Exploring the LLM Journey from Cognition to Expression with Linear Representations
作者: Yuzi Yan, Jialian Li, Yipin Zhang, Dong Yan
分类: cs.CL, cs.AI
发布日期: 2024-05-27 (更新: 2024-11-08)
备注: Published in ICML 2024
💡 一句话要点
通过线性表示探索LLM从认知到表达的演进,聚焦Baichuan系列模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 认知能力 表达能力 线性表示 预训练 监督微调 强化学习 Baichuan模型
📋 核心要点
- 现有LLM训练缺乏对认知和表达能力发展阶段的深入理解,限制了模型优化和控制。
- 通过线性表示方法,在预训练、SFT和RLHF阶段分别评估LLM的认知和表达能力。
- 研究发现认知能力主要在预训练阶段形成,表达能力在SFT和RLHF阶段提升,两者存在显著相关性。
📝 摘要(中文)
本文深入研究了大型语言模型(LLM)中认知和表达能力的演变与相互作用,重点关注先进的双语(中文和英文)LLM系列——Baichuan-7B和Baichuan-33B。我们通过线性表示,在预训练、监督微调(SFT)和人类反馈强化学习(RLHF)三个关键阶段,定义并探索了模型的认知和表达能力。认知能力被定义为网络中神经元输出向量所传递的信息的数量和质量,类似于人类认知中的神经信号处理。表达能力被定义为模型产生词级输出的能力。我们的研究结果揭示了一个顺序发展模式,其中认知能力主要在预训练期间建立,而表达能力主要在SFT和RLHF期间发展。统计分析证实了这两种能力之间存在显著的相关性,表明认知能力可能限制表达潜力。本文还探讨了这些不同发展轨迹的理论基础及其与LLM架构设计的联系。此外,我们评估了各种与优化无关的策略,例如少样本学习和重复采样,这些策略弥合了认知和表达能力之间的差距。这项研究揭示了隐藏空间和输出空间之间潜在的联系,为理解和控制LLM的训练过程提供了有价值的见解。
🔬 方法详解
问题定义:本文旨在深入理解大型语言模型(LLM)在训练过程中认知能力和表达能力的发展规律。现有方法缺乏对这两种能力在不同训练阶段(预训练、监督微调、强化学习)的细致分析,难以解释和控制LLM的训练过程,也限制了模型性能的进一步提升。
核心思路:本文的核心思路是通过线性表示来量化LLM的认知和表达能力。认知能力被定义为神经元输出向量所携带的信息量和信息质量,反映了模型对知识的理解和推理能力。表达能力则被定义为模型生成词级别输出的能力,反映了模型将内部知识转化为自然语言的能力。通过分析这两种能力在不同训练阶段的变化,可以揭示LLM的学习机制。
技术框架:本文的研究框架主要包括三个阶段:1) 定义认知和表达能力的线性表示方法;2) 在Baichuan-7B和Baichuan-33B模型上,分别在预训练、SFT和RLHF阶段评估这两种能力;3) 分析认知和表达能力之间的相关性,并探讨其理论基础。此外,还评估了少样本学习和重复采样等策略对弥合认知和表达能力差距的影响。
关键创新:本文的关键创新在于提出了基于线性表示的认知和表达能力量化方法,并将其应用于分析LLM的训练过程。这种方法能够更细粒度地观察LLM的学习动态,为理解和控制LLM的训练提供了新的视角。此外,本文还揭示了认知能力和表达能力之间的相关性,为模型优化提供了新的思路。
关键设计:本文使用神经元输出向量的线性组合来表示认知和表达能力。具体而言,认知能力通过分析神经元输出向量所携带的信息量和信息质量来量化,例如可以使用互信息等指标。表达能力则通过分析模型生成词级别输出的概率分布来量化,例如可以使用困惑度等指标。此外,本文还使用了统计分析方法来评估认知和表达能力之间的相关性,并探讨其理论基础。
🖼️ 关键图片

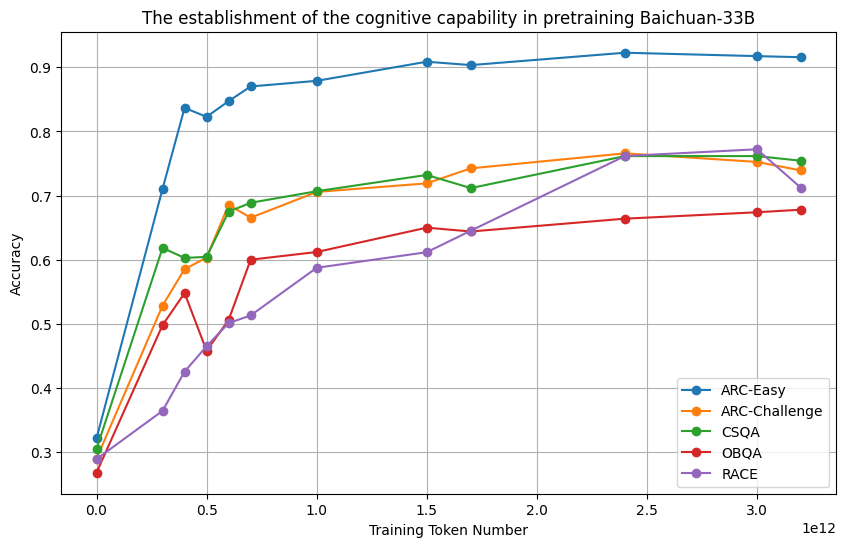

📊 实验亮点
研究表明,LLM的认知能力主要在预训练阶段建立,而表达能力主要在SFT和RLHF阶段发展。统计分析证实了认知能力和表达能力之间存在显著的相关性,表明认知能力可能限制表达潜力。少样本学习和重复采样等策略可以有效弥合认知和表达能力之间的差距。
🎯 应用场景
该研究成果可应用于指导LLM的训练和优化,提升模型性能和可控性。通过理解认知和表达能力的发展规律,可以设计更有效的训练策略,例如在预训练阶段侧重提升认知能力,在SFT和RLHF阶段侧重提升表达能力。此外,该研究还有助于开发更具解释性的LLM,提升模型的可信度和可靠性。
📄 摘要(原文)
This paper presents an in-depth examination of the evolution and interplay of cognitive and expressive capabilities in large language models (LLMs), with a specific focus on Baichuan-7B and Baichuan-33B, an advanced bilingual (Chinese and English) LLM series. We define and explore the model's cognitive and expressive capabilities through linear representations across three critical phases: Pretraining, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF). Cognitive capability is defined as the quantity and quality of information conveyed by the neuron output vectors within the network, similar to the neural signal processing in human cognition. Expressive capability is defined as the model's capability to produce word-level output. Our findings unveil a sequential development pattern, where cognitive abilities are largely established during Pretraining, whereas expressive abilities predominantly advance during SFT and RLHF. Statistical analyses confirm a significant correlation between the two capabilities, suggesting that cognitive capacity may limit expressive potential. The paper also explores the theoretical underpinnings of these divergent developmental trajectories and their connection to the LLMs' architectural design. Moreover, we evaluate various optimization-independent strategies, such as few-shot learning and repeated sampling, which bridge the gap between cognitive and expressive capabilities. This research reveals the potential connection between the hidden space and the output space, contributing valuable insights into the interpretability and controllability of their training processes.