GECKO: Generative Language Model for English, Code and Korean
作者: Sungwoo Oh, Donggyu Kim
分类: cs.CL, cs.AI
发布日期: 2024-05-24
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
GECKO:面向英语、代码和韩语的生成式语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 韩语 英语 代码生成 双语模型
📋 核心要点
- 现有LLM在韩语和英语以及代码的平衡处理上存在挑战,GECKO旨在弥补这一差距。
- GECKO基于LLaMA架构,通过构建高质量的韩英双语语料库进行预训练,优化模型性能。
- 实验表明,GECKO在韩语基准测试中表现出色,并在英语和代码方面也取得了不错的性能。
📝 摘要(中文)
本文介绍了GECKO,一个针对韩语和英语以及编程语言优化的双语大型语言模型(LLM)。GECKO基于LLaMA架构,在一个平衡且高质量的韩语和英语语料库上进行预训练。本文分享了为构建更好的语料库数据管道和训练模型所做的努力的经验。尽管词汇量较小,GECKO在韩语和英语的token生成方面都表现出很高的效率。我们在韩语、英语和代码的代表性基准上测量了性能,结果表明它在KMMLU(韩语MMLU)上表现出色,在英语和代码方面表现适中,即使与以英语为中心的LLM相比,其训练的token数量也更少。GECKO在宽松许可下向开源社区开放。我们希望我们的工作为韩语LLM研究提供研究基线和实践见解。该模型可在https://huggingface.co/kifai/GECKO-7B 找到。
🔬 方法详解
问题定义:现有的大型语言模型通常侧重于英语,对韩语等其他语言的支持不足,或者在代码生成方面表现不佳。GECKO旨在解决这一问题,构建一个能够同时处理英语、韩语和代码的高效LLM。
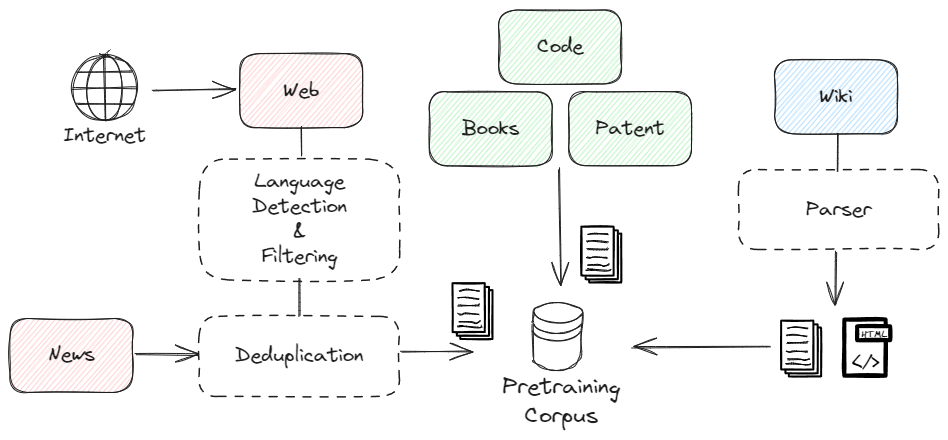
核心思路:GECKO的核心思路是利用LLaMA架构,并构建一个高质量、平衡的韩英双语语料库进行预训练。通过这种方式,模型能够学习到英语和韩语之间的关联,并提升在两种语言上的性能。同时,加入代码数据,使模型具备代码生成能力。
技术框架:GECKO的整体框架基于LLaMA架构,包括Transformer解码器层。预训练阶段使用构建好的韩英双语和代码语料库。模型训练完成后,在各种基准测试上进行评估。
关键创新:GECKO的关键创新在于其高质量、平衡的韩英双语语料库的构建,以及针对韩语和英语token生成效率的优化。此外,GECKO在较小的模型规模下,在韩语基准测试中取得了优异的成绩,证明了其高效性。
关键设计:GECKO采用了LLaMA的架构,具体参数设置未知。论文重点介绍了语料库的构建过程,但未详细描述损失函数和网络结构等技术细节。模型大小为7B参数,在Hugging Face上开源。
🖼️ 关键图片
📊 实验亮点
GECKO在KMMLU(韩语MMLU)基准测试中表现出色,证明了其在韩语理解和生成方面的强大能力。虽然在英语和代码方面的性能与专门针对英语训练的LLM相比略有差距,但考虑到其较小的模型规模和训练数据量,GECKO仍然展现了良好的性能。
🎯 应用场景
GECKO的应用场景广泛,包括机器翻译、文本摘要、代码生成、问答系统等。尤其在韩语相关的应用中,GECKO具有很大的潜力。该模型可以作为研究基线,促进韩语LLM的发展,并为实际应用提供支持。
📄 摘要(原文)
We introduce GECKO, a bilingual large language model (LLM) optimized for Korean and English, along with programming languages. GECKO is pretrained on the balanced, high-quality corpus of Korean and English employing LLaMA architecture. In this report, we share the experiences of several efforts to build a better data pipeline for the corpus and to train our model. GECKO shows great efficiency in token generations for both Korean and English, despite its small size of vocabulary. We measure the performance on the representative benchmarks in terms of Korean, English and Code, and it exhibits great performance on KMMLU (Korean MMLU) and modest performance in English and Code, even with its smaller number of trained tokens compared to English-focused LLMs. GECKO is available to the open-source community under a permissive license. We hope our work offers a research baseline and practical insights for Korean LLM research. The model can be found at: https://huggingface.co/kifai/GECKO-7B