BWArea Model: Learning World Model, Inverse Dynamics, and Policy for Controllable Language Generation
作者: Chengxing Jia, Pengyuan Wang, Ziniu Li, Yi-Chen Li, Zhilong Zhang, Nan Tang, Yang Yu
分类: cs.CL, cs.LG
发布日期: 2024-05-27
💡 一句话要点
提出BWArea模型,通过模拟人脑机制实现可控语言生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可控语言生成 世界模型 逆动力学 认知策略 人脑机制 自然语言处理 大型语言模型
📋 核心要点
- 现有大型语言模型可控性不足,难以满足下游应用需求。
- BWArea模型模拟人脑Broca区和Wernicke区机制,将语言生成视为决策过程。
- 实验表明,BWArea模型在可控性和数据鲁棒性方面优于传统LLM。
📝 摘要(中文)
大型语言模型(LLMs)已引发自然语言处理的范式转变,但其有限的可控性对下游应用构成重大挑战。本文旨在通过借鉴人脑的神经机制来解决这个问题,特别是Broca区和Wernicke区,它们分别对语言生成和理解至关重要。Broca区接收来自Wernicke区的认知决策信号,将语言生成视为一个复杂的决策过程,这与现有LLM的完全自回归语言生成不同。本文提出的BWArea模型将语言生成概念化为一个决策任务,包含语言世界模型、逆动力学模型和认知策略三个组件。逆动力学模型类似于Wernicke区,旨在推断每个token背后的潜在认知意图或潜在动作。BWArea模型像现有LLM一样适用于预训练和微调。经过300亿token的预训练,BWArea模型达到了与同等规模(10亿参数)的LLM相媲美的性能。与完全自回归LLM不同,即使意外出现脏数据,其预训练性能也不会下降。这表明BWArea模型分解结构的优势在于减少了费力的数据选择和标注工作。最后,本文揭示了BWArea模型通过使用下游奖励指标微调认知策略,从而提供增强的可控性,从而简化了对齐。在TextWorld和BigBench Hard两个套件的10个任务中的9个任务中,本文的方法显示出优于自回归LLM的性能。
🔬 方法详解
问题定义:现有大型语言模型(LLMs)在自然语言生成方面取得了显著进展,但其可控性仍然是一个关键瓶颈。用户难以精确控制生成文本的风格、内容或目标。现有方法,如完全自回归模型,缺乏对生成过程的细粒度控制,容易受到噪声数据的影响,且对齐过程复杂。
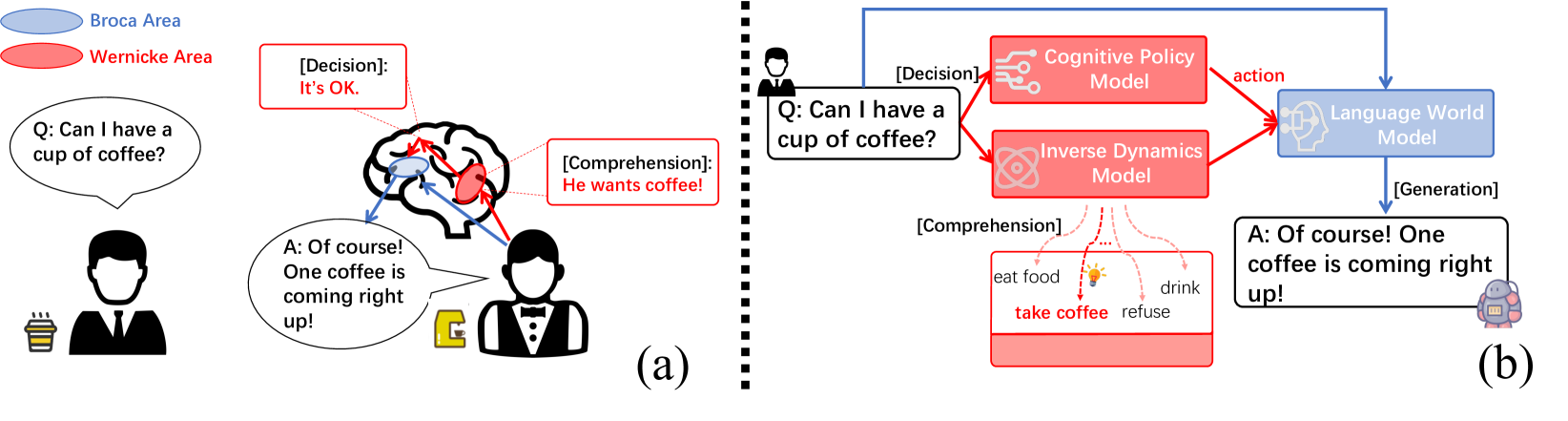
核心思路:BWArea模型的核心思想是将语言生成视为一个决策过程,并借鉴人脑中Broca区和Wernicke区的神经机制。Broca区负责语言生成,Wernicke区负责语言理解。模型通过逆动力学模型推断潜在认知意图,并利用认知策略来指导生成过程,从而实现更强的可控性。这种分解结构也有助于提高模型的鲁棒性。
技术框架:BWArea模型包含三个主要组件: 1. 语言世界模型:用于学习语言的统计规律和语义信息。 2. 逆动力学模型:用于推断每个token背后的潜在认知意图或潜在动作,类似于Wernicke区的功能。 3. 认知策略:用于根据认知意图和世界模型的状态,选择下一个要生成的token,类似于Broca区的功能。整个框架通过预训练和微调进行优化。
关键创新:BWArea模型最重要的创新在于其分解式的结构和对人脑神经机制的模拟。与传统的完全自回归模型不同,BWArea模型将生成过程分解为认知意图推断和token选择两个步骤,从而实现了更细粒度的控制。此外,逆动力学模型的引入使得模型能够更好地理解生成文本背后的意图,提高了生成质量和可控性。
关键设计:BWArea模型的关键设计包括: 1. 逆动力学模型的训练:使用对比学习或监督学习方法,训练逆动力学模型从token序列中推断潜在认知意图。 2. 认知策略的优化:使用强化学习或策略梯度方法,根据下游任务的奖励信号,优化认知策略,从而实现与特定目标的对齐。 3. 损失函数:采用交叉熵损失函数进行预训练,并根据下游任务的需求,设计特定的奖励函数进行微调。
🖼️ 关键图片


📊 实验亮点
BWArea模型在300亿token的预训练后,达到了与同等规模(10亿参数)的LLM相媲美的性能。更重要的是,与完全自回归LLM不同,BWArea模型的预训练性能不会因脏数据而下降,显示出更强的鲁棒性。在TextWorld和BigBench Hard两个套件的10个任务中的9个任务中,BWArea模型优于自回归LLM,证明了其在可控性方面的优势。
