Benchmarking the Performance of Pre-trained LLMs across Urdu NLP Tasks
作者: Munief Hassan Tahir, Sana Shams, Layba Fiaz, Farah Adeeba, Sarmad Hussain
分类: cs.CL, cs.AI
发布日期: 2024-05-24 (更新: 2024-12-31)
💡 一句话要点
评估预训练LLM在乌尔都语NLP任务上的性能,揭示模型能力与语言覆盖度的关系。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 乌尔都语NLP 大型语言模型 零样本学习 性能评估 多语言模型
📋 核心要点
- 现有LLM多语言评测benchmark缺乏语言多样性,且缺少与SOTA模型的质量对比。
- 通过在乌尔都语NLP任务上评估多个LLM,分析模型性能与语言覆盖度的关系。
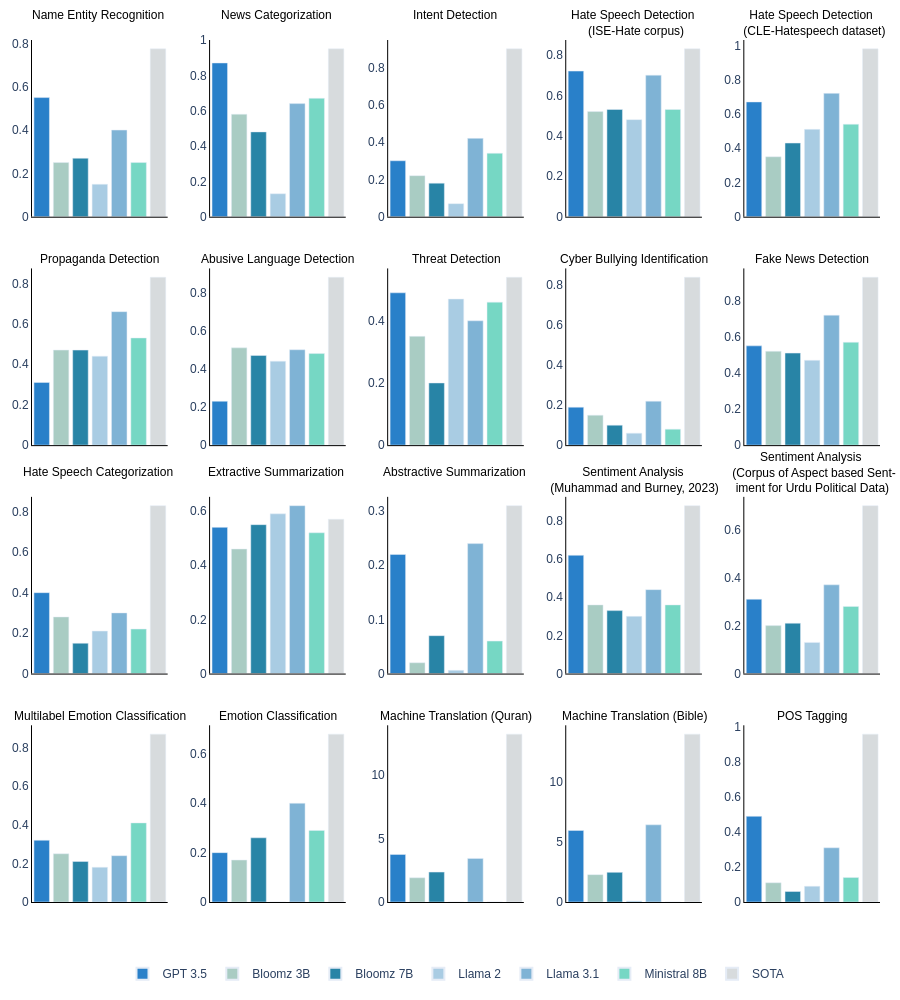
- 实验表明,SOTA模型在零样本乌尔都语NLP任务中优于encoder-decoder模型,且语言覆盖度高的LLM表现更优。
📝 摘要(中文)
大型语言模型(LLM)在多语言数据上的预训练彻底改变了自然语言处理研究,它将特定于语言和任务的模型管道转变为适应各种任务的单一模型。然而,现有的LLM多语言NLP基准测试大多只提供少数几种语言的评估数据,语言多样性不足。此外,这些基准测试缺乏针对各自最先进模型的质量评估。本研究深入考察了7个著名的LLM:GPT-3.5-turbo、Llama 2-7B-Chat、Llama 3.1-8B、Bloomz 3B、Bloomz 7B1、Ministral-8B和Whisper(大型、中型和小型变体),在零样本设置下,使用22个数据集的17个任务和13.8小时的语音数据,并将其性能与最先进(SOTA)模型进行了比较和分析。实验表明,目前SOTA模型在大多数乌尔都语NLP任务中,在零样本设置下优于encoder-decoder模型。然而,通过比较Llama 3.1-8B和之前的版本Llama 2-7B-Chat,我们可以推断,通过改进语言覆盖范围,LLM可以超越这些SOTA模型。我们的结果强调,具有较少参数但更丰富的特定语言数据的模型,如Llama 3.1-8B,在某些任务中通常优于具有较低语言多样性的大型模型,如GPT-3.5。
🔬 方法详解
问题定义:论文旨在评估现有大型语言模型(LLM)在乌尔都语自然语言处理(NLP)任务上的性能。现有方法的痛点在于,多语言LLM的评估基准缺乏对乌尔都语等低资源语言的充分覆盖,并且缺乏与专门针对乌尔都语开发的SOTA模型的直接比较。这使得难以准确评估LLM在这些语言上的泛化能力和实际应用潜力。
核心思路:论文的核心思路是通过构建一个包含多个乌尔都语NLP任务的基准测试集,并在零样本设置下评估多个主流LLM的性能。通过将LLM的性能与专门针对乌尔都语开发的SOTA模型进行比较,可以更清晰地了解LLM在处理低资源语言时的优势和局限性。此外,通过比较不同LLM的性能,可以分析模型大小、训练数据和语言覆盖度等因素对性能的影响。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集和整理乌尔都语NLP数据集,涵盖17个任务和22个数据集,以及13.8小时的语音数据。2) 选择7个主流LLM进行评估,包括GPT-3.5-turbo、Llama 2-7B-Chat、Llama 3.1-8B、Bloomz 3B、Bloomz 7B1、Ministral-8B和Whisper。3) 在零样本设置下,使用整理好的数据集对LLM进行评估。4) 将LLM的性能与专门针对乌尔都语开发的SOTA模型进行比较。5) 分析实验结果,探讨模型大小、训练数据和语言覆盖度等因素对性能的影响。
关键创新:该研究的关键创新在于:1) 构建了一个相对全面的乌尔都语NLP基准测试集,涵盖了多个任务和数据集。2) 在零样本设置下,将多个主流LLM与专门针对乌尔都语开发的SOTA模型进行了直接比较。3) 分析了模型大小、训练数据和语言覆盖度等因素对LLM在低资源语言上的性能影响。与现有方法的本质区别在于,该研究更关注LLM在低资源语言上的实际性能,并提供了更细致的性能分析。
