Accelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection
作者: Yun Zhu, Jia-Chen Gu, Caitlin Sikora, Ho Ko, Yinxiao Liu, Chu-Cheng Lin, Lei Shu, Liangchen Luo, Lei Meng, Bang Liu, Jindong Chen
分类: cs.CL
发布日期: 2024-05-25
💡 一句话要点
提出Sparse RAG,通过稀疏上下文选择加速检索增强生成推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 稀疏上下文选择 大型语言模型 推理加速 长文本生成
📋 核心要点
- 检索增强的LLM虽然性能强大,但随着检索文档数量增加,输入长度线性增长,导致推理延迟显著增加。
- Sparse RAG的核心思想是通过稀疏化上下文,并行编码检索文档,并仅关注高相关性的缓存进行解码,从而降低计算成本。
- 实验结果表明,Sparse RAG在生成质量和计算效率之间取得了平衡,并在短文本和长文本生成任务中表现出良好的泛化能力。
📝 摘要(中文)
本文提出了一种名为Sparse RAG的新范式,旨在通过稀疏性降低计算成本。Sparse RAG并行编码检索到的文档,消除了由检索文档的长程注意力引起的延迟。然后,LLM通过仅关注自回归方式选择的高度相关的缓存来选择性地解码输出,这些缓存通过使用特殊控制令牌提示LLM来选择。值得注意的是,Sparse RAG将每个单独文档的评估和响应的生成结合到一个过程中。RAG系统中设计的稀疏机制有助于减少解码期间加载的文档数量,从而加速RAG系统的推理。此外,过滤掉不需要的上下文可以增强模型对相关上下文的关注,从而从根本上提高其生成质量。在两个数据集上的评估结果表明,Sparse RAG可以在生成质量和计算效率之间取得最佳平衡,证明了其在短格式和长格式生成任务中的通用性。
🔬 方法详解
问题定义:现有检索增强生成(RAG)方法在推理阶段,需要处理大量检索到的文档,导致输入长度线性增长,从而显著增加了计算延迟,尤其是在长文本生成任务中。现有的RAG方法难以在生成质量和计算效率之间取得平衡。
核心思路:Sparse RAG的核心思路是通过引入稀疏性,减少解码过程中需要关注的上下文数量。具体来说,它并行编码所有检索到的文档,然后利用大型语言模型(LLM)选择性地关注最相关的上下文进行解码。这种方法避免了对所有检索文档进行长程注意力计算,从而降低了计算复杂度。
技术框架:Sparse RAG包含以下主要阶段:1) 并行编码:所有检索到的文档被并行编码成向量表示。2) 上下文选择:使用LLM和特殊的控制token,评估每个文档的相关性,并选择高相关性的文档作为缓存。3) 选择性解码:LLM仅关注选择的缓存进行自回归解码,生成最终的输出。
关键创新:Sparse RAG的关键创新在于将文档评估和响应生成集成到一个过程中,并引入了稀疏上下文选择机制。与传统的RAG方法不同,Sparse RAG不是简单地将所有检索到的文档都输入到LLM中,而是通过选择性地关注最相关的上下文来提高效率。
关键设计:Sparse RAG的关键设计包括:1) 控制Token:使用特殊的控制token来提示LLM评估每个文档的相关性。2) 并行编码:采用并行编码策略来减少编码延迟。3) 缓存机制:将选择的高相关性文档作为缓存,供LLM在解码阶段使用。具体的参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

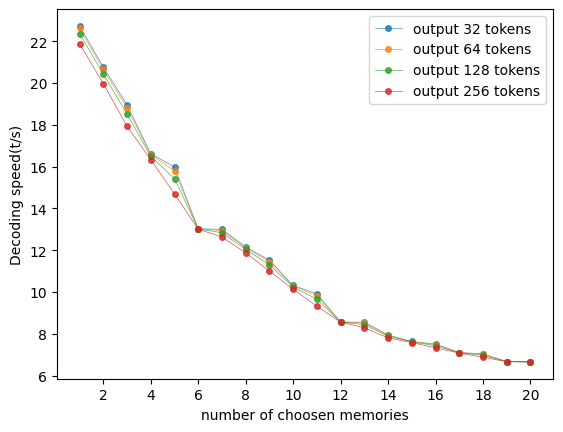
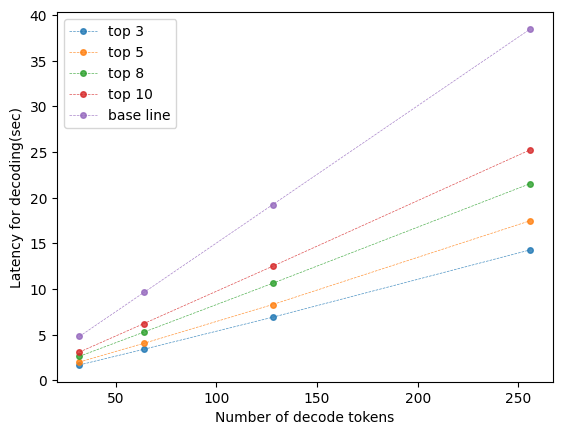
📊 实验亮点
论文在两个数据集上进行了评估,结果表明Sparse RAG可以在生成质量和计算效率之间取得最佳平衡。具体性能数据和对比基线在摘要中未提供,属于未知信息。但结论表明,Sparse RAG在短文本和长文本生成任务中都表现出良好的泛化能力。
🎯 应用场景
Sparse RAG具有广泛的应用前景,可以应用于问答系统、文本摘要、对话生成等领域。通过降低计算成本,Sparse RAG使得在资源受限的环境中部署RAG系统成为可能。此外,通过过滤掉不相关的上下文,Sparse RAG还可以提高生成质量,从而改善用户体验。
📄 摘要(原文)
Large language models (LLMs) augmented with retrieval exhibit robust performance and extensive versatility by incorporating external contexts. However, the input length grows linearly in the number of retrieved documents, causing a dramatic increase in latency. In this paper, we propose a novel paradigm named Sparse RAG, which seeks to cut computation costs through sparsity. Specifically, Sparse RAG encodes retrieved documents in parallel, which eliminates latency introduced by long-range attention of retrieved documents. Then, LLMs selectively decode the output by only attending to highly relevant caches auto-regressively, which are chosen via prompting LLMs with special control tokens. It is notable that Sparse RAG combines the assessment of each individual document and the generation of the response into a single process. The designed sparse mechanism in a RAG system can facilitate the reduction of the number of documents loaded during decoding for accelerating the inference of the RAG system. Additionally, filtering out undesirable contexts enhances the model's focus on relevant context, inherently improving its generation quality. Evaluation results of two datasets show that Sparse RAG can strike an optimal balance between generation quality and computational efficiency, demonstrating its generalizability across both short- and long-form generation tasks.