BiSup: Bidirectional Quantization Error Suppression for Large Language Models
作者: Minghui Zou, Ronghui Guo, Sai Zhang, Xiaowang Zhang, Zhiyong Feng
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-05-24
💡 一句话要点
BiSup:面向大语言模型的双向量化误差抑制方法,提升低比特量化性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型量化 权重激活量化 量化误差抑制 参数高效微调 混合精度量化
📋 核心要点
- 现有权重-激活量化方法忽略了LLM中量化误差的双向传播,导致性能下降。
- BiSup通过量化感知参数高效微调抑制垂直误差累积,并采用prompt混合精度量化减轻水平误差扩散。
- 实验表明,BiSup在Llama和Qwen模型上显著优于现有方法,降低了WikiText2的困惑度。
📝 摘要(中文)
随着大型语言模型(LLMs)的规模和上下文长度的增长,权重-激活量化已成为LLMs高效部署的关键技术。与仅权重量化相比,权重-激活量化由于激活中存在异常值而面临更大的挑战。现有方法通过探索混合精度量化和异常值抑制取得了显著进展。然而,这些方法主要关注优化单个矩阵乘法的结果,忽略了LLMs中量化误差的双向传播。具体来说,误差在同一token内通过层垂直累积,并且由于自注意力机制而在不同token之间水平扩散。为了解决这个问题,我们引入了BiSup,一种双向量化误差抑制方法。通过构建适当的可优化参数空间,BiSup利用少量数据进行量化感知参数高效微调,以抑制误差的垂直累积。此外,BiSup采用prompt混合精度量化策略,为系统提示的键-值缓存保留高精度,以减轻误差的水平扩散。在Llama和Qwen系列上的大量实验表明,BiSup可以提高性能,优于两种最先进的方法(在W3A3-g128配置下,平均WikiText2困惑度从Atom的13.26降至9.41,从QuaRot的14.33降至7.85),进一步促进了低比特权重-激活量化的实际应用。
🔬 方法详解
问题定义:现有权重-激活量化方法主要关注单个矩阵乘法的优化,忽略了量化误差在LLM中的双向传播问题。误差在层间垂直累积,在不同token间水平扩散,导致模型性能显著下降。现有方法未能有效解决这种双向误差传播问题。
核心思路:BiSup的核心思路是同时抑制量化误差的垂直累积和水平扩散。通过量化感知微调来校正垂直方向的误差累积,并使用prompt混合精度量化来减少水平方向的误差扩散。这种双管齐下的方法旨在更全面地控制量化误差,从而提高量化模型的性能。
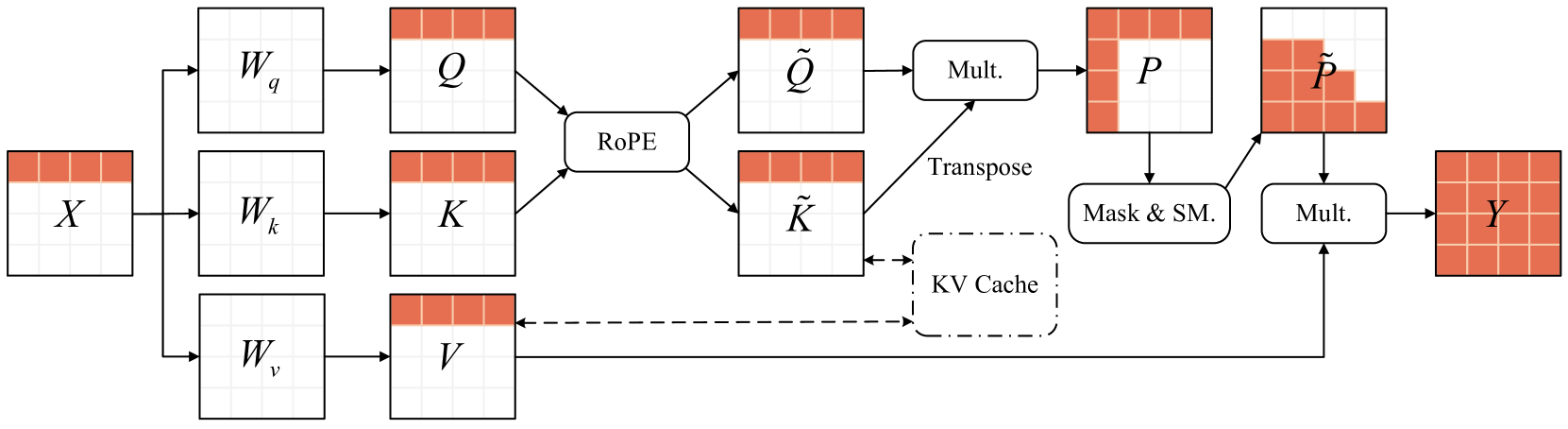
技术框架:BiSup包含两个主要组成部分:1) 量化感知参数高效微调,用于抑制垂直误差累积;2) prompt混合精度量化,用于减轻水平误差扩散。量化感知微调通过构建可优化的参数空间,利用少量数据进行微调,从而校正量化引入的误差。prompt混合精度量化则对系统提示的键-值缓存采用高精度量化,减少自注意力机制中的误差传播。
关键创新:BiSup的关键创新在于其双向误差抑制策略。与以往只关注单个矩阵乘法优化的方法不同,BiSup同时考虑了量化误差在层间和token间的传播。通过量化感知微调和prompt混合精度量化,BiSup能够更有效地控制量化误差,从而提高量化模型的性能。
关键设计:BiSup的关键设计包括:1) 构建可优化的参数空间,用于量化感知微调;2) 设计prompt混合精度量化策略,为系统提示的键-值缓存选择合适的精度。具体的参数设置和损失函数选择可能需要根据不同的模型和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BiSup在Llama和Qwen模型上显著优于现有的量化方法。例如,在W3A3-g128配置下,BiSup将WikiText2的平均困惑度从Atom的13.26降至9.41,从QuaRot的14.33降至7.85。这些结果表明,BiSup能够有效地抑制量化误差,提高量化模型的性能。
