OptLLM: Optimal Assignment of Queries to Large Language Models
作者: Yueyue Liu, Hongyu Zhang, Yuantian Miao, Van-Hoang Le, Zhiqiang Li
分类: cs.SE, cs.CL, cs.LG
发布日期: 2024-05-24
备注: This paper is accepted by ICWS 2024
💡 一句话要点
OptLLM:通过优化查询分配,在预算约束下实现大语言模型的最优成本效益。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 查询分配 成本效益 多目标优化 性能预测
📋 核心要点
- 现有方法难以在预算约束下,为不同查询选择最优的大语言模型组合,缺乏成本效益的查询分配方案。
- OptLLM通过预测LLM在不同查询上的性能,并结合多目标优化算法,为用户提供成本和性能之间的权衡方案。
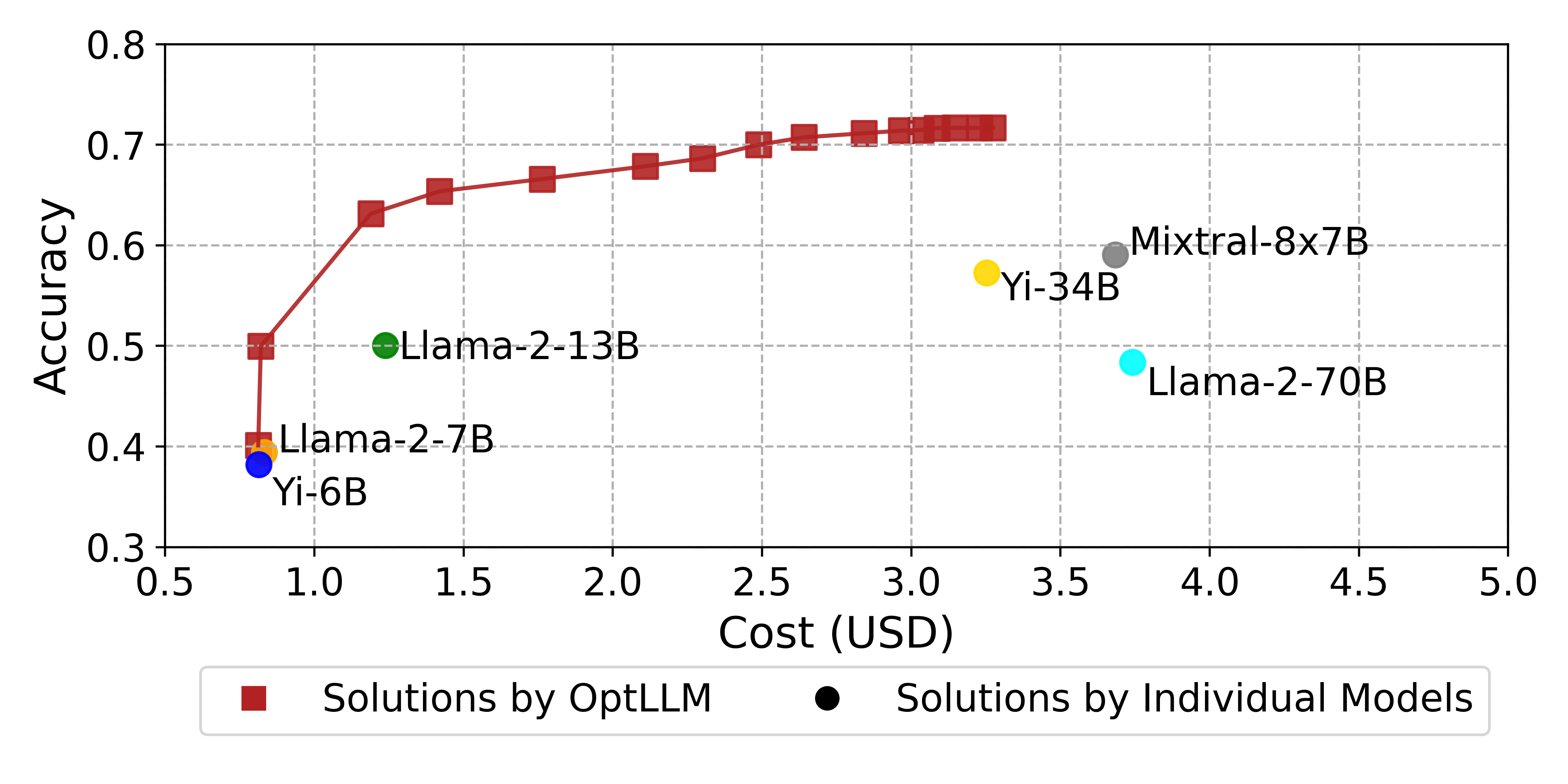
- 实验表明,OptLLM在保证准确率的同时显著降低成本,或在相同成本下提升准确率,优于现有方法。
📝 摘要(中文)
本文提出了一种针对大语言模型(LLM)的成本效益查询分配框架OptLLM。随着越来越多的公司提供LLM服务,如何在成本和性能之间取得平衡,选择最适合用户需求的LLM成为一个挑战。OptLLM旨在为用户提供一系列最优解决方案,以满足其预算约束和性能偏好,包括最大化准确性和最小化成本的选项。OptLLM使用带有不确定性估计的多标签分类模型预测候选LLM在每个查询上的性能,然后通过破坏和重建当前解决方案迭代生成一组非支配解。在文本分类、问答、情感分析、推理和日志解析等多种任务上的实验结果表明,OptLLM在达到与最佳LLM相同准确率的同时,显著降低了2.40%到49.18%的成本。与其他多目标优化算法相比,OptLLM在相同成本下将准确率提高了2.94%到69.05%,或者在保持最高可达准确率的同时节省了8.79%到95.87%的成本。
🔬 方法详解
