Large Language Model Pruning
作者: Hanjuan Huang, Hao-Jia Song, Hsing-Kuo Pao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-05-24
备注: 17 pages, 7 figures, 2 tables
💡 一句话要点
提出一种基于互信息估计的大语言模型剪枝方法,提升模型解释性并降低计算资源需求。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 互信息估计 模型压缩 深度学习 可解释性 神经元冗余
📋 核心要点
- 大语言模型虽然性能优越,但存在过拟合、幻觉和设备限制等问题,需要有效的模型压缩方法。
- 论文提出基于互信息估计的剪枝方法,旨在消除冗余神经元,提高模型的可解释性和效率。
- 实验结果表明,该方法在大型模型上表现良好,且对剪枝标准的敏感度低于小型模型。
📝 摘要(中文)
近年来,更大的模型因其卓越的性能而备受欢迎,这得益于硬件和软件对这些超大型模型的支持。这些模型被广泛应用于文本挖掘等领域。特别地,大语言模型(LLMs)在文本理解和文本生成方面的成功吸引了NLP及相关领域研究人员的关注。然而,LLMs也面临着模型过拟合、幻觉以及设备限制等问题。本文提出了一种专门针对LLMs的模型剪枝技术。该方法强调深度学习模型的可解释性。通过理论基础,我们获得了一个可信赖的深度模型,从而使得拥有大量参数的庞大模型变得不再必要。采用基于互信息的估计来寻找冗余神经元并进行消除。此外,一个参数经过良好调整的估计器有助于找到精确的估计来指导剪枝过程。同时,我们还探讨了大规模模型剪枝与小规模模型剪枝之间的差异。剪枝标准的选择在小模型中很敏感,但在大规模模型中则不然。这是本文的一个新发现。总的来说,我们证明了所提出的模型优于最先进的模型。
🔬 方法详解
问题定义:现有大语言模型参数量巨大,导致计算资源消耗高昂,同时模型可解释性较差,容易出现过拟合和幻觉问题。传统的模型剪枝方法可能无法有效应用于大规模模型,且对剪枝标准的敏感度较高。
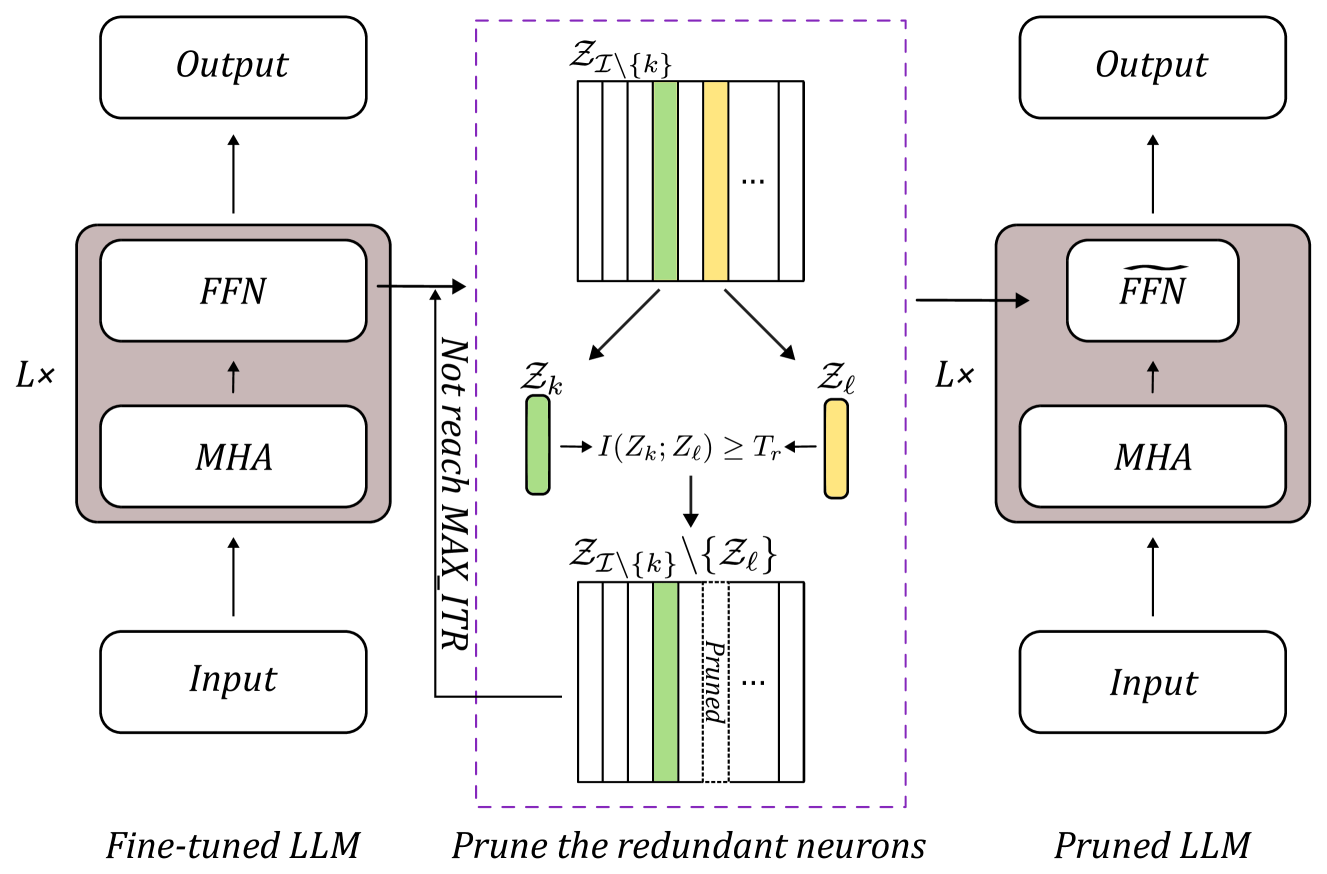
核心思路:论文的核心思路是通过互信息估计来识别和消除模型中的冗余神经元。互信息能够衡量两个随机变量之间的依赖程度,因此可以用于评估神经元之间的信息冗余度。通过剪除冗余神经元,可以在不显著降低模型性能的前提下,减小模型规模,提高模型效率和可解释性。
技术框架:该方法主要包含以下几个阶段:1) 互信息估计:计算模型中神经元之间的互信息。2) 冗余神经元识别:基于互信息值,识别出冗余的神经元。3) 模型剪枝:移除识别出的冗余神经元。4) 模型微调:对剪枝后的模型进行微调,以恢复模型性能。
关键创新:该方法的关键创新在于将互信息估计应用于大语言模型的剪枝,并发现剪枝标准的选择在大规模模型和小规模模型上的敏感度差异。以往的剪枝方法可能更多依赖于权重大小或梯度等指标,而忽略了神经元之间的信息冗余关系。
关键设计:论文采用了一种精心调整参数的估计器来指导剪枝过程,以获得更精确的互信息估计。具体的参数设置和网络结构细节在论文中可能没有详细描述,需要进一步查阅论文原文。损失函数的设计可能包括对剪枝后模型性能的约束,以避免性能大幅下降。
🖼️ 关键图片

📊 实验亮点
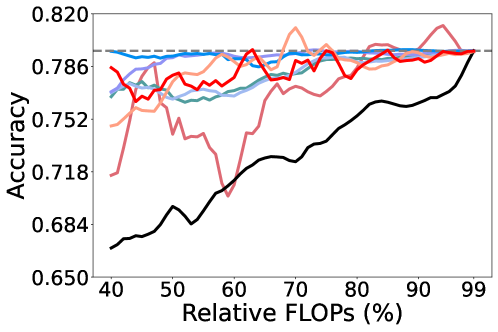
论文通过实验证明了所提出的剪枝方法在大型模型上的有效性,并观察到与小型模型不同的剪枝行为。具体性能数据(如压缩率、精度损失等)以及与现有方法的对比结果需要在论文中查找。该研究强调了剪枝标准选择对不同规模模型的影响。
