Before Generation, Align it! A Novel and Effective Strategy for Mitigating Hallucinations in Text-to-SQL Generation
作者: Ge Qu, Jinyang Li, Bowen Li, Bowen Qin, Nan Huo, Chenhao Ma, Reynold Cheng
分类: cs.CL
发布日期: 2024-05-24
备注: Accepted to ACL Findings 2024
💡 一句话要点
提出任务对齐策略TA-SQL,缓解文本到SQL生成中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到SQL 大型语言模型 幻觉缓解 任务对齐 In-Context Learning
📋 核心要点
- 现有文本到SQL方法依赖两阶段推理,但大型语言模型的泛化能力不足导致幻觉问题。
- 论文提出任务对齐(TA)策略,通过利用相似任务经验来减轻LLM的泛化负担,从而缓解幻觉。
- 实验结果表明,TA-SQL框架在多个基准测试中显著提升了文本到SQL的生成性能,尤其是在BIRD数据集上。
📝 摘要(中文)
本文针对大型语言模型(LLMs)在文本到SQL生成任务中存在的幻觉问题,提出了一种新颖有效的策略——任务对齐(TA)。该策略旨在利用相似任务的经验,而非从零开始,从而减轻LLMs的泛化负担,有效缓解幻觉。为此,本文首先识别并分类了文本到SQL生成各阶段中常见的幻觉类型。然后,基于任务对齐策略,提出了TA-SQL框架。实验结果和综合分析表明,该框架具有有效性和鲁棒性。具体而言,在BIRD dev数据集上,TA-SQL相对于GPT-4基线模型性能提升了21.23%,并在六个模型和四个主流复杂文本到SQL基准测试中取得了显著改进。
🔬 方法详解
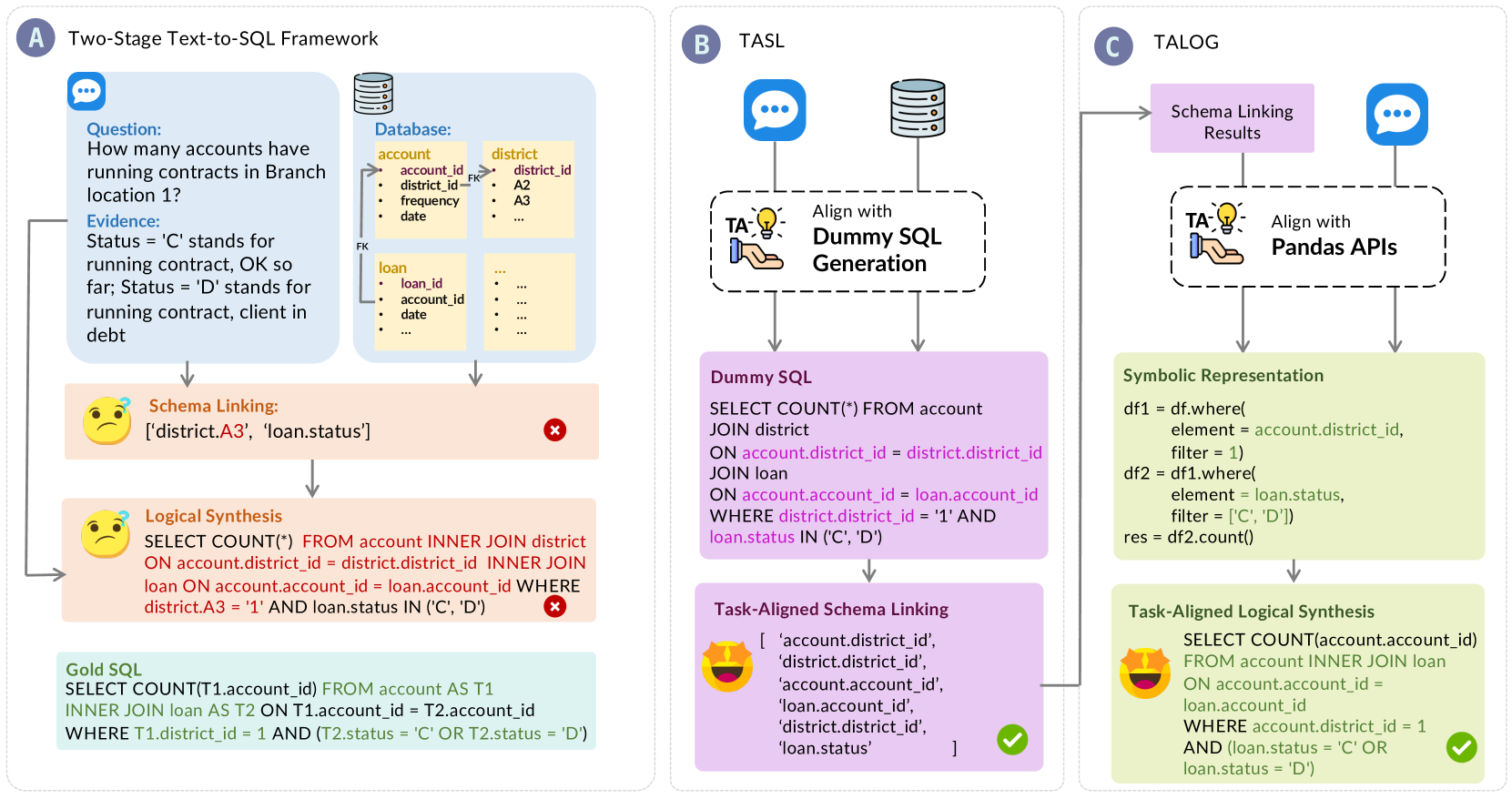
问题定义:文本到SQL生成旨在将自然语言描述转换为可执行的SQL查询语句。现有方法,特别是基于大型语言模型的方法,虽然取得了显著进展,但由于LLM固有的泛化问题,容易产生幻觉,即生成不符合数据库schema或语义逻辑的SQL语句。这些幻觉降低了SQL查询的准确性和可靠性,限制了LLM在文本到SQL任务中的应用。
核心思路:论文的核心思路是任务对齐(Task Alignment, TA)。TA的核心思想是让LLM在解决新的文本到SQL任务时,不是从零开始,而是借鉴和利用之前解决过的相似任务的经验。通过这种方式,可以减少LLM的泛化负担,使其更容易生成正确的SQL语句,从而缓解幻觉问题。TA策略的关键在于找到合适的相似任务,并将这些任务的经验有效地传递给LLM。
技术框架:TA-SQL框架基于任务对齐策略,其整体流程可以概括为:1) 幻觉类型识别与分类:首先对文本到SQL生成过程中出现的幻觉进行分类,例如schema linking错误、逻辑合成错误等。2) 相似任务检索:对于给定的文本到SQL任务,从历史任务库中检索相似的任务。相似度可以通过文本相似度、schema相似度等多种方式进行衡量。3) 任务对齐:将检索到的相似任务的经验(例如,输入文本、对应的SQL语句、推理过程等)以某种方式融入到LLM的输入中,引导LLM生成正确的SQL语句。4) SQL生成与验证:LLM根据对齐后的输入生成SQL语句,并进行验证,例如语法检查、schema一致性检查等。
关键创新:论文最重要的技术创新点在于任务对齐策略。与以往的方法不同,TA策略不是直接优化LLM的结构或训练方式,而是通过外部干预的方式,引导LLM利用已有的知识和经验,从而缓解幻觉问题。这种策略具有通用性,可以应用于不同的LLM和文本到SQL框架。
关键设计:论文中关于任务对齐的关键设计包括:1) 相似任务检索策略:如何有效地检索到与当前任务最相关的历史任务?可以使用基于文本相似度、schema相似度或二者结合的方法。2) 经验融入方式:如何将检索到的相似任务的经验有效地融入到LLM的输入中?可以使用prompting技术,例如将相似任务的输入文本和SQL语句作为示例添加到LLM的prompt中。3) 幻觉类型分类:对幻觉进行细致的分类,有助于针对不同类型的幻觉设计更有效的缓解策略。
