Multi-Reference Preference Optimization for Large Language Models
作者: Hung Le, Quan Tran, Dung Nguyen, Kien Do, Saloni Mittal, Kelechi Ogueji, Svetha Venkatesh
分类: cs.CL, cs.LG
发布日期: 2024-05-26
备注: 20 pages
💡 一句话要点
提出多参考偏好优化(MRPO)算法,提升大语言模型对人类意图的对齐能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏好优化 多参考模型 直接偏好优化 人类意图对齐
📋 核心要点
- 现有直接偏好优化(DPO)方法仅依赖单一参考模型,未能充分利用多个预训练LLM的知识。
- 论文提出多参考偏好优化(MRPO)算法,通过融合多个参考模型的先验知识,提升偏好学习能力。
- 实验表明,MRPO在数据稀缺或丰富的情况下均能提升泛化能力,并在下游任务中表现更优。
📝 摘要(中文)
如何使大型语言模型(LLM)与人类的意图和价值观对齐?一种典型的解决方案是收集人类对模型输出的偏好,并相应地微调LLM,同时确保更新不会偏离参考模型太远。最近的方法,如直接偏好优化(DPO),通过引入闭式监督损失,消除了对不稳定和缓慢的强化学习优化的需求。然而,当前方法的一个显著限制是其仅针对单个参考模型的设计,忽略了利用大量预训练LLM的集体力量。为了克服这个限制,我们为使用多个参考模型的直接偏好优化引入了一种新的闭式公式。由此产生的算法,多参考偏好优化(MRPO),利用来自不同参考模型的更广泛的先验知识,与单参考DPO相比,大大增强了偏好学习能力。我们的实验表明,用MRPO微调的LLM在各种偏好数据中表现出更好的泛化能力,无论数据稀缺还是丰富。此外,MRPO有效地微调LLM,使其在多个下游自然语言处理任务(如GSM8K和TruthfulQA)中表现出卓越的性能。
🔬 方法详解
问题定义:现有直接偏好优化(DPO)方法仅使用单个参考模型,限制了其利用多个预训练语言模型中蕴含的丰富知识的能力。这导致模型在面对多样化的偏好数据时,泛化能力受限,尤其是在数据量不足的情况下,更容易过拟合到单一参考模型的偏差上。因此,如何有效融合多个参考模型的知识,提升偏好学习的泛化能力,是本文要解决的核心问题。
核心思路:本文的核心思路是利用多个参考模型提供的先验知识,通过一种新的闭式公式进行直接偏好优化。MRPO算法不再依赖单一参考模型,而是将多个参考模型的输出作为优化目标的一部分,从而使模型能够学习到更广泛、更鲁棒的偏好表示。这种方法旨在减少对单一参考模型的依赖,提高模型在不同偏好数据上的泛化能力。
