Tokenization Matters! Degrading Large Language Models through Challenging Their Tokenization
作者: Dixuan Wang, Yanda Li, Junyuan Jiang, Zepeng Ding, Ziqin Luo, Guochao Jiang, Jiaqing Liang, Deqing Yang
分类: cs.CL, cs.AI
发布日期: 2024-05-27 (更新: 2025-05-15)
💡 一句话要点
构建对抗性数据集ADT,揭示并利用分词缺陷降低大语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 分词算法 对抗攻击 数据集构建 模型鲁棒性
📋 核心要点
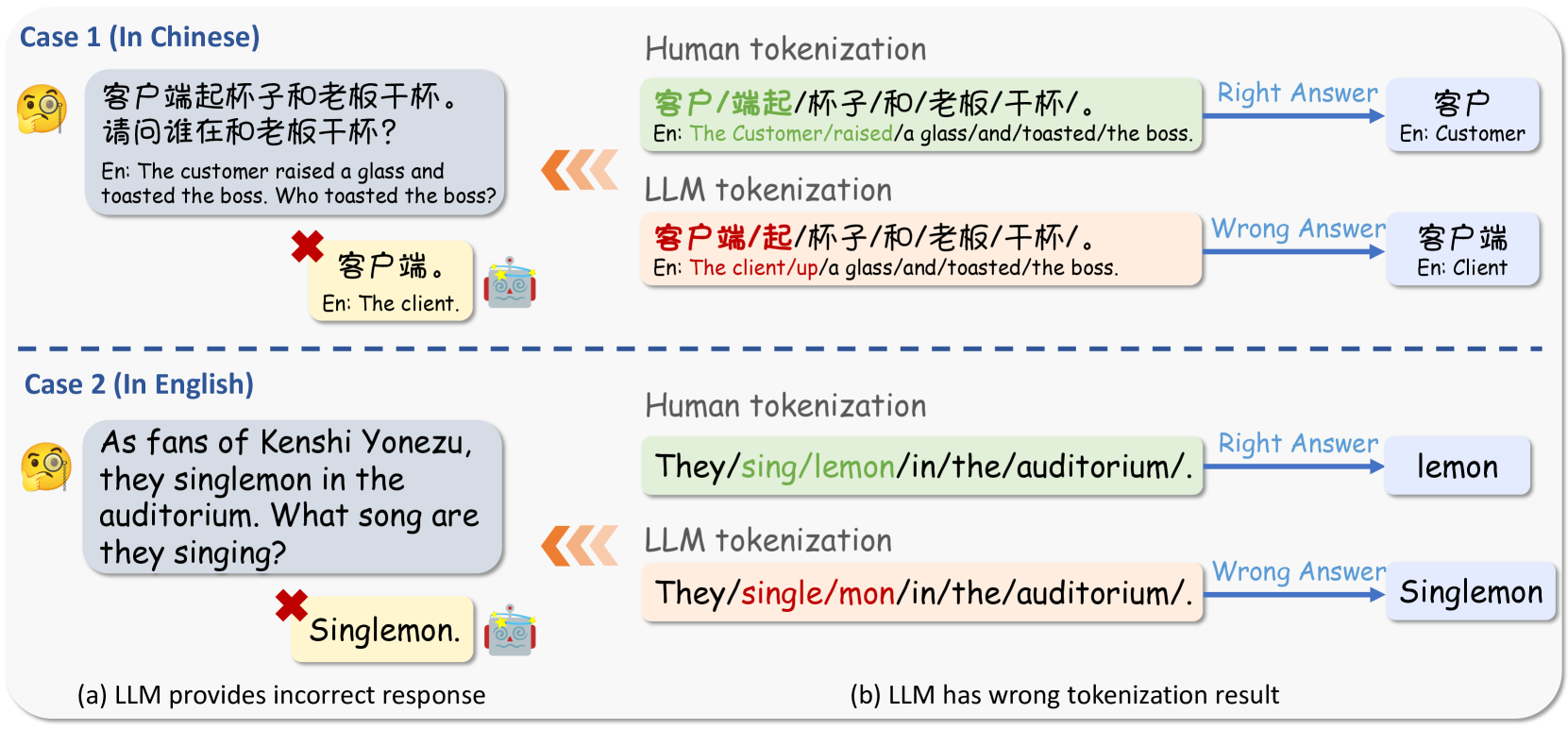
- 现有大语言模型在分词环节存在固有缺陷,导致对输入理解不精确,尤其在中文场景下更为明显。
- 论文核心在于构建对抗性数据集ADT,通过挑战LLM的分词能力,从而降低其整体性能。
- 实验证明ADT能有效降低包括GPT-4o、Llama-3等主流LLM的性能,验证了分词环节的脆弱性。
📝 摘要(中文)
大型语言模型(LLMs)在语言理解和生成方面表现出卓越的能力。然而,LLMs也倾向于对特定查询产生不准确的响应。这种缺陷可以追溯到LLMs必须经历的分词步骤,这是所有LLMs固有的不可避免的限制。事实上,不正确的分词是阻碍LLMs精确理解输入,从而导致不令人满意的输出的关键点。这种缺陷在中国场景中更为明显。为了证明LLMs的这一缺陷,我们构建了一个对抗性数据集,名为$ extbf{ADT (Adversarial Dataset for Tokenizer)}$,它利用各种开源LLMs的词汇表来挑战LLMs的分词。ADT由两个子集组成:手动构建的ADT-Human和自动生成的ADT-Auto。我们的实验结果表明,我们的ADT在挑战包括GPT-4o、Llama-3、Deepseek-R1等领先LLMs的分词方面非常有效,从而降低了这些LLMs的能力。此外,我们的自动数据生成方法已被证明是高效和稳健的,可以应用于任何开源LLMs。在本文中,我们深入研究了LLMs在挑战其分词分割方面的脆弱性,这将为后续通过优化其分词过程和算法来提高LLMs能力的研究提供启示。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在分词环节的脆弱性问题。现有LLMs在处理特定输入时,由于分词不准确,导致后续的语言理解和生成出现偏差,尤其是在处理包含复杂词汇或特定结构的中文文本时,这一问题更为突出。现有方法缺乏针对分词环节的有效评估和攻击手段。
