EffiLearner: Enhancing Efficiency of Generated Code via Self-Optimization
作者: Dong Huang, Jianbo Dai, Han Weng, Puzhen Wu, Yuhao Qing, Heming Cui, Zhijiang Guo, Jie M. Zhang
分类: cs.SE, cs.CL
发布日期: 2024-05-24 (更新: 2025-05-10)
备注: Accepted by NeurIPS 2024
🔗 代码/项目: GITHUB
💡 一句话要点
EffiLearner:通过自优化提升大语言模型生成代码的效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大语言模型 自优化 性能优化 执行效率
📋 核心要点
- 现有大语言模型生成的代码效率低下,执行时间长,内存消耗高,难以直接应用。
- EffiLearner通过执行代码并分析其性能瓶颈,将性能数据反馈给LLM进行迭代优化。
- 实验表明,EffiLearner能显著降低LLM生成代码的执行时间和内存占用,提升代码效率。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成方面取得了显著进展,但它们生成的代码通常效率低下,导致更长的执行时间和更高的内存消耗。为了解决这个问题,我们提出了EffiLearner,一个自优化框架,它利用执行开销配置文件来提高LLM生成代码的效率。EffiLearner首先使用LLM生成代码,然后在本地执行它以捕获执行时间和内存使用情况配置文件。这些配置文件被反馈给LLM,然后LLM修改代码以减少开销。为了评估EffiLearner的有效性,我们在EffiBench、HumanEval和MBPP上使用16个开源和6个闭源模型进行了广泛的实验。我们的评估结果表明,通过迭代自优化,EffiLearner显著提高了LLM生成代码的效率。例如,StarCoder2-15B在EffiBench上的执行时间(ET)从0.93(s)降低到0.12(s),与初始代码相比,执行时间减少了87.1%。StarCoder2-15B的总内存使用量(TMU)也从22.02(Mbs)降低到2.03(Mbs),执行过程中总内存消耗降低了90.8%。EffiLearner的源代码已在https://github.com/huangd1999/EffiLearner发布。
🔬 方法详解
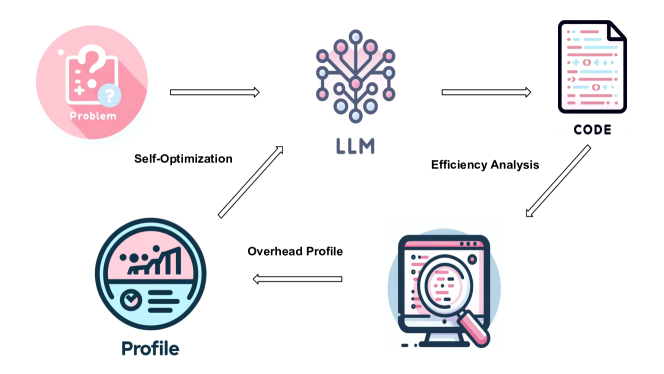
问题定义:现有的大语言模型在代码生成方面取得了很大进展,但是生成的代码往往存在效率问题,例如执行时间过长、内存占用过高等。这些问题限制了LLM生成代码的实际应用价值。现有方法缺乏有效的反馈机制,难以针对性地优化代码效率。
核心思路:EffiLearner的核心思路是利用代码的执行反馈来指导LLM进行自优化。通过实际运行生成的代码,收集执行时间和内存使用情况等性能指标,并将这些指标作为反馈信号,让LLM能够针对性地改进代码,从而提高代码效率。这种迭代优化的方式能够逐步提升代码的性能。
技术框架:EffiLearner框架主要包含以下几个阶段:1) LLM代码生成:使用LLM生成初始代码。2) 性能剖析:在本地执行生成的代码,并使用性能分析工具(例如profiler)收集执行时间和内存使用情况等性能数据。3) 反馈与优化:将性能数据反馈给LLM,LLM根据反馈信息修改代码,以减少执行时间和内存占用。4) 迭代优化:重复执行性能剖析和反馈与优化步骤,直到代码的性能达到预期的目标。
关键创新:EffiLearner的关键创新在于引入了执行反馈机制,实现了LLM生成代码的自优化。与传统的代码生成方法相比,EffiLearner能够根据实际的性能数据来指导代码的改进,从而更有效地提高代码效率。这种自优化方法可以充分利用LLM的生成能力,同时克服其在代码效率方面的不足。
关键设计:在性能剖析阶段,需要选择合适的性能分析工具,以准确地测量执行时间和内存使用情况。在反馈与优化阶段,需要设计有效的反馈机制,将性能数据传递给LLM,并指导LLM进行代码修改。例如,可以使用prompt工程技术,将性能数据作为prompt的一部分,引导LLM生成更高效的代码。此外,还可以设置迭代优化的停止条件,例如达到预期的性能目标或达到最大迭代次数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,EffiLearner能够显著提高LLM生成代码的效率。例如,对于EffiBench数据集,使用StarCoder2-15B模型,通过EffiLearner优化后,代码的执行时间减少了87.1%,总内存使用量降低了90.8%。在HumanEval和MBPP数据集上,EffiLearner也取得了类似的性能提升。这些结果表明,EffiLearner是一种有效的代码自优化方法。
🎯 应用场景
EffiLearner可应用于各种需要高效代码的场景,例如嵌入式系统、高性能计算、移动应用开发等。通过自动优化LLM生成的代码,可以降低资源消耗,提高系统性能,并加速软件开发过程。该研究成果有助于推动LLM在软件工程领域的应用,并提升软件开发的自动化水平。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable progress in code generation, but their generated code often suffers from inefficiency, resulting in longer execution times and higher memory consumption. To address this issue, we propose \textbf{EffiLearner}, a self-optimization framework that utilizes execution overhead profiles to improve the efficiency of LLM-generated code. EffiLearner first generates code using an LLM, then executes it locally to capture execution time and memory usage profiles. These profiles are fed back to the LLM, which then revises the code to reduce overhead. To evaluate the effectiveness of EffiLearner, we conduct extensive experiments on the EffiBench, HumanEval, and MBPP with 16 open-source and 6 closed-source models. Our evaluation results demonstrate that through iterative self-optimization, EffiLearner significantly enhances the efficiency of LLM-generated code. For example, the execution time (ET) of StarCoder2-15B for the EffiBench decreases from 0.93 (s) to 0.12 (s) which reduces 87.1% the execution time requirement compared with the initial code. The total memory usage (TMU) of StarCoder2-15B also decreases from 22.02 (Mbs) to 2.03 (Mbs), which decreases 90.8% of total memory consumption during the execution process. The source code of EffiLearner was released in https://github.com/huangd1999/EffiLearner