技术框架:MRPO的整体框架与DPO类似,仍然采用监督学习的方式进行偏好优化,避免了强化学习的不稳定性和高计算成本。主要流程包括:1)收集人类对模型输出的偏好数据;2)利用多个参考模型生成参考输出;3)使用MRPO损失函数对目标LLM进行微调。关键在于MRPO损失函数的设计,它能够有效地融合多个参考模型的知识,并引导模型学习到符合人类偏好的输出。
关键创新:MRPO最关键的创新在于其多参考模型的偏好优化公式。与DPO仅使用单一参考模型不同,MRPO将多个参考模型的输出纳入优化目标,从而能够利用更广泛的先验知识。这种多参考模型的设计使得模型能够学习到更鲁棒的偏好表示,提高泛化能力。
关键设计:MRPO的关键设计在于损失函数的构建。损失函数需要平衡目标模型与多个参考模型之间的关系,同时保证优化过程的稳定性和效率。具体而言,损失函数通常包含一个偏好损失项,用于鼓励模型生成符合人类偏好的输出;以及一个正则化项,用于防止模型偏离参考模型太远。多个参考模型的权重可以通过交叉验证等方式进行调整,以获得最佳的性能。
🖼️ 关键图片
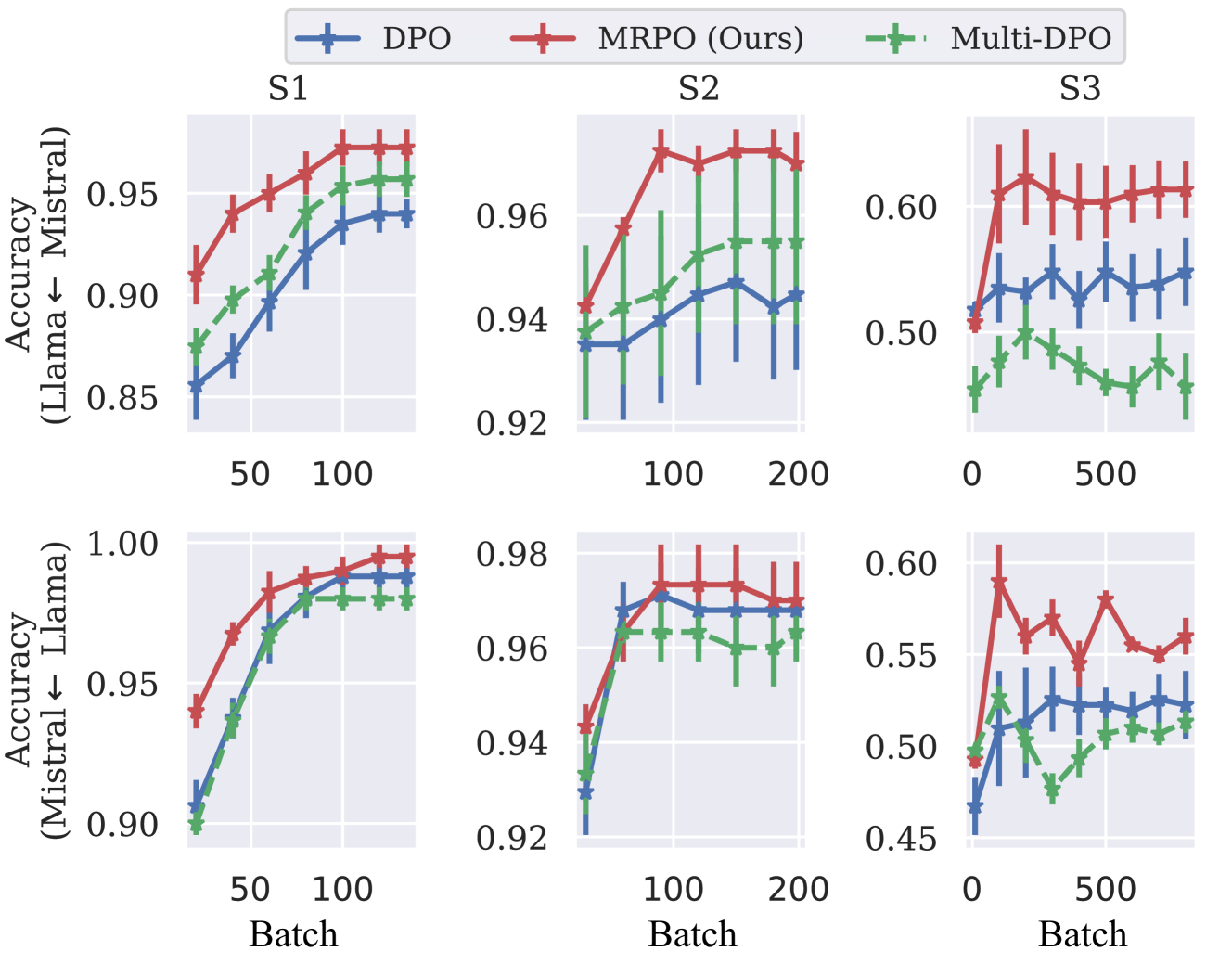
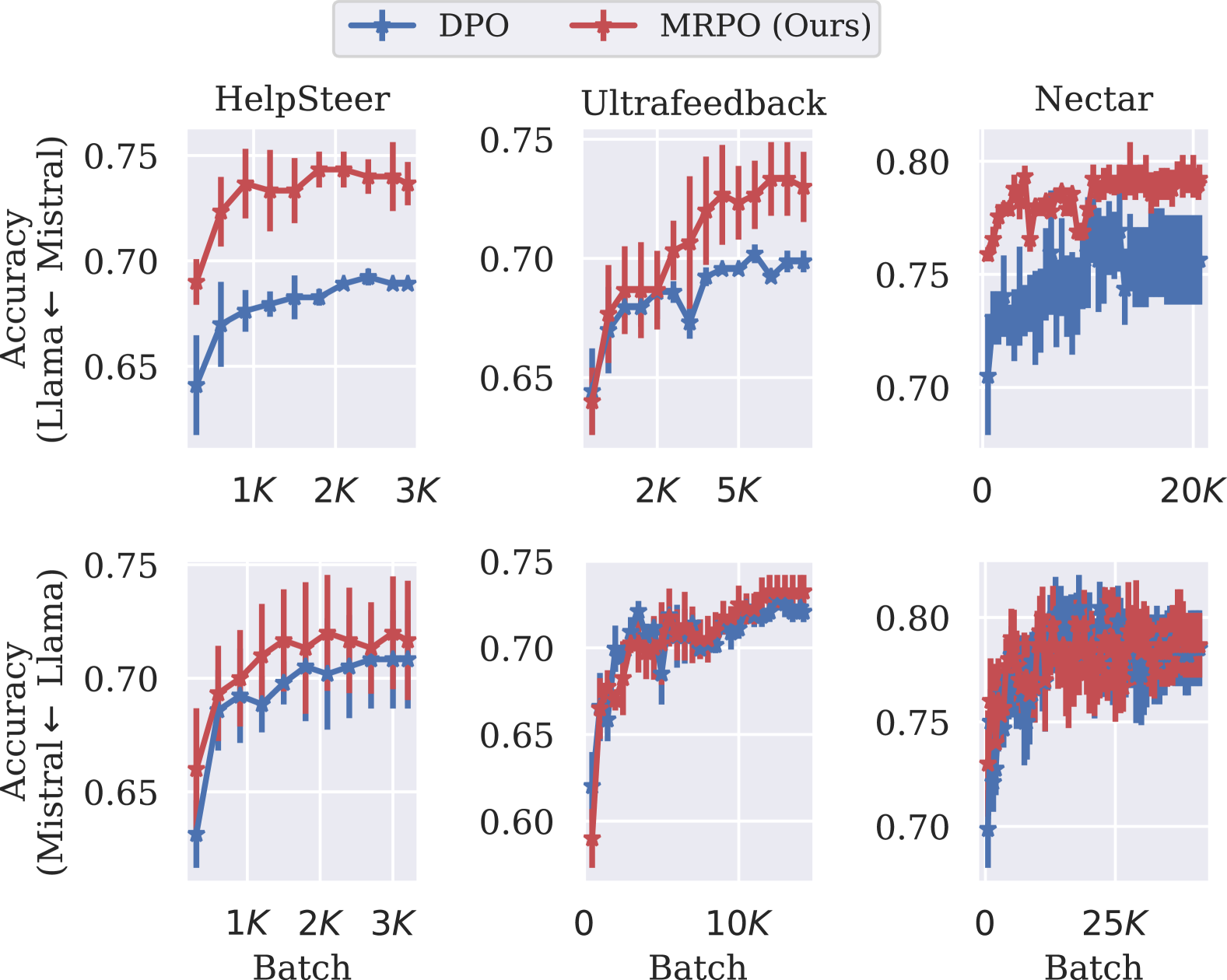

📊 实验亮点
实验结果表明,MRPO在各种偏好数据上都优于单参考DPO,尤其是在数据稀缺的情况下,泛化能力提升显著。在GSM8K和TruthfulQA等下游任务上,MRPO微调的LLM也表现出更优的性能,验证了其有效性。具体提升幅度取决于数据集和模型规模,但总体趋势是MRPO能够带来显著的性能提升。
🎯 应用场景
MRPO算法可广泛应用于各种需要对齐人类意图的大语言模型应用场景,例如对话系统、文本生成、代码生成等。通过利用多个参考模型的知识,MRPO可以提升模型生成内容的质量、安全性和可靠性,使其更好地服务于人类需求。该研究对于提升AI系统的可控性和安全性具有重要意义。
📄 摘要(原文)
How can Large Language Models (LLMs) be aligned with human intentions and values? A typical solution is to gather human preference on model outputs and finetune the LLMs accordingly while ensuring that updates do not deviate too far from a reference model. Recent approaches, such as direct preference optimization (DPO), have eliminated the need for unstable and sluggish reinforcement learning optimization by introducing close-formed supervised losses. However, a significant limitation of the current approach is its design for a single reference model only, neglecting to leverage the collective power of numerous pretrained LLMs. To overcome this limitation, we introduce a novel closed-form formulation for direct preference optimization using multiple reference models. The resulting algorithm, Multi-Reference Preference Optimization (MRPO), leverages broader prior knowledge from diverse reference models, substantially enhancing preference learning capabilities compared to the single-reference DPO. Our experiments demonstrate that LLMs finetuned with MRPO generalize better in various preference data, regardless of data scarcity or abundance. Furthermore, MRPO effectively finetunes LLMs to exhibit superior performance in several downstream natural language processing tasks such as GSM8K and TruthfulQA.