Zero-Shot Spam Email Classification Using Pre-trained Large Language Models
作者: Sergio Rojas-Galeano
分类: cs.CL, cs.AI
发布日期: 2024-05-24
期刊: Applied Computer Sciences in Engineering. WEA 2024. Communications in Computer and Information Science, vol 2222. Springer, Cham
DOI: 10.1007/978-3-031-74595-9_1
💡 一句话要点
利用预训练大语言模型进行零样本垃圾邮件分类
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 垃圾邮件分类 预训练语言模型 零样本学习 自然语言处理 文本分类
📋 核心要点
- 现有垃圾邮件分类方法需要大量标注数据进行训练,泛化能力有限,难以适应不断变化的垃圾邮件内容。
- 本文提出利用预训练大语言模型强大的文本理解和生成能力,通过零样本提示直接进行垃圾邮件分类,无需额外训练。
- 实验结果表明,Flan-T5和GPT-4在SpamAssassin数据集上取得了优秀的零样本分类效果,F1分数分别达到90%和95%。
📝 摘要(中文)
本文研究了使用预训练大语言模型(LLMs)通过零样本提示进行垃圾邮件分类的应用。我们评估了开源模型(Flan-T5)和专有模型(ChatGPT、GPT-4)在著名的SpamAssassin数据集上的性能。探索了两种分类方法:(1)截断邮件主题和正文的原始内容,(2)基于ChatGPT生成的摘要进行分类。我们的实证分析利用整个数据集进行评估,无需进一步训练,结果显示出良好的潜力。Flan-T5在截断内容方法上实现了90%的F1分数,而GPT-4在使用摘要时达到了95%的F1分数。虽然这些在单个数据集上的初步发现表明了基于LLM的子任务(例如,摘要和分类)的分类管道的潜力,但有必要在不同的数据集上进行进一步验证。专有模型的高运营成本,加上LLM的一般推理成本,可能会严重阻碍垃圾邮件过滤的实际部署。
🔬 方法详解
问题定义:本文旨在解决垃圾邮件分类问题,现有方法主要依赖于监督学习,需要大量标注数据,并且难以适应新型垃圾邮件的出现。因此,如何在缺乏标注数据的情况下,利用现有模型进行有效的垃圾邮件分类是一个挑战。
核心思路:本文的核心思路是利用预训练大语言模型(LLMs)的零样本学习能力。LLMs在大量文本数据上进行预训练,具备强大的文本理解和生成能力,可以通过简单的提示(prompt)直接完成下游任务,而无需额外的训练。
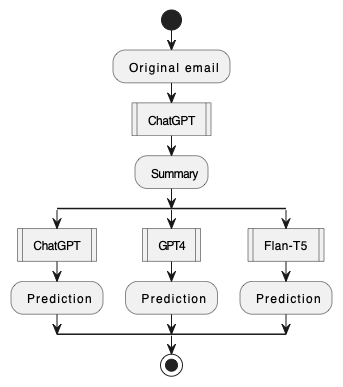
技术框架:本文的整体框架包括两个主要步骤:首先,对原始邮件内容进行处理,包括直接截断邮件主题和正文,或者使用ChatGPT生成邮件摘要;然后,将处理后的文本输入到LLM中,通过零样本提示进行垃圾邮件分类。LLM直接输出分类结果(垃圾邮件或非垃圾邮件)。
关键创新:本文的关键创新在于将预训练大语言模型应用于零样本垃圾邮件分类。与传统的监督学习方法相比,该方法无需标注数据,可以快速适应新的垃圾邮件类型。此外,本文还探索了两种不同的文本处理方法(截断和摘要),并比较了不同LLM的性能。
关键设计:本文的关键设计包括:1) 使用SpamAssassin数据集进行评估;2) 采用两种不同的LLM:开源的Flan-T5和专有的ChatGPT、GPT-4;3) 设计了两种不同的输入方式:直接截断邮件内容和使用ChatGPT生成摘要;4) 使用F1分数作为评估指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,预训练大语言模型在零样本垃圾邮件分类任务中表现出色。Flan-T5在截断内容方法上实现了90%的F1分数,而GPT-4在使用ChatGPT生成的摘要时达到了95%的F1分数。这些结果表明,LLM具有强大的零样本学习能力,可以有效解决垃圾邮件分类问题。
🎯 应用场景
该研究成果可应用于智能邮件过滤系统,无需大量标注数据即可快速部署和更新,有效识别新型垃圾邮件。此外,该方法也可扩展到其他文本分类任务,如情感分析、主题分类等,具有广泛的应用前景。然而,实际部署需要考虑LLM的推理成本和专有模型的运营成本。
📄 摘要(原文)
This paper investigates the application of pre-trained large language models (LLMs) for spam email classification using zero-shot prompting. We evaluate the performance of both open-source (Flan-T5) and proprietary LLMs (ChatGPT, GPT-4) on the well-known SpamAssassin dataset. Two classification approaches are explored: (1) truncated raw content from email subject and body, and (2) classification based on summaries generated by ChatGPT. Our empirical analysis, leveraging the entire dataset for evaluation without further training, reveals promising results. Flan-T5 achieves a 90% F1-score on the truncated content approach, while GPT-4 reaches a 95% F1-score using summaries. While these initial findings on a single dataset suggest the potential for classification pipelines of LLM-based subtasks (e.g., summarisation and classification), further validation on diverse datasets is necessary. The high operational costs of proprietary models, coupled with the general inference costs of LLMs, could significantly hinder real-world deployment for spam filtering.