Clustered Retrieved Augmented Generation (CRAG)
作者: Simon Akesson, Frances A. Santos
分类: cs.CL, cs.AI
发布日期: 2024-05-24
💡 一句话要点
提出CRAG:一种聚类检索增强生成方法,有效降低LLM提示token数量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大型语言模型 聚类算法 上下文压缩 知识检索
📋 核心要点
- 现有RAG方法在处理大量外部知识时,面临LLM上下文窗口限制和token数量过多的挑战,导致成本高昂和处理速度慢。
- CRAG的核心思想是通过聚类检索到的文档,选择最具代表性的簇,从而减少输入LLM的token数量,同时保持信息质量。
- 实验结果表明,CRAG在降低token数量方面表现出色,最高可减少90%以上,且在高评论数量场景下,token增长幅度远低于RAG。
📝 摘要(中文)
为了在实际应用中使用大型语言模型(LLM),向其提供外部知识至关重要,这有助于实时整合最新内容、访问特定领域的知识并防止幻觉。基于向量数据库的检索增强生成(RAG)方法已被广泛采用。通过RAG,外部知识可以被检索并作为输入上下文提供给LLM。尽管RAG方法取得了成功,但对于某些应用而言,它仍然可能不可行,因为检索到的上下文可能需要比LLM支持的更长的上下文窗口。即使检索到的上下文适合上下文窗口大小,token的数量也可能很大,从而影响成本和处理时间,这对于大多数应用来说是不切实际的。为了解决这些问题,我们提出了一种新颖的方法CRAG,与使用RAG的解决方案相比,它能够有效地减少提示token的数量,而不会降低生成的响应的质量。通过我们的实验,我们表明,与RAG相比,CRAG可以减少至少46%的token数量,在某些情况下甚至可以减少90%以上。此外,与RAG不同,当分析的评论数量较高时,CRAG的token数量不会显着增加,而当有75条评论时,RAG的token数量几乎是4条评论时的9倍。
🔬 方法详解
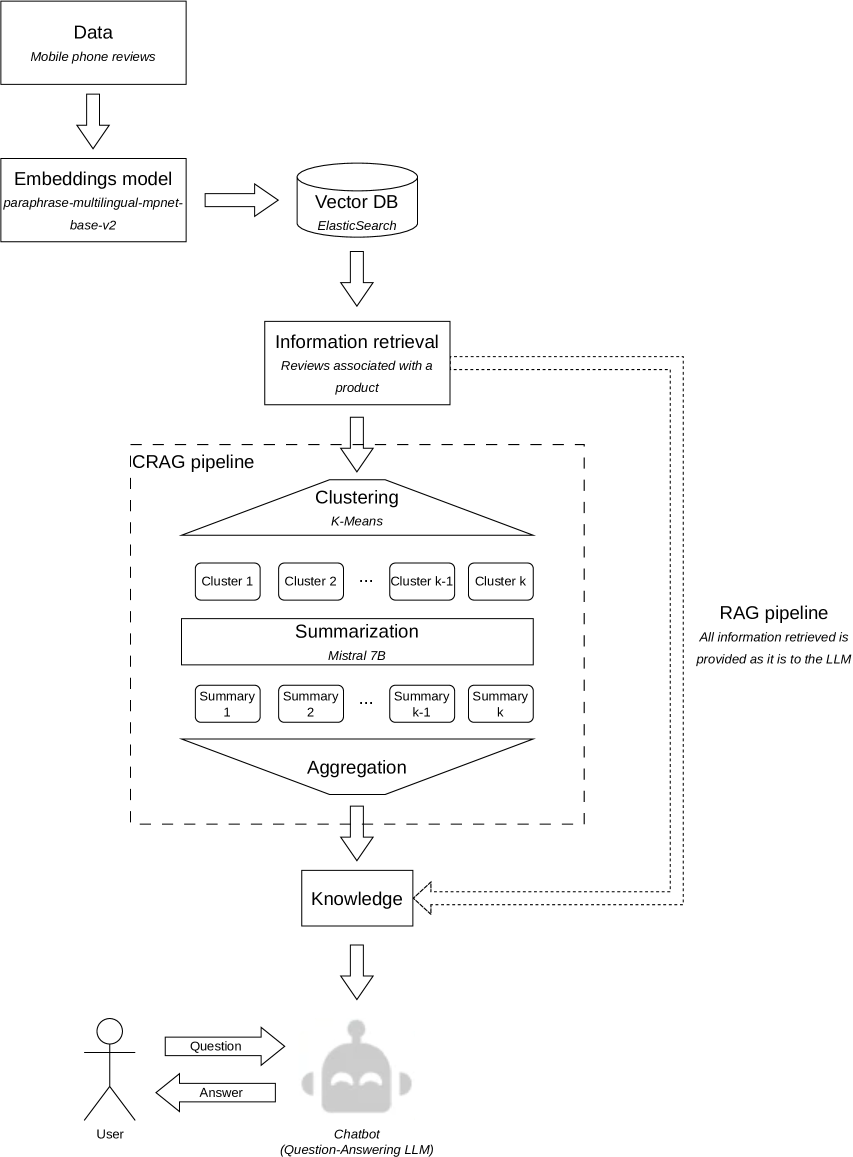
问题定义:论文旨在解决RAG方法在处理大量外部知识时,由于LLM上下文窗口限制和token数量过多而导致的成本高昂和处理速度慢的问题。现有RAG方法直接将检索到的所有文档作为上下文输入LLM,造成冗余和效率低下。
核心思路:CRAG的核心思路是在将检索到的文档输入LLM之前,先对这些文档进行聚类,然后从每个簇中选择最具代表性的文档作为上下文。这样可以减少输入LLM的token数量,同时保留关键信息,从而提高效率并降低成本。
技术框架:CRAG的整体框架包括以下几个主要阶段:1) 使用向量数据库进行文档检索;2) 对检索到的文档进行聚类;3) 从每个簇中选择最具代表性的文档;4) 将选择的文档作为上下文输入LLM,生成最终答案。
关键创新:CRAG最重要的技术创新点在于引入了聚类步骤,对检索到的文档进行筛选和压缩,从而显著减少了输入LLM的token数量。与传统的RAG方法相比,CRAG能够更有效地利用LLM的上下文窗口,提高处理效率。
关键设计:论文中没有明确说明具体的聚类算法选择或参数设置。但是,选择合适的聚类算法(例如K-means、DBSCAN等)以及确定簇的数量是影响CRAG性能的关键因素。此外,如何选择每个簇中最具代表性的文档(例如,选择距离簇中心最近的文档)也是一个重要的设计考虑。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CRAG在降低token数量方面表现出色,与RAG相比,CRAG可以减少至少46%的token数量,在某些情况下甚至可以减少90%以上。此外,在高评论数量场景下(75条评论),CRAG的token增长幅度远低于RAG,显示出更好的可扩展性。