🖼️ 关键图片

📊 实验亮点
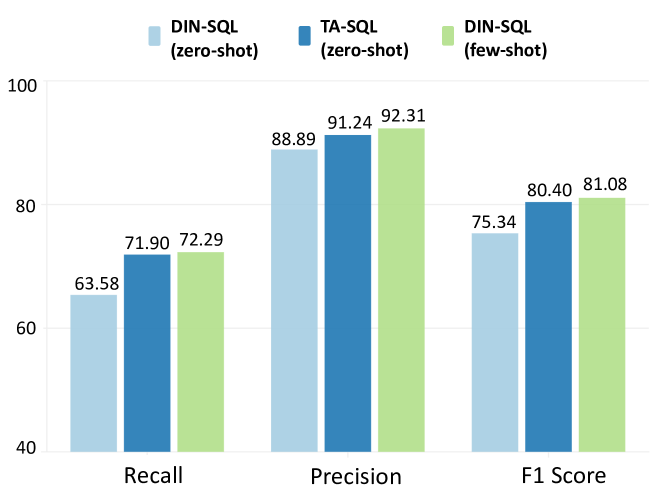
实验结果表明,TA-SQL框架在BIRD dev数据集上相对于GPT-4基线模型性能提升了21.23%。此外,TA-SQL在六个模型和四个主流复杂文本到SQL基准测试中均取得了显著改进,证明了其有效性和鲁棒性。这些结果表明,任务对齐策略能够有效地缓解文本到SQL生成中的幻觉问题,并显著提升生成性能。
🎯 应用场景
该研究成果可广泛应用于智能数据库查询、自然语言接口、数据分析等领域。通过提高文本到SQL生成的准确性和可靠性,可以降低用户使用数据库的门槛,提升数据分析的效率。未来,该技术有望应用于更复杂的数据库系统和更广泛的自然语言处理任务中,例如自动报表生成、智能数据挖掘等。
📄 摘要(原文)
Large Language Models (LLMs) driven by In-Context Learning (ICL) have significantly improved the performance of text-to-SQL. Previous methods generally employ a two-stage reasoning framework, namely 1) schema linking and 2) logical synthesis, making the framework not only effective but also interpretable. Despite these advancements, the inherent bad nature of the generalization of LLMs often results in hallucinations, which limits the full potential of LLMs. In this work, we first identify and categorize the common types of hallucinations at each stage in text-to-SQL. We then introduce a novel strategy, Task Alignment (TA), designed to mitigate hallucinations at each stage. TA encourages LLMs to take advantage of experiences from similar tasks rather than starting the tasks from scratch. This can help LLMs reduce the burden of generalization, thereby mitigating hallucinations effectively. We further propose TA-SQL, a text-to-SQL framework based on this strategy. The experimental results and comprehensive analysis demonstrate the effectiveness and robustness of our framework. Specifically, it enhances the performance of the GPT-4 baseline by 21.23% relatively on BIRD dev and it yields significant improvements across six models and four mainstream, complex text-to-SQL benchmarks.