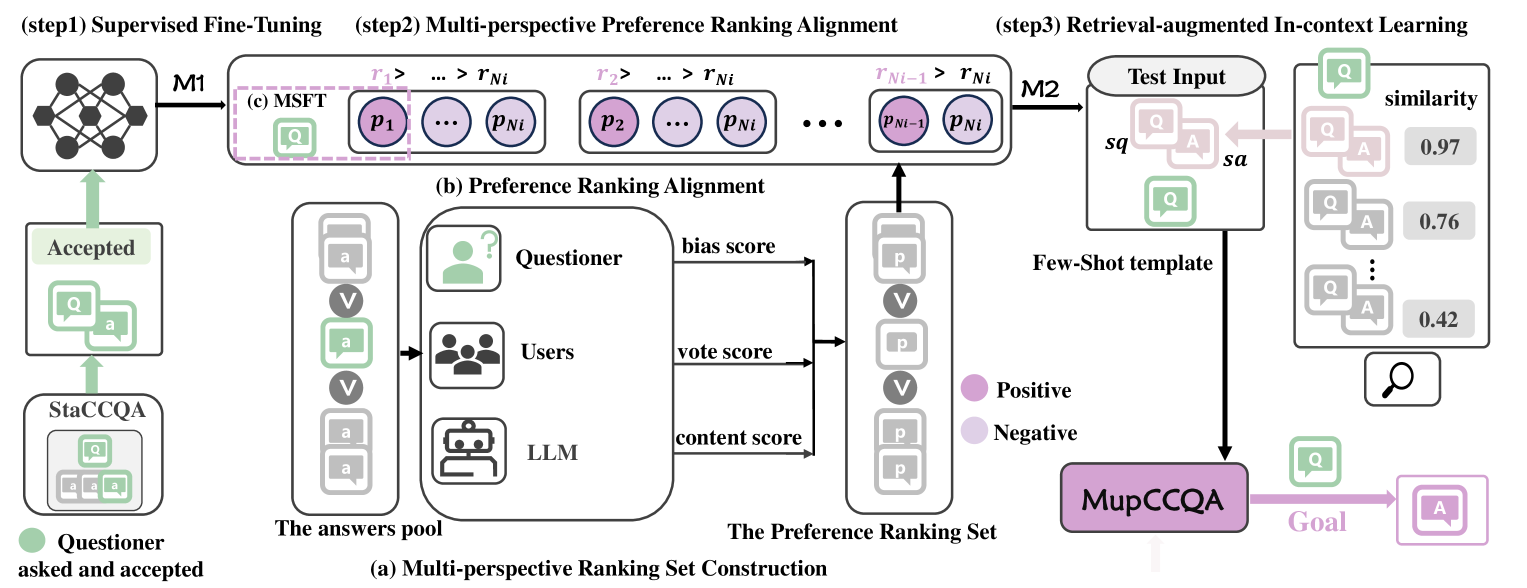
核心思路:论文的核心思路是通过多视角用户偏好排序反馈来对齐LLM,使其能够生成更符合用户需求的答案。具体而言,首先通过多视角偏好排序对齐(MPRA)模块学习用户偏好,然后利用检索增强的上下文学习(RIL)模块缓解答案过时的问题。
技术框架:ALMupQA框架主要包含两个模块:多视角偏好排序对齐(MPRA)和检索增强的上下文学习(RIL)。MPRA模块负责从代码社区的答案中提取特征,并根据用户偏好进行排序对齐。RIL模块则通过检索与当前问题相似的历史问题及其答案,为LLM提供更丰富的上下文信息,从而生成更准确和及时的答案。整个流程是先通过MPRA学习用户偏好,再利用RIL增强LLM的上下文理解能力,最终生成符合用户偏好的答案。
关键创新:该论文的关键创新在于提出了多视角偏好排序对齐(MPRA)模块,该模块能够有效地捕捉代码社区中用户对不同答案的偏好。与传统的单一视角偏好学习方法不同,MPRA从多个角度分析答案的特征,从而更全面地理解用户偏好。此外,RIL模块的引入也有效地缓解了答案过时的问题,使得生成的答案更符合当前代码社区的需求。
关键设计:MPRA模块的关键设计在于如何选择合适的特征来表示答案,以及如何设计排序损失函数来学习用户偏好。RIL模块的关键设计在于如何有效地检索与当前问题相似的历史问题,以及如何将检索到的信息融入到LLM的输入中。论文中提出的StaCCQA数据集也为该领域的研究提供了宝贵的数据资源。具体的参数设置、损失函数和网络结构等技术细节在论文中有详细描述,此处不再赘述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ALMupQA框架在多个指标上均优于基线模型。具体而言,ALMupQA在BLEU上提高了近11%,在BERTScore上提高了20%,在CodeBERTScore上提高了17.5%。这些数据表明,ALMupQA能够更准确地生成符合用户偏好的代码答案,有效地解决了现有方法的不足。
🎯 应用场景
ALMupQA框架可应用于各种代码社区问答场景,例如Stack Overflow、GitHub Issues等。它可以帮助开发者更快速地找到符合自己需求的答案,提高开发效率。此外,该框架还可以用于构建智能编程助手,为开发者提供个性化的代码建议和解决方案。未来,该研究有望推动代码问答领域的发展,促进软件工程的自动化和智能化。
📄 摘要(原文)
Code Community Question Answering (CCQA) seeks to tackle programming-related issues, thereby boosting productivity in both software engineering and academic research. Recent advancements in Reinforcement Learning from Human Feedback (RLHF) have transformed the fine-tuning process of Large Language Models (LLMs) to produce responses that closely mimic human behavior. Leveraging LLMs with RLHF for practical CCQA applications has thus emerged as a promising area of study. Unlike standard code question-answering tasks, CCQA involves multiple possible answers, with varying user preferences for each response. Additionally, code communities often show a preference for new APIs. These challenges prevent LLMs from generating responses that cater to the diverse preferences of users in CCQA tasks. To address these issues, we propose a novel framework called Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering (ALMupQA) to create user-focused responses. Our approach starts with Multi-perspective Preference Ranking Alignment (MPRA), which synthesizes varied user preferences based on the characteristics of answers from code communities. We then introduce a Retrieval-augmented In-context Learning (RIL) module to mitigate the problem of outdated answers by retrieving responses to similar questions from a question bank. Due to the limited availability of high-quality, multi-answer CCQA datasets, we also developed a dataset named StaCCQA from real code communities. Extensive experiments demonstrated the effectiveness of the ALMupQA framework in terms of accuracy and user preference. Compared to the base model, ALMupQA showed nearly an 11% improvement in BLEU, with increases of 20% and 17.5% in BERTScore and CodeBERTScore, respectively.