RE-Adapt: Reverse Engineered Adaptation of Large Language Models
作者: William Fleshman, Benjamin Van Durme
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-05-23
💡 一句话要点
提出RE-Adapt,在不损失指令微调性能前提下,实现LLM在新领域的适应。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型微调 领域自适应 指令遵循 逆向工程 适配器 低秩分解 检索增强生成
📋 核心要点
- 现有指令微调模型在新领域微调时,容易遗忘已学习的指令遵循能力,造成性能下降。
- RE-Adapt通过逆向工程提取指令微调模型的适配器,隔离指令遵循能力,无需额外数据或训练。
- 实验表明,RE-Adapt及其低秩变体LoRE-Adapt在多个LLM和数据集上优于其他微调方法。
📝 摘要(中文)
本文介绍了一种名为RE-Adapt的方法,用于在大语言模型上进行新领域的微调,同时不降低任何预先存在的指令微调性能。RE-Adapt通过逆向工程获得一个适配器,该适配器隔离了指令微调模型在其对应的预训练基础模型之外所学习到的内容。重要的是,这不需要额外的数据或训练。然后,我们可以将基础模型在新领域上进行微调,并通过逆向工程的适配器将其重新适配到指令遵循。RE-Adapt和我们的低秩变体LoRE-Adapt在多个流行的LLM和数据集上,都优于其他微调方法,即使这些模型与检索增强生成结合使用。
🔬 方法详解
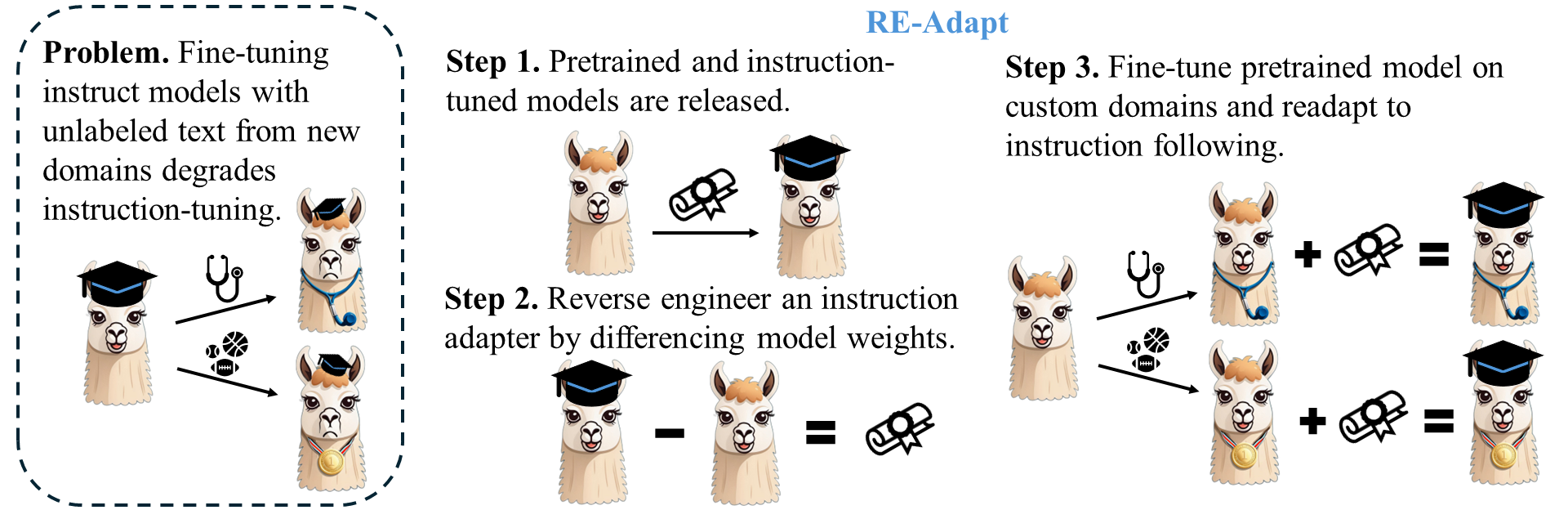
问题定义:现有的大语言模型在经过指令微调后,获得了良好的指令遵循能力。然而,当需要在新的领域进行微调时,传统的微调方法容易导致模型遗忘之前学习到的指令遵循能力,从而降低模型的整体性能。因此,如何在不损失原有指令微调能力的前提下,使模型适应新的领域是一个重要的挑战。
核心思路:RE-Adapt的核心思路是通过逆向工程,提取一个适配器,该适配器能够捕获指令微调模型在其对应的预训练基础模型之外所学习到的指令遵循能力。这样,在对基础模型进行新领域微调时,可以通过该适配器将指令遵循能力重新注入到微调后的模型中,从而避免指令遵循能力的遗忘。
技术框架:RE-Adapt的整体框架包括以下几个步骤:1) 使用指令微调模型和其对应的预训练基础模型,通过逆向工程提取适配器。2) 在新的领域上对基础模型进行微调。3) 将提取的适配器应用到微调后的模型上,使其重新获得指令遵循能力。整个过程不需要额外的数据或训练。
关键创新:RE-Adapt最重要的创新点在于其逆向工程适配器的思想。通过这种方式,可以将指令遵循能力从指令微调模型中分离出来,并在新领域微调后重新注入,从而避免了指令遵循能力的遗忘。与传统的微调方法相比,RE-Adapt能够更好地保持模型的原有能力。
关键设计:RE-Adapt的关键设计在于如何有效地进行逆向工程,提取适配器。具体来说,可以通过计算指令微调模型和基础模型之间的参数差异,并使用低秩分解等技术来压缩适配器的规模。此外,损失函数的设计也至关重要,需要确保适配器能够准确地捕获指令遵循能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RE-Adapt及其低秩变体LