EmpathicStories++: A Multimodal Dataset for Empathy towards Personal Experiences
作者: Jocelyn Shen, Yubin Kim, Mohit Hulse, Wazeer Zulfikar, Sharifa Alghowinem, Cynthia Breazeal, Hae Won Park
分类: cs.CL
发布日期: 2024-05-24
备注: Accepted to ACL 2024 Findings
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出EmpathicStories++多模态数据集,用于建模AI对个人经历的共情能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 共情建模 多模态数据集 纵向研究 人机交互 情感计算
📋 核心要点
- 现有共情数据集缺乏真实场景、纵向数据和自报告标签,难以捕捉共情反应的丰富性。
- EmpathicStories++数据集通过在参与者家中部署社交机器人,收集自然、真实的共情故事讲述互动数据。
- 论文提出基于个人经历预测共情程度的新任务,并使用SOTA模型进行基准测试,为未来研究提供参考。
📝 摘要(中文)
本文介绍了一个新的多模态数据集EmpathicStories++,用于研究AI在个人经历分享中的共情能力。该数据集包含41名参与者与AI智能体进行自然、共情的故事讲述互动,共计53小时的视频、音频和文本数据。数据采集历时一个月,是首个关于共情的纵向数据集。参与者分享个人经历,并阅读与AI智能体产生共鸣的故事。此外,论文还提出了一个新任务:基于个人经历预测个体对他人故事的共情程度,并在参与者自身故事和他们阅读的故事反思两个情境下进行评估。论文使用最先进的模型对该任务进行了基准测试,为未来在情境化和纵向共情建模方面的改进奠定了基础。这项工作为进一步研究开发共情AI系统以及理解真实世界环境中人类共情的复杂性提供了宝贵的资源。
🔬 方法详解
问题定义:现有共情数据集主要存在以下痛点:一是数据采集场景受限,多为实验室环境或表演场景,缺乏真实性;二是缺乏纵向数据,难以捕捉共情随时间的变化;三是缺乏自报告标签,难以准确评估共情程度。因此,如何构建一个更真实、更全面的共情数据集,并在此基础上开发更具共情能力的AI系统,是一个重要的研究问题。
核心思路:论文的核心思路是通过在参与者家中部署社交机器人,收集参与者与AI智能体进行自然、共情的故事讲述互动数据。这种方式能够模拟真实世界中的人际互动场景,捕捉到更自然、更丰富的共情表达。同时,通过长达一个月的纵向数据采集,可以观察到共情随时间的变化趋势。
技术框架:EmpathicStories++数据集的构建流程主要包括以下几个阶段:1) 招募参与者,并将其社交机器人部署到家中;2) 参与者与AI智能体进行故事讲述互动,包括分享个人经历和阅读共情故事;3) 收集参与者的视频、音频和文本数据;4) 对数据进行标注,包括共情程度、情感状态等;5) 基于数据集,提出基于个人经历预测共情程度的新任务,并使用SOTA模型进行基准测试。
关键创新:该论文的关键创新点在于:1) 提出了EmpathicStories++数据集,是首个关于共情的纵向多模态数据集;2) 提出了基于个人经历预测共情程度的新任务,为共情建模提供了新的思路;3) 在真实家庭环境中收集数据,保证了数据的真实性和自然性。
关键设计:在数据采集过程中,论文设计了一系列引导问题,鼓励参与者分享个人经历和表达情感。同时,为了保证数据的质量,论文对参与者进行了培训,并对数据进行了严格的审核。在模型训练方面,论文使用了多种SOTA模型,并针对共情预测任务进行了优化。具体的参数设置、损失函数和网络结构等细节未在论文中详细描述,属于未知信息。
🖼️ 关键图片
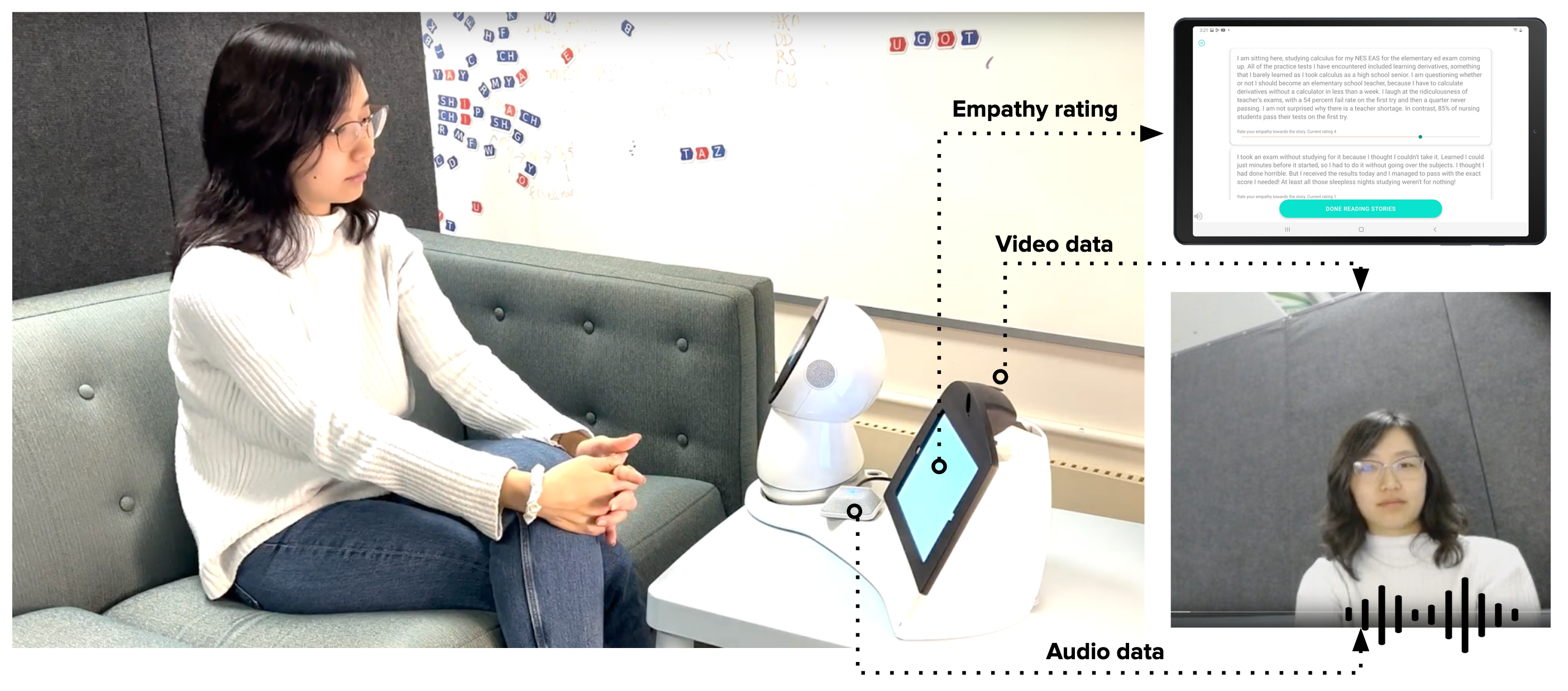


📊 实验亮点
论文构建了包含53小时视频、音频和文本数据的EmpathicStories++数据集,是首个关于共情的纵向数据集。论文提出了基于个人经历预测共情程度的新任务,并使用SOTA模型进行了基准测试,为未来的研究提供了参考基线。具体的性能数据和提升幅度未在摘要中明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于开发更具共情能力的AI系统,例如情感陪伴机器人、心理咨询助手等。这些系统能够更好地理解人类的情感需求,提供更个性化、更有效的服务。此外,该数据集也可用于研究人类共情的机制,为心理学、社会学等领域的研究提供参考。
📄 摘要(原文)
Modeling empathy is a complex endeavor that is rooted in interpersonal and experiential dimensions of human interaction, and remains an open problem within AI. Existing empathy datasets fall short in capturing the richness of empathy responses, often being confined to in-lab or acted scenarios, lacking longitudinal data, and missing self-reported labels. We introduce a new multimodal dataset for empathy during personal experience sharing: the EmpathicStories++ dataset (https://mitmedialab.github.io/empathic-stories-multimodal/) containing 53 hours of video, audio, and text data of 41 participants sharing vulnerable experiences and reading empathically resonant stories with an AI agent. EmpathicStories++ is the first longitudinal dataset on empathy, collected over a month-long deployment of social robots in participants' homes, as participants engage in natural, empathic storytelling interactions with AI agents. We then introduce a novel task of predicting individuals' empathy toward others' stories based on their personal experiences, evaluated in two contexts: participants' own personal shared story context and their reflections on stories they read. We benchmark this task using state-of-the-art models to pave the way for future improvements in contextualized and longitudinal empathy modeling. Our work provides a valuable resource for further research in developing empathetic AI systems and understanding the intricacies of human empathy within genuine, real-world settings.