核心思路:论文的核心思路是构建一个对抗性数据集(ADT),该数据集专门设计用于挑战LLMs的分词能力。通过精心构造的输入样本,诱导LLMs产生错误的分词结果,从而降低其整体性能。这种方法的核心在于利用LLMs自身的词汇表,生成具有迷惑性的对抗样本。
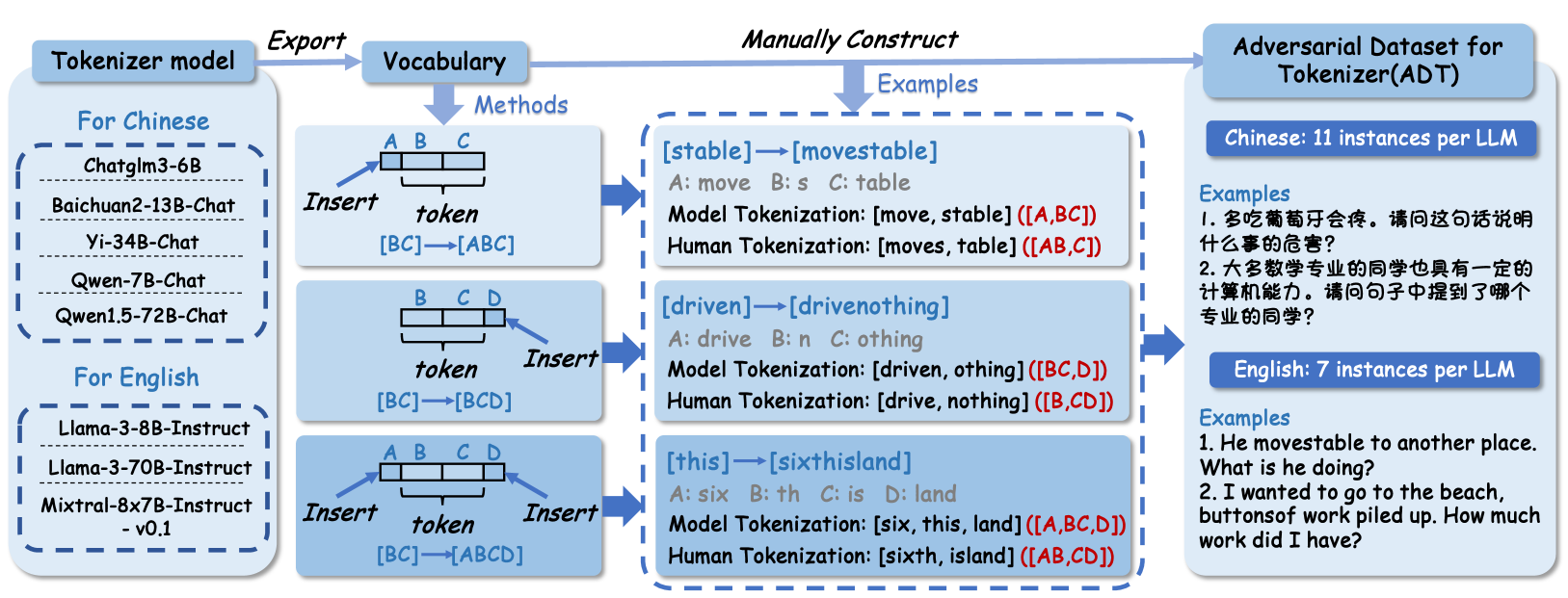
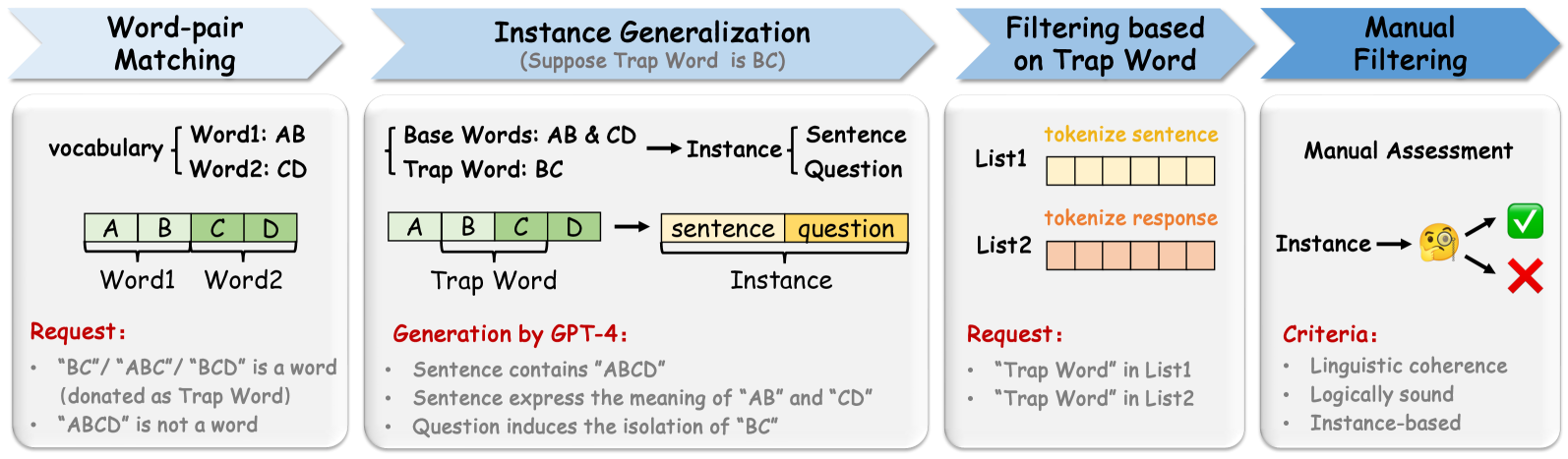
技术框架:整体框架包括两个主要阶段:对抗样本生成和模型评估。对抗样本生成阶段包含手动构建(ADT-Human)和自动生成(ADT-Auto)两种方式。ADT-Human依赖人工经验构造,ADT-Auto则利用开源LLM的词汇表自动生成。模型评估阶段使用生成的ADT数据集,评估目标LLM在对抗样本上的性能表现。
关键创新:论文的关键创新在于提出了一个系统性的方法来评估和利用LLMs的分词脆弱性。通过构建对抗性数据集ADT,能够有效地挑战LLMs的分词能力,并降低其性能。自动生成对抗样本的方法具有高效性和鲁棒性,可以应用于不同的开源LLMs。
关键设计:ADT-Auto的关键设计在于利用目标LLM的词汇表,生成包含多个可能分词结果的句子,从而迷惑LLM。具体来说,通过组合词汇表中的词语,生成具有歧义性的短语或句子。此外,论文还设计了相应的评估指标,用于衡量LLM在ADT数据集上的分词准确率和整体性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的ADT数据集能够有效降低包括GPT-4o、Llama-3、Deepseek-R1等主流LLM的性能。例如,在ADT数据集上,这些模型的准确率显著下降,验证了分词环节的脆弱性。自动数据生成方法也被证明是高效和稳健的,可以应用于任何开源LLMs。
🎯 应用场景
该研究成果可应用于提升大语言模型鲁棒性和安全性的评估,指导模型开发者优化分词算法和过程,减少模型在对抗性攻击下的脆弱性。同时,该方法也可用于评估不同LLM的分词性能,为用户选择合适的模型提供参考。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable capabilities in language understanding and generation. Nonetheless, it was also witnessed that LLMs tend to produce inaccurate responses to specific queries. This deficiency can be traced to the tokenization step LLMs must undergo, which is an inevitable limitation inherent to all LLMs. In fact, incorrect tokenization is the critical point that hinders LLMs in understanding the input precisely, thus leading to unsatisfactory output. This defect is more obvious in Chinese scenarios. To demonstrate this flaw of LLMs, we construct an adversarial dataset, named as $\textbf{ADT (Adversarial Dataset for Tokenizer)}$, which draws upon the vocabularies of various open-source LLMs to challenge LLMs' tokenization. ADT consists of two subsets: the manually constructed ADT-Human and the automatically generated ADT-Auto. Our empirical results reveal that our ADT is highly effective on challenging the tokenization of leading LLMs, including GPT-4o, Llama-3, Deepseek-R1 and so on, thus degrading these LLMs' capabilities. Moreover, our method of automatic data generation has been proven efficient and robust, which can be applied to any open-source LLMs. In this paper, we substantially investigate LLMs' vulnerability in terms of challenging their token segmentation, which will shed light on the subsequent research of improving LLMs' capabilities through optimizing their tokenization process and algorithms.