Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models
作者: Qiong Nan, Qiang Sheng, Juan Cao, Beizhe Hu, Danding Wang, Jintao Li
分类: cs.CL, cs.CY, cs.SI
发布日期: 2024-05-26
备注: 11 pages, 5 figures, 8 tables
期刊: CIKM 2024
💡 一句话要点
GenFEND:利用大语言模型生成评论,提升假新闻检测效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 假新闻检测 大型语言模型 评论生成 用户模拟 自然语言处理
📋 核心要点
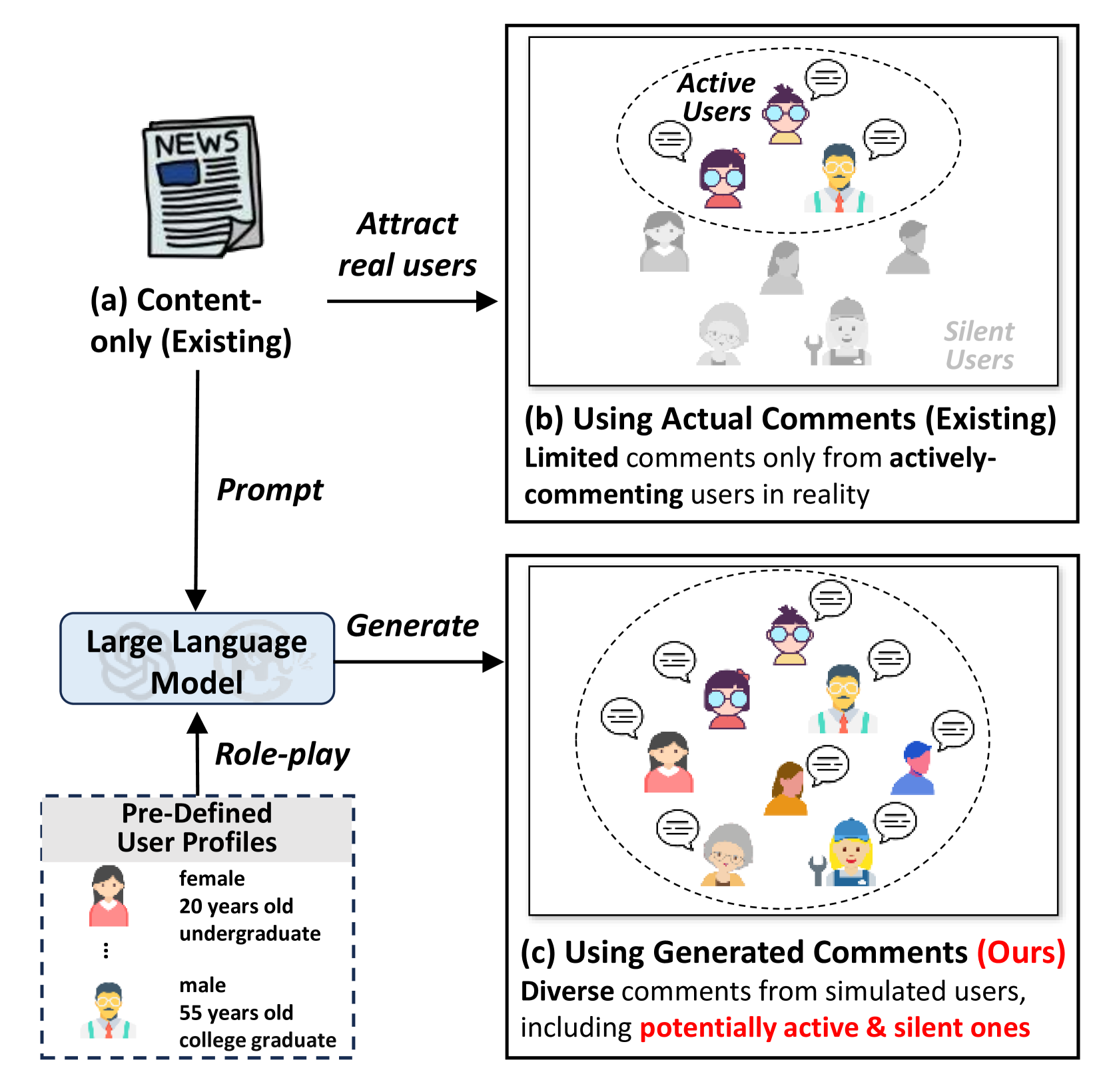
- 现有基于评论的假新闻检测方法受限于真实评论的多样性不足,特别是难以获取“沉默用户”的观点。
- GenFEND框架利用大语言模型模拟不同用户生成评论,以此增强评论的多样性,弥补真实评论的不足。
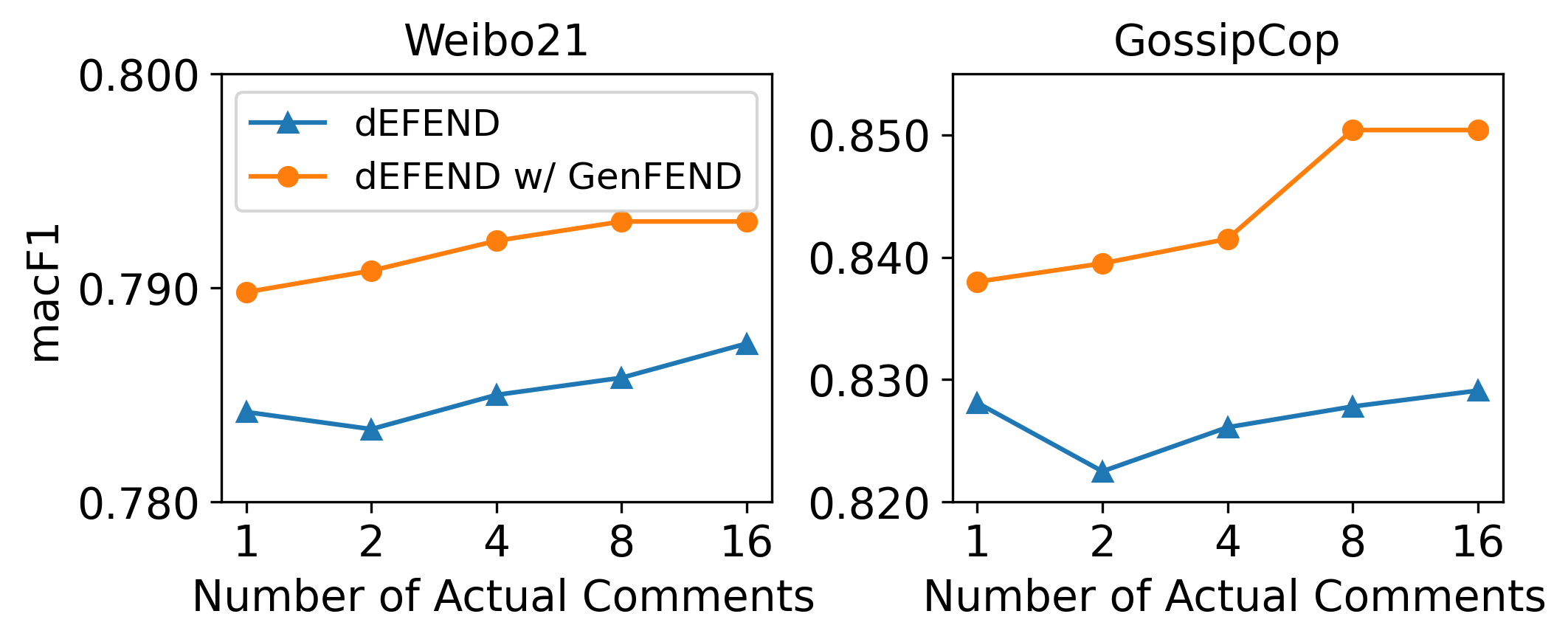
- 实验结果表明,GenFEND框架能够有效提升假新闻检测的性能,且生成的评论比真实评论更具代表性。
📝 摘要(中文)
假新闻检测在保护社交媒体用户和维护健康的新闻生态系统中起着至关重要的作用。现有的研究表明,基于评论的假新闻检测方法很有前景,因为评论可以反映用户的观点、立场和情感,并加深模型对假新闻的理解。然而,由于曝光偏差和用户评论意愿的差异,在现实中很难获得多样化的评论,尤其是在早期检测场景中。如果无法获得来自“沉默”用户的评论,那么感知到的观点可能是不完整的,从而影响新闻真伪的判断。在本文中,我们探索了寻找评论替代来源的可能性,以保证多样化评论的可用性,特别是来自沉默用户的评论。具体来说,我们提出采用大型语言模型(LLM)作为用户模拟器和评论生成器,并设计了GenFEND,一个生成反馈增强的检测框架,该框架通过使用不同的用户配置文件提示LLM来生成评论,并聚合来自多个子群体的生成评论。实验证明了GenFEND的有效性,进一步的分析表明,生成的评论涵盖了更多样化的用户,甚至可能比实际评论更有效。