关键设计:论文的关键设计包括:1) 选择了零样本设置,以评估LLM的泛化能力。2) 选择了多个具有代表性的LLM,涵盖了不同的大小和架构。3) 选择了多个具有代表性的乌尔都语NLP任务,涵盖了不同的应用场景。4) 使用了标准的评估指标,如准确率、F1值等,以确保结果的可比性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在零样本设置下,专门针对乌尔都语开发的SOTA模型在大多数任务中优于LLM。然而,Llama 3.1-8B在某些任务上表现出色,超越了Llama 2-7B-Chat,表明通过改进语言覆盖范围,LLM可以超越SOTA模型。此外,研究发现,具有较少参数但更丰富的特定语言数据的模型,如Llama 3.1-8B,在某些任务中通常优于具有较低语言多样性的大型模型,如GPT-3.5。
🎯 应用场景
该研究成果可应用于改进乌尔都语NLP应用,例如机器翻译、文本摘要、情感分析和语音识别等。通过选择更适合乌尔都语的LLM或改进现有LLM的训练数据,可以提高这些应用的性能。此外,该研究也为其他低资源语言的NLP研究提供了参考。
📄 摘要(原文)
Large Language Models (LLMs) pre-trained on multilingual data have revolutionized natural language processing research, by transitioning from languages and task specific model pipelines to a single model adapted on a variety of tasks. However majority of existing multilingual NLP benchmarks for LLMs provide evaluation data in only few languages with little linguistic diversity. In addition these benchmarks lack quality assessment against the respective state-of the art models. This study presents an in-depth examination of 7 prominent LLMs: GPT-3.5-turbo, Llama 2-7B-Chat, Llama 3.1-8B, Bloomz 3B, Bloomz 7B1, Ministral-8B and Whisper (Large, medium and small variant) across 17 tasks using 22 datasets, 13.8 hours of speech, in a zero-shot setting, and their performance against state-of-the-art (SOTA) models, has been compared and analyzed. Our experiments show that SOTA models currently outperform encoder-decoder models in majority of Urdu NLP tasks under zero-shot settings. However, comparing Llama 3.1-8B over prior version Llama 2-7B-Chat, we can deduce that with improved language coverage, LLMs can surpass these SOTA models. Our results emphasize that models with fewer parameters but richer language-specific data, like Llama 3.1-8B, often outperform larger models with lower language diversity, such as GPT-3.5, in several tasks.