🎯 应用场景
BWArea模型具有广泛的应用前景,包括:可控文本生成(例如,根据用户指定的风格或情感生成文本)、对话系统(生成更自然和流畅的回复)、机器翻译(生成更准确和符合目标语言习惯的翻译)以及内容创作(辅助作家或记者生成高质量的文章)。该模型有望提高语言生成系统的可控性、鲁棒性和生成质量,从而推动自然语言处理技术的发展。
📄 摘要(原文)
Large language models (LLMs) have catalyzed a paradigm shift in natural language processing, yet their limited controllability poses a significant challenge for downstream applications. We aim to address this by drawing inspiration from the neural mechanisms of the human brain, specifically Broca's and Wernicke's areas, which are crucial for language generation and comprehension, respectively. In particular, Broca's area receives cognitive decision signals from Wernicke's area, treating the language generation as an intricate decision-making process, which differs from the fully auto-regressive language generation of existing LLMs. In a similar vein, our proposed system, the BWArea model, conceptualizes language generation as a decision-making task. This model has three components: a language world model, an inverse dynamics model, and a cognitive policy. Like Wernicke's area, the inverse dynamics model is designed to deduce the underlying cognitive intentions, or latent actions, behind each token. The BWArea model is amenable to both pre-training and fine-tuning like existing LLMs. With 30B clean pre-training tokens, we have trained a BWArea model, which achieves competitive performance with LLMs of equal size (1B parameters). Unlike fully auto-regressive LLMs, its pre-training performance does not degenerate if dirty data unintentionally appears. This shows the advantage of a decomposed structure of BWArea model in reducing efforts in laborious data selection and labeling. Finally, we reveal that the BWArea model offers enhanced controllability via fine-tuning the cognitive policy with downstream reward metrics, thereby facilitating alignment with greater simplicity. On 9 out of 10 tasks from two suites, TextWorld and BigBench Hard, our method shows superior performance to auto-regressive LLMs.