🎯 应用场景
CRAG方法可广泛应用于需要处理大量外部知识的LLM应用场景,例如问答系统、文档摘要、知识库构建等。通过降低token数量,CRAG可以显著降低运营成本,提高处理速度,使得LLM能够更高效地应用于实际业务中,尤其是在处理海量用户评论或大规模文档集合时。
📄 摘要(原文)
Providing external knowledge to Large Language Models (LLMs) is a key point for using these models in real-world applications for several reasons, such as incorporating up-to-date content in a real-time manner, providing access to domain-specific knowledge, and contributing to hallucination prevention. The vector database-based Retrieval Augmented Generation (RAG) approach has been widely adopted to this end. Thus, any part of external knowledge can be retrieved and provided to some LLM as the input context. Despite RAG approach's success, it still might be unfeasible for some applications, because the context retrieved can demand a longer context window than the size supported by LLM. Even when the context retrieved fits into the context window size, the number of tokens might be expressive and, consequently, impact costs and processing time, becoming impractical for most applications. To address these, we propose CRAG, a novel approach able to effectively reduce the number of prompting tokens without degrading the quality of the response generated compared to a solution using RAG. Through our experiments, we show that CRAG can reduce the number of tokens by at least 46\%, achieving more than 90\% in some cases, compared to RAG. Moreover, the number of tokens with CRAG does not increase considerably when the number of reviews analyzed is higher, unlike RAG, where the number of tokens is almost 9x higher when there are 75 reviews compared to 4 reviews.