Incremental Comprehension of Garden-Path Sentences by Large Language Models: Semantic Interpretation, Syntactic Re-Analysis, and Attention
作者: Andrew Li, Xianle Feng, Siddhant Narang, Austin Peng, Tianle Cai, Raj Sanjay Shah, Sashank Varma
分类: cs.CL
发布日期: 2024-05-25
备注: Accepted by CogSci-24
💡 一句话要点
利用大型语言模型增量理解花园路径句:语义解释、句法重分析与注意力机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 花园路径句子 大型语言模型 语义理解 句法分析 注意力机制 心理语言学 歧义消除
📋 核心要点
- 花园路径句子的理解难点在于歧义消除后,最初的错误理解仍然存在,影响后续处理。
- 本文利用大型语言模型模拟人类对花园路径句子的理解过程,探究模型是否也会产生类似的持续误解。
- 实验结果表明,大型语言模型在处理花园路径句子时,与人类行为存在一定程度的对齐,尤其是在句法信息辅助下。
📝 摘要(中文)
本文研究了大型语言模型(LLMs)对花园路径句子的处理,以及在歧义消除后持续存在的误解。使用了GPT-2、LLaMA-2、Flan-T5和RoBERTa四个模型,旨在评估人类和LLMs在处理花园路径句子以及歧义消除后持续存在的误解方面是否一致,尤其是在存在额外的句法信息(例如,用于分隔从句边界的逗号)来指导处理时。使用了24个包含可选及物动词和反身动词的花园路径句子,这些句子会导致暂时的歧义。对于每个句子,都有一对对应于误解和正确理解的理解问题。通过三个实验,(1) 使用问答任务测量LLMs的动态语义解释;(2) 跟踪这些模型是否在歧义消除点(或句子结尾)改变其隐式解析树;(3) 可视化模型组件在处理问题探针时关注歧义消除信息的情况。实验表明,在处理花园路径句子方面,人类和LLMs之间存在着有希望的一致性,尤其是在有额外的句法信息来指导处理时。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在处理花园路径句子时,是否会像人类一样产生持续性的误解。现有方法主要集中在心理语言学实验,缺乏对LLMs内部处理机制的深入探究。
核心思路:核心思路是通过设计一系列针对花园路径句子的问答任务,来动态追踪LLMs对句子的语义理解过程,并分析模型在歧义消除点是否会调整其内部的句法解析树。同时,通过可视化注意力机制,探究模型如何关注句子中的关键信息。
技术框架:整体框架包含三个主要实验:(1) 动态语义解释测量:使用问答任务评估LLMs对句子不同阶段的理解;(2) 句法重分析追踪:观察模型在歧义消除点或句子结尾是否改变其隐式解析树;(3) 注意力机制可视化:分析模型在处理问题时,对句子中歧义消除信息的关注程度。
关键创新:关键创新在于将心理语言学中研究花园路径句子的方法引入到对LLMs的分析中,通过设计特定的实验来探究LLMs内部的语义理解和句法分析过程,从而揭示LLMs在处理歧义句子时的行为模式。
关键设计:实验中使用了24个包含可选及物动词和反身动词的花园路径句子,并为每个句子设计了对应于误解和正确理解的理解问题。通过分析模型在不同问题上的回答,以及注意力权重的分布,来评估模型的理解状态和处理机制。
🖼️ 关键图片

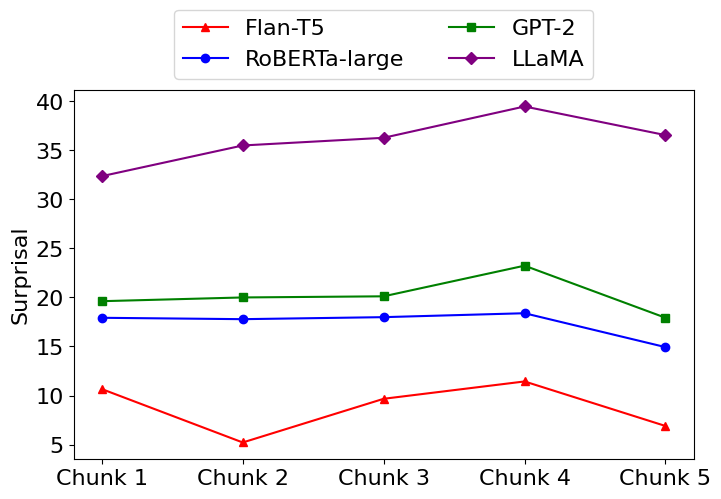

📊 实验亮点
实验结果表明,大型语言模型在处理花园路径句子时,与人类行为存在一定程度的对齐,尤其是在存在额外的句法信息(如逗号)来指导处理时。这表明LLMs能够利用句法信息来辅助语义理解,并减少歧义带来的误解。该研究为进一步探索LLMs的语言理解能力提供了有价值的证据。
🎯 应用场景
该研究有助于理解大型语言模型的语言理解机制,并为改进模型的自然语言处理能力提供指导。潜在应用包括提升机器翻译、文本摘要和对话系统等任务的性能,尤其是在处理复杂或歧义性语句时。此外,该研究也为心理语言学研究提供了新的视角,可以借助LLMs来模拟和验证人类的语言处理过程。
📄 摘要(原文)
When reading temporarily ambiguous garden-path sentences, misinterpretations sometimes linger past the point of disambiguation. This phenomenon has traditionally been studied in psycholinguistic experiments using online measures such as reading times and offline measures such as comprehension questions. Here, we investigate the processing of garden-path sentences and the fate of lingering misinterpretations using four large language models (LLMs): GPT-2, LLaMA-2, Flan-T5, and RoBERTa. The overall goal is to evaluate whether humans and LLMs are aligned in their processing of garden-path sentences and in the lingering misinterpretations past the point of disambiguation, especially when extra-syntactic information (e.g., a comma delimiting a clause boundary) is present to guide processing. We address this goal using 24 garden-path sentences that have optional transitive and reflexive verbs leading to temporary ambiguities. For each sentence, there are a pair of comprehension questions corresponding to the misinterpretation and the correct interpretation. In three experiments, we (1) measure the dynamic semantic interpretations of LLMs using the question-answering task; (2) track whether these models shift their implicit parse tree at the point of disambiguation (or by the end of the sentence); and (3) visualize the model components that attend to disambiguating information when processing the question probes. These experiments show promising alignment between humans and LLMs in the processing of garden-path sentences, especially when extra-syntactic information is available to guide processing.