Everything is Editable: Extend Knowledge Editing to Unstructured Data in Large Language Models
作者: Jingcheng Deng, Zihao Wei, Liang Pang, Hanxing Ding, Huawei Shen, Xueqi Cheng
分类: cs.CL
发布日期: 2024-05-24 (更新: 2025-02-25)
备注: ICLR 2025
💡 一句话要点
UnKE:扩展知识编辑至大语言模型中的非结构化数据
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识编辑 非结构化数据 大语言模型 键值存储 因果驱动优化
📋 核心要点
- 现有知识编辑方法难以有效处理大语言模型中长文本、含噪声的非结构化知识。
- UnKE通过非局部块键值存储增强知识表示,并采用因果驱动优化避免术语定位和上下文丢失。
- UnKE在非结构化知识编辑数据集UnKEBench和结构化数据集上均超越现有基线,并支持批量和顺序编辑。
📝 摘要(中文)
现有的知识编辑方法主要集中于修改大语言模型中的结构化知识。然而,这种设置忽略了大量真实世界知识以非结构化形式存储的事实,这些知识具有长文本、噪声和复杂但全面的特点。诸如“局部层键值存储”和“术语驱动优化”等技术,在处理非结构化知识时效果不佳。为了应对这些挑战,我们提出了一种新的非结构化知识编辑方法UnKE,它扩展了先前方法在层维度和token维度上的假设。首先,在层维度上,我们提出非局部块键值存储来替代局部层键值存储,从而提高键值对的表示能力并整合注意力层知识。其次,在token维度上,我们用“因果驱动优化”代替“术语驱动优化”,直接编辑最后一个token,同时保留上下文,避免了定位术语的需要,并防止了上下文信息的丢失。在新提出的非结构化知识编辑数据集(UnKEBench)和传统的结构化数据集上的结果表明,UnKE取得了显著的性能,超过了强大的基线模型。此外,UnKE具有强大的批量编辑和顺序编辑能力。
🔬 方法详解
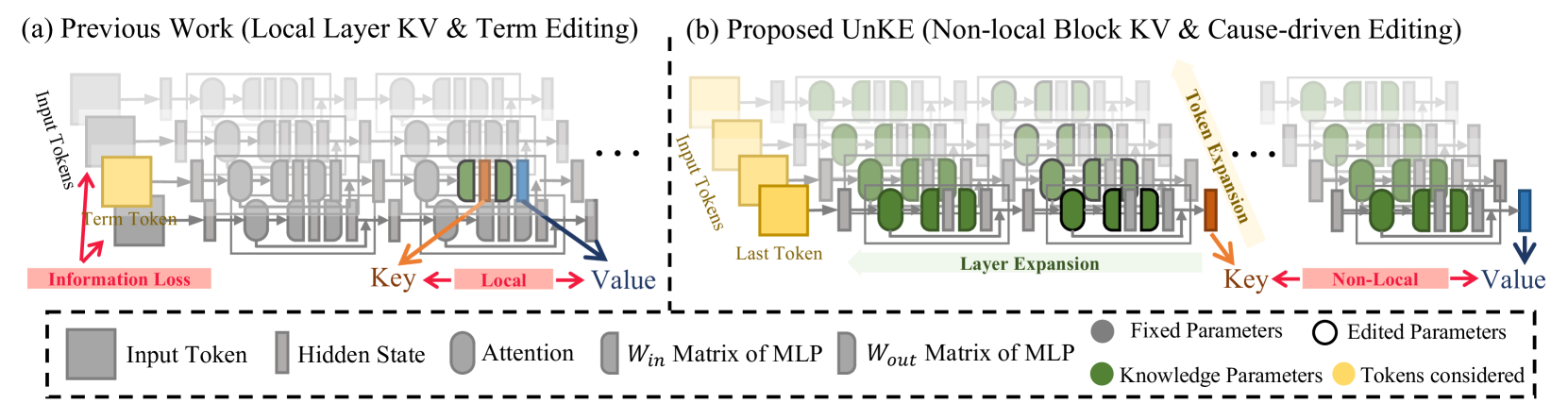
问题定义:现有知识编辑方法主要针对结构化数据,如知识图谱中的三元组。然而,现实世界中大量的知识以非结构化的形式存在,例如文档、网页等。这些非结构化数据具有长文本、噪声多、信息复杂的特点,传统的局部层键值存储和术语驱动优化方法难以有效处理,容易造成上下文信息丢失和编辑不准确。
核心思路:UnKE的核心思路是扩展知识编辑的范围,使其能够有效地处理非结构化数据。具体来说,它从层维度和token维度两个方面进行改进。在层维度上,使用非局部块键值存储来增强知识表示能力;在token维度上,使用因果驱动优化来避免术语定位和上下文丢失。
