Extracting Prompts by Inverting LLM Outputs
作者: Collin Zhang, John X. Morris, Vitaly Shmatikov
分类: cs.CL, cs.LG
发布日期: 2024-05-23 (更新: 2024-10-08)
💡 一句话要点
提出output2prompt方法,通过反演LLM输出来提取生成提示词。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型反演 提示词提取 黑盒攻击 稀疏编码 零样本学习
📋 核心要点
- 现有方法需要访问模型内部信息或进行对抗性查询,限制了其应用范围和安全性。
- output2prompt通过学习从LLM输出反演提示词,无需访问模型logits或进行特殊查询。
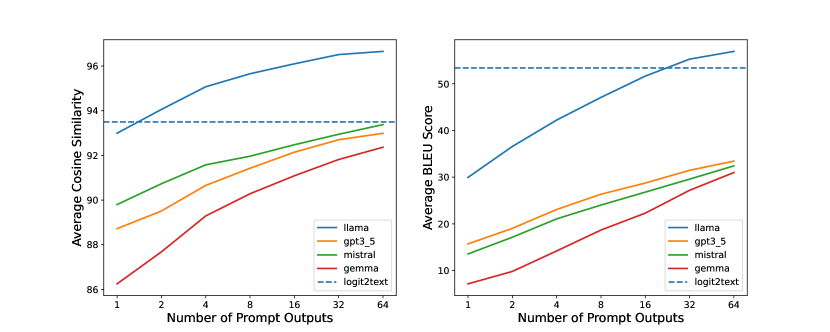
- 实验表明,该方法在多种提示词上有效,并具备跨不同LLM的零样本迁移能力。
📝 摘要(中文)
本文研究了语言模型反演问题:给定语言模型的输出,如何提取生成这些输出的提示词。我们开发了一种新的黑盒方法output2prompt,它学习提取提示词,无需访问模型的logits,也无需对抗性或越狱查询。与之前的工作不同,output2prompt只需要普通用户查询的输出。为了提高内存效率,output2prompt采用了一种新的稀疏编码技术。我们在各种用户和系统提示词上衡量了output2prompt的有效性,并展示了跨不同LLM的零样本迁移能力。
🔬 方法详解
问题定义:论文旨在解决语言模型反演问题,即给定一个大型语言模型(LLM)的输出,如何恢复生成该输出的原始提示词。现有方法通常需要访问模型的内部信息(如logits)或进行对抗性/越狱查询,这在实际应用中可能不可行或存在安全风险。因此,如何在黑盒设置下,仅通过观察LLM的输出来提取提示词是一个重要的挑战。
核心思路:output2prompt的核心思路是训练一个模型,该模型能够学习从LLM的输出到生成该输出的提示词之间的映射关系。该模型无需访问LLM的内部参数或进行特殊查询,而是将其视为一个黑盒。通过大量的输入-输出对训练,output2prompt能够学习到提示词的潜在结构和模式。
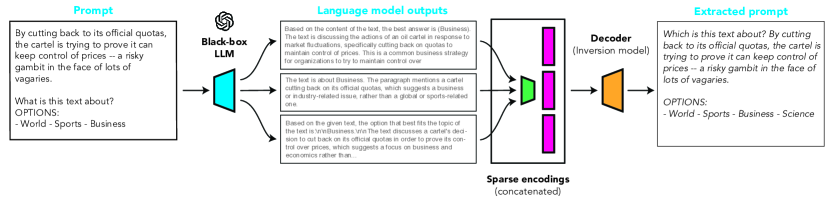
技术框架:output2prompt的整体框架包括以下几个主要阶段:1) 数据收集:收集大量的LLM输出及其对应的提示词,构成训练数据集。2) 特征提取:对LLM的输出进行特征提取,例如使用词嵌入或Transformer编码器。3) 提示词生成:使用一个解码器模型(例如Transformer解码器)从提取的特征生成提示词。4) 稀疏编码:为了提高内存效率,采用了一种新的稀疏编码技术来表示提示词。
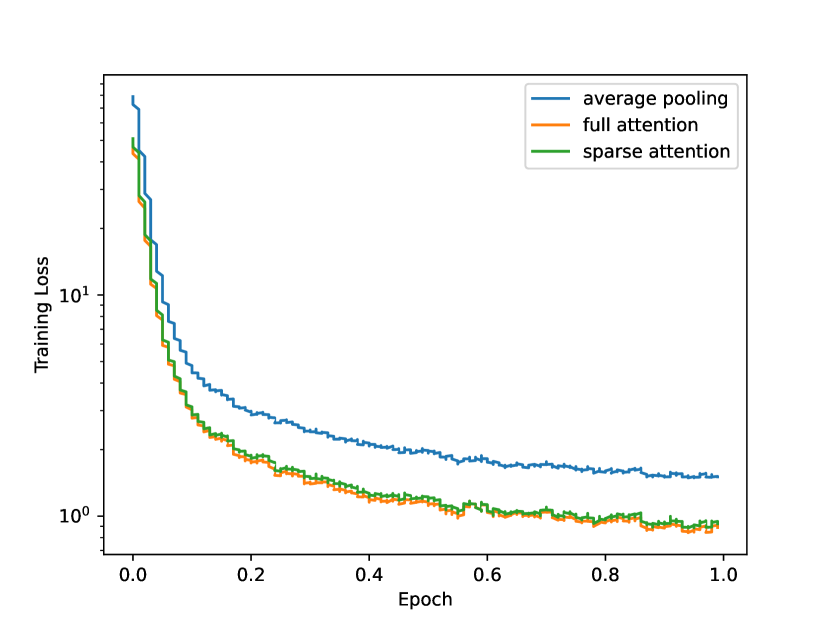
关键创新:output2prompt的关键创新在于其黑盒特性和稀疏编码技术。与现有方法相比,它不需要访问LLM的内部信息或进行对抗性查询,使其更具实用性和安全性。稀疏编码技术则显著降低了内存需求,使得该方法可以处理更长的提示词和更大的数据集。
关键设计:output2prompt的关键设计包括:1) 使用Transformer架构作为编码器和解码器,以捕捉LLM输出和提示词之间的复杂关系。2) 采用稀疏编码技术,例如使用L1正则化或剪枝来减少提示词表示的维度。3) 设计合适的损失函数,例如交叉熵损失或BLEU得分,以衡量生成提示词的质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,output2prompt在各种用户和系统提示词上都表现出良好的性能,能够有效地提取生成LLM输出的提示词。此外,该方法还展示了跨不同LLM的零样本迁移能力,这意味着它可以在没有针对特定LLM进行训练的情况下,直接应用于该LLM。
🎯 应用场景
该研究成果可应用于安全领域,例如检测和防御针对LLM的提示词注入攻击。此外,它还可以用于分析LLM的学习能力和知识表示,以及改进LLM的提示词工程。未来,该技术有望应用于自动化提示词生成和优化,提升LLM在各种任务中的性能。
📄 摘要(原文)
We consider the problem of language model inversion: given outputs of a language model, we seek to extract the prompt that generated these outputs. We develop a new black-box method, output2prompt, that learns to extract prompts without access to the model's logits and without adversarial or jailbreaking queries. In contrast to previous work, output2prompt only needs outputs of normal user queries. To improve memory efficiency, output2prompt employs a new sparse encoding techique. We measure the efficacy of output2prompt on a variety of user and system prompts and demonstrate zero-shot transferability across different LLMs.