🔬 方法详解
问题定义:现有基于评论的假新闻检测方法依赖于用户对新闻的真实评论。然而,由于曝光偏差(exposure bias)和用户评论意愿的差异,实际收集到的评论往往存在偏差,难以覆盖所有潜在用户的观点,特别是那些不经常发表评论的“沉默用户”。这导致模型对新闻真伪的判断可能不够全面和准确。
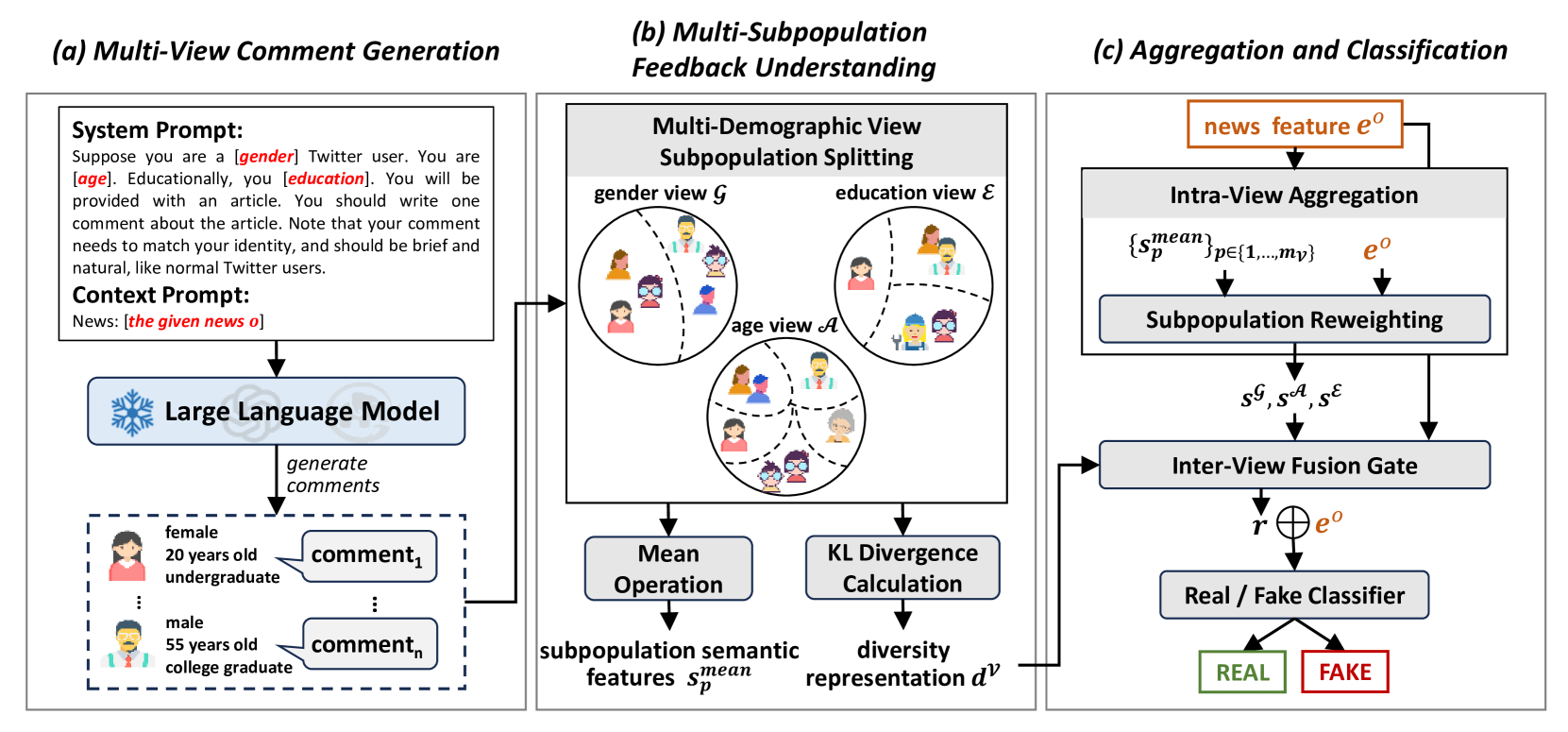
核心思路:GenFEND的核心思路是利用大型语言模型(LLM)作为用户模拟器,生成模拟用户对新闻的评论。通过设计不同的用户画像(user profiles)并提示LLM,可以生成来自不同背景、观点和情感的用户评论,从而弥补真实评论的不足,增强评论的多样性。
技术框架:GenFEND框架主要包含以下几个阶段:1) 用户画像生成:定义一系列用户属性,例如年龄、性别、教育程度、政治倾向等,构建多样化的用户画像。2) 评论生成:使用不同的用户画像提示LLM,让LLM模拟这些用户对新闻发表评论。3) 评论聚合:将来自不同用户画像生成的评论进行聚合,形成一个更全面、更具代表性的评论集合。4) 假新闻检测:将聚合后的评论集合输入到假新闻检测模型中,进行真伪判断。
关键创新:GenFEND的关键创新在于利用LLM作为用户模拟器,生成多样化的评论,从而克服了真实评论数据偏差的问题。与直接使用真实评论相比,GenFEND能够覆盖更广泛的用户群体,并提供更全面的信息,从而提高假新闻检测的准确性。