技术框架:UnKE主要包含两个关键模块:非局部块键值存储和因果驱动优化。非局部块键值存储模块负责从多个注意力层提取信息,并将其存储为键值对,从而增强知识表示能力。因果驱动优化模块负责直接编辑最后一个token,同时保留上下文信息,从而避免术语定位和上下文丢失。整体流程是:首先,使用非局部块键值存储模块提取知识表示;然后,使用因果驱动优化模块进行知识编辑。
关键创新:UnKE的关键创新在于:1) 提出了非局部块键值存储,它能够从多个注意力层提取信息,从而增强知识表示能力;2) 提出了因果驱动优化,它能够直接编辑最后一个token,同时保留上下文信息,从而避免术语定位和上下文丢失。与现有方法相比,UnKE能够更有效地处理非结构化数据,并取得更好的编辑效果。
关键设计:非局部块键值存储的关键设计在于如何选择合适的注意力层和如何组合来自不同层的信息。论文中具体选择哪些层以及如何组合这些信息未知。因果驱动优化的关键设计在于如何确定需要编辑的最后一个token以及如何调整该token的表示,具体实现细节未知。损失函数的设计也未知。
🖼️ 关键图片

📊 实验亮点
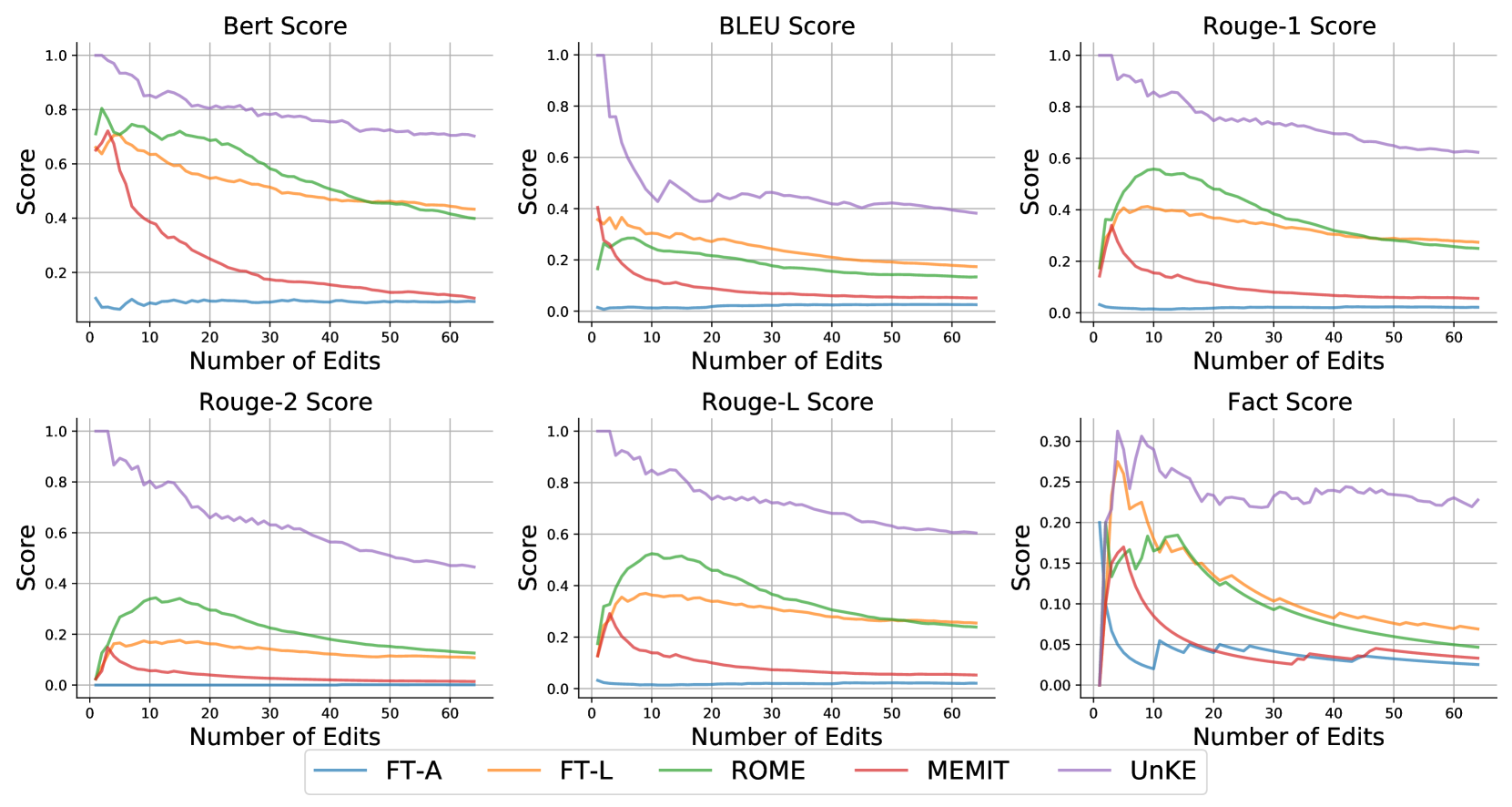
UnKE在UnKEBench和传统结构化数据集上均取得了显著的性能提升,超过了现有的基线模型。具体性能数据和提升幅度未知,但摘要中强调了其“remarkable performance”。此外,UnKE还具有强大的批量编辑和顺序编辑能力,这意味着它可以同时编辑多个知识点,并按照一定的顺序进行编辑,这在实际应用中非常有用。
🎯 应用场景
UnKE具有广泛的应用前景,例如可以用于自动更新文档、修正错误信息、生成个性化内容等。在教育领域,可以用于自动更新教材、生成习题等。在新闻领域,可以用于自动修正新闻报道中的错误信息。在客服领域,可以用于自动生成回复,提高客服效率。未来,UnKE有望成为一种重要的知识编辑工具,为各行各业带来便利。
📄 摘要(原文)
Recent knowledge editing methods have primarily focused on modifying structured knowledge in large language models. However, this task setting overlooks the fact that a significant portion of real-world knowledge is stored in an unstructured format, characterized by long-form content, noise, and a complex yet comprehensive nature. Techniques like "local layer key-value storage" and "term-driven optimization", as used in previous methods like MEMIT, are not effective for handling unstructured knowledge. To address these challenges, we propose a novel Unstructured Knowledge Editing method, namely UnKE, which extends previous assumptions in the layer dimension and token dimension. Firstly, in the layer dimension, we propose non-local block key-value storage to replace local layer key-value storage, increasing the representation ability of key-value pairs and incorporating attention layer knowledge. Secondly, in the token dimension, we replace "term-driven optimization" with "cause-driven optimization", which edits the last token directly while preserving context, avoiding the need to locate terms and preventing the loss of context information. Results on newly proposed unstructured knowledge editing dataset (UnKEBench) and traditional structured datasets demonstrate that UnKE achieves remarkable performance, surpassing strong baselines. In addition, UnKE has robust batch editing and sequential editing capabilities.