Reframing Spatial Reasoning Evaluation in Language Models: A Real-World Simulation Benchmark for Qualitative Reasoning
作者: Fangjun Li, David C. Hogg, Anthony G. Cohn
分类: cs.CL, cs.AI, cs.DB
发布日期: 2024-05-23
备注: Camera-Ready version for IJCAI 2024
💡 一句话要点
提出基于真实3D模拟的语言模型定性空间推理评估基准
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 空间推理 语言模型 定性推理 3D模拟 评估基准
📋 核心要点
- 现有空间推理评估基准过于简化,缺乏真实场景的复杂性和多样性,难以有效评估语言模型的真实能力。
- 构建基于真实3D模拟数据的基准,提供丰富的房间布局和对象关系,并采用逻辑一致性检查工具评估多种合理答案。
- 实验结果揭示了现有语言模型在多跳推理和多视角信息融合方面的不足,为未来研究指明方向。
📝 摘要(中文)
空间推理在人类认知和机器智能中都至关重要,这推动了对语言模型(LMs)在此方面能力的新研究。然而,现有的基准在评估定性空间推理(QSR)方面存在不足,通常呈现过于简化的场景或不清晰的自然语言描述,阻碍了有效评估。本文提出了一个新颖的基准,用于评估LMs中的QSR,该基准基于真实的3D模拟数据,提供了一系列具有各种对象及其空间关系的房间布局。这种方法为空间推理评估提供了更详细和上下文丰富的叙述,不同于传统的、面向玩具任务的场景。我们的基准涵盖了广泛的定性空间关系,包括拓扑、方向和距离关系。这些关系以不同的视角、不同的粒度和关系约束密度呈现,以模拟真实世界的复杂性。一个关键贡献是我们的基于逻辑的一致性检查工具,它可以评估多个合理的解决方案,与空间关系通常可以解释的现实世界场景保持一致。我们对高级LMs的基准评估揭示了它们在空间推理方面的优势和局限性。它们在多跳空间推理和解释不同视图描述的混合方面面临困难,这指出了未来改进的领域。
🔬 方法详解
问题定义:现有语言模型空间推理能力的评估基准存在两个主要问题:一是场景过于简化,与真实世界差距较大,难以反映模型的真实能力;二是自然语言描述不够清晰,存在歧义,影响评估的准确性。因此,需要一个更贴近真实场景、描述更清晰的评估基准来更准确地评估语言模型的空间推理能力。
核心思路:本文的核心思路是利用3D模拟数据构建一个更真实的评估环境。通过模拟各种房间布局和对象关系,并提供不同视角和粒度的描述,来模拟真实世界的复杂性。此外,采用基于逻辑的一致性检查工具,允许模型给出多个合理的答案,从而更全面地评估模型的空间推理能力。
技术框架:该基准主要包含以下几个模块:1) 3D场景生成模块:用于生成各种房间布局和对象关系;2) 自然语言描述生成模块:用于根据3D场景生成不同视角和粒度的自然语言描述;3) 空间推理模块:待评估的语言模型,用于根据自然语言描述进行空间推理;4) 逻辑一致性检查模块:用于检查语言模型给出的答案是否符合逻辑一致性。整个流程是,首先生成3D场景和对应的自然语言描述,然后将自然语言描述输入到语言模型中进行空间推理,最后使用逻辑一致性检查模块评估语言模型的答案。
关键创新:该论文的关键创新在于:1) 使用3D模拟数据构建更真实的评估环境,更贴近真实世界的复杂性;2) 采用基于逻辑的一致性检查工具,允许模型给出多个合理的答案,从而更全面地评估模型的空间推理能力;3) 提供了不同视角和粒度的描述,增加了评估的难度和多样性。
关键设计:在3D场景生成方面,考虑了房间的大小、形状、对象的种类、数量和位置等因素。在自然语言描述生成方面,考虑了视角、粒度、描述的详细程度等因素。逻辑一致性检查模块使用一阶逻辑规则来判断答案是否符合逻辑一致性。具体的参数设置和网络结构取决于待评估的语言模型。
🖼️ 关键图片

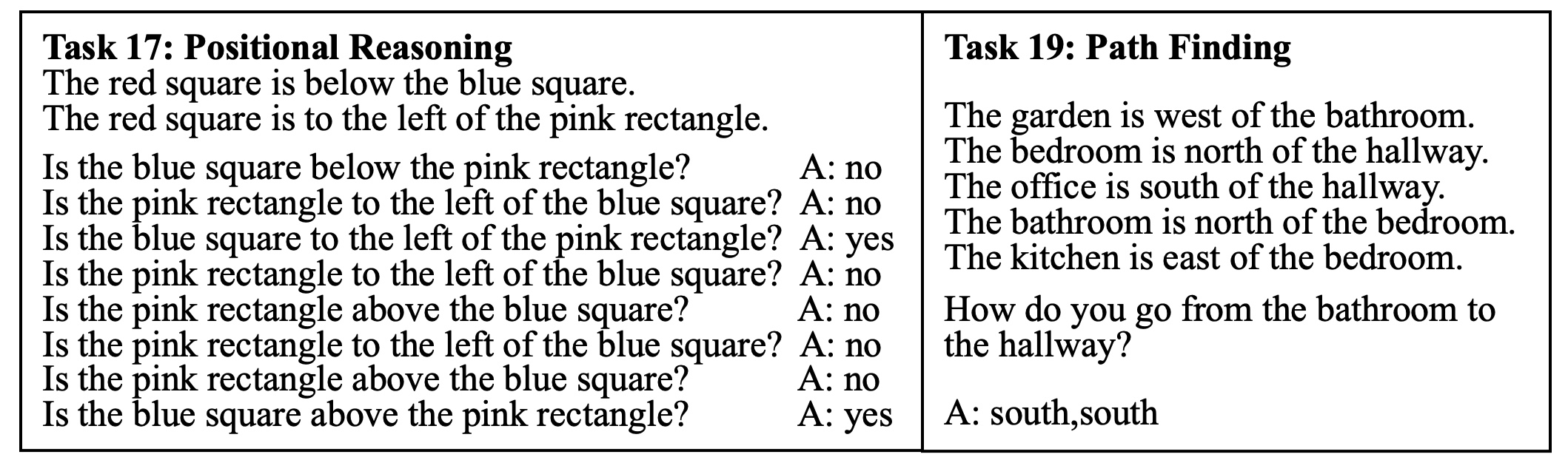
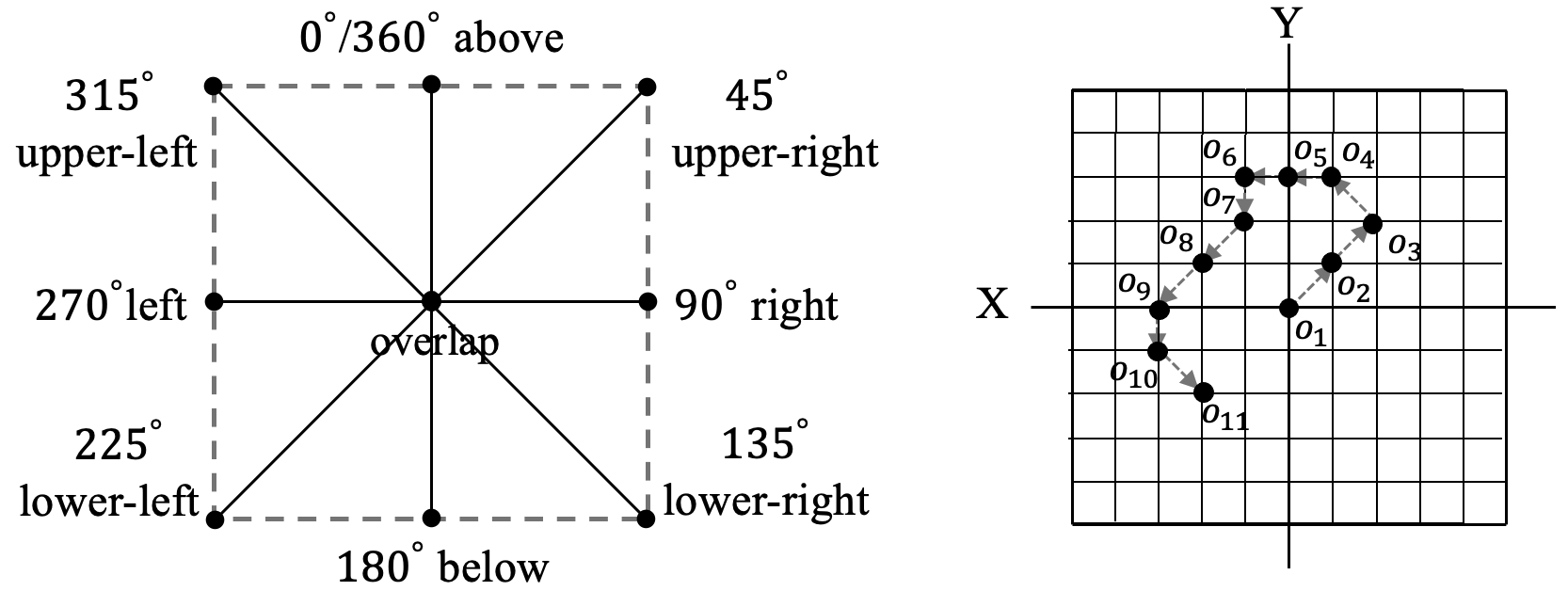
📊 实验亮点