🎯 应用场景
该研究成果可应用于各种需要部署大语言模型的场景,例如移动设备、边缘计算等资源受限的环境。通过模型剪枝,可以降低模型大小和计算复杂度,使其更易于部署和应用。此外,该方法还有助于提高模型的可解释性,从而增强用户对模型的信任度。
📄 摘要(原文)
We surely enjoy the larger the better models for their superior performance in the last couple of years when both the hardware and software support the birth of such extremely huge models. The applied fields include text mining and others. In particular, the success of LLMs on text understanding and text generation draws attention from researchers who have worked on NLP and related areas for years or even decades. On the side, LLMs may suffer from problems like model overfitting, hallucination, and device limitation to name a few. In this work, we suggest a model pruning technique specifically focused on LLMs. The proposed methodology emphasizes the explainability of deep learning models. By having the theoretical foundation, we obtain a trustworthy deep model so that huge models with a massive number of model parameters become not quite necessary. A mutual information-based estimation is adopted to find neurons with redundancy to eliminate. Moreover, an estimator with well-tuned parameters helps to find precise estimation to guide the pruning procedure. At the same time, we also explore the difference between pruning on large-scale models vs. pruning on small-scale models. The choice of pruning criteria is sensitive in small models but not for large-scale models. It is a novel finding through this work. Overall, we demonstrate the superiority of the proposed model to the state-of-the-art models.