关键设计:在用户画像生成方面,论文可能采用了某种策略来确保用户画像的多样性和代表性,例如基于人口统计数据或用户行为数据进行采样。在评论生成方面,论文可能使用了特定的prompt工程技术来引导LLM生成高质量的评论,例如提供新闻内容、用户画像信息以及一些情感提示。在假新闻检测方面,可以使用各种现有的模型,例如基于Transformer的模型或图神经网络模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GenFEND框架能够显著提升假新闻检测的性能。与仅使用真实评论相比,GenFEND在多个数据集上取得了更高的准确率和F1值。更重要的是,分析表明,GenFEND生成的评论覆盖了更广泛的用户群体,甚至比真实评论更具代表性,这验证了利用LLM生成评论来增强假新闻检测的有效性。
🎯 应用场景
GenFEND框架可应用于各种社交媒体平台和新闻聚合应用中,用于自动检测和过滤假新闻,从而保护用户免受虚假信息的侵害。该方法尤其适用于早期假新闻检测,因为在新闻传播初期,真实评论往往不足,而GenFEND可以生成补充评论,提高检测的及时性和准确性。未来,该方法还可以扩展到其他类型的虚假信息检测,例如谣言和恶意宣传。
📄 摘要(原文)
Fake news detection plays a crucial role in protecting social media users and maintaining a healthy news ecosystem. Among existing works, comment-based fake news detection methods are empirically shown as promising because comments could reflect users' opinions, stances, and emotions and deepen models' understanding of fake news. Unfortunately, due to exposure bias and users' different willingness to comment, it is not easy to obtain diverse comments in reality, especially for early detection scenarios. Without obtaining the comments from the ``silent'' users, the perceived opinions may be incomplete, subsequently affecting news veracity judgment. In this paper, we explore the possibility of finding an alternative source of comments to guarantee the availability of diverse comments, especially those from silent users. Specifically, we propose to adopt large language models (LLMs) as a user simulator and comment generator, and design GenFEND, a generated feedback-enhanced detection framework, which generates comments by prompting LLMs with diverse user profiles and aggregating generated comments from multiple subpopulation groups. Experiments demonstrate the effectiveness of GenFEND and further analysis shows that the generated comments cover more diverse users and could even be more effective than actual comments.