该基准评估了多个先进的语言模型,结果表明,这些模型在多跳空间推理和处理混合视角描述方面存在困难。例如,模型在需要结合多个空间关系才能得出结论的任务中表现不佳,并且在面对来自不同视角的描述时,难以保持一致性。这些发现为未来改进语言模型的空间推理能力提供了重要的指导。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、虚拟现实等领域。通过提高语言模型的空间推理能力,可以使机器人更好地理解人类指令,在复杂环境中进行导航;智能家居系统可以更准确地理解用户的意图,提供更智能化的服务;虚拟现实系统可以提供更逼真的空间体验。
📄 摘要(原文)
Spatial reasoning plays a vital role in both human cognition and machine intelligence, prompting new research into language models' (LMs) capabilities in this regard. However, existing benchmarks reveal shortcomings in evaluating qualitative spatial reasoning (QSR). These benchmarks typically present oversimplified scenarios or unclear natural language descriptions, hindering effective evaluation. We present a novel benchmark for assessing QSR in LMs, which is grounded in realistic 3D simulation data, offering a series of diverse room layouts with various objects and their spatial relationships. This approach provides a more detailed and context-rich narrative for spatial reasoning evaluation, diverging from traditional, toy-task-oriented scenarios. Our benchmark encompasses a broad spectrum of qualitative spatial relationships, including topological, directional, and distance relations. These are presented with different viewing points, varied granularities, and density of relation constraints to mimic real-world complexities. A key contribution is our logic-based consistency-checking tool, which enables the assessment of multiple plausible solutions, aligning with real-world scenarios where spatial relationships are often open to interpretation. Our benchmark evaluation of advanced LMs reveals their strengths and limitations in spatial reasoning. They face difficulties with multi-hop spatial reasoning and interpreting a mix of different view descriptions, pointing to areas for future improvement.