问题定义:论文旨在解决如何根据用户的预算和性能需求,为不同的查询选择最优的大语言模型(LLM)组合,以实现成本效益最大化。现有方法通常要么选择单一的最佳LLM,要么没有充分考虑不同LLM在不同查询上的性能差异和成本差异,导致资源浪费或性能不足。
核心思路:论文的核心思路是预测每个LLM在每个查询上的性能,并将其建模为一个多目标优化问题,目标是最小化成本和最大化准确率。通过生成一组非支配解(Pareto最优解),用户可以根据自己的偏好选择最合适的LLM组合。
技术框架:OptLLM框架主要包含两个阶段:性能预测阶段和优化分配阶段。在性能预测阶段,使用一个多标签分类模型预测每个LLM在每个查询上的性能,并估计预测的不确定性。在优化分配阶段,使用一种迭代的破坏和重建算法生成一组非支配解,每个解代表一种LLM组合方案。
关键创新:OptLLM的关键创新在于:1) 使用多标签分类模型进行性能预测,能够更准确地捕捉不同LLM在不同查询上的性能差异;2) 采用迭代的破坏和重建算法,能够有效地搜索非支配解空间,找到成本效益最优的LLM组合;3) 考虑了性能预测的不确定性,提高了方案的鲁棒性。
关键设计:性能预测模型采用多标签分类结构,输出每个LLM在每个查询上的性能概率分布。优化分配算法采用迭代的破坏和重建策略,每次迭代随机破坏当前解的一部分,然后重新分配LLM,并根据成本和性能指标评估新解。通过多次迭代,生成一组非支配解,供用户选择。
🖼️ 关键图片


📊 实验亮点
实验结果表明,OptLLM在保持与最佳LLM相同准确率的情况下,能够降低2.40%到49.18%的成本。与其他多目标优化算法相比,OptLLM在相同成本下将准确率提高了2.94%到69.05%,或者在保持最高可达准确率的同时节省了8.79%到95.87%的成本。这些数据表明OptLLM在成本效益方面具有显著优势。
🎯 应用场景
OptLLM可应用于各种需要使用大语言模型的场景,例如智能客服、内容生成、数据分析等。它可以帮助企业或个人在预算有限的情况下,选择最合适的LLM组合,提高效率并降低成本。该研究对于推动大语言模型在实际应用中的普及具有重要意义。
📄 摘要(原文)
Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.