🎯 应用场景
BiSup可应用于各种需要高效部署的大型语言模型场景,例如移动设备、边缘计算和资源受限的服务器。通过降低模型的计算和存储需求,BiSup能够使LLM在这些平台上运行,从而扩展LLM的应用范围,并降低部署成本。
📄 摘要(原文)
As the size and context length of Large Language Models (LLMs) grow, weight-activation quantization has emerged as a crucial technique for efficient deployment of LLMs. Compared to weight-only quantization, weight-activation quantization presents greater challenges due to the presence of outliers in activations. Existing methods have made significant progress by exploring mixed-precision quantization and outlier suppression. However, these methods primarily focus on optimizing the results of single matrix multiplication, neglecting the bidirectional propagation of quantization errors in LLMs. Specifically, errors accumulate vertically within the same token through layers, and diffuse horizontally across different tokens due to self-attention mechanisms. To address this issue, we introduce BiSup, a Bidirectional quantization error Suppression method. By constructing appropriate optimizable parameter spaces, BiSup utilizes a small amount of data for quantization-aware parameter-efficient fine-tuning to suppress the error vertical accumulation. Besides, BiSup employs prompt mixed-precision quantization strategy, which preserves high precision for the key-value cache of system prompts, to mitigate the error horizontal diffusion. Extensive experiments on Llama and Qwen families demonstrate that BiSup can improve performance over two state-of-the-art methods (the average WikiText2 perplexity decreases from 13.26 to 9.41 for Atom and from 14.33 to 7.85 for QuaRot under the W3A3-g128 configuration), further facilitating the practical applications of low-bit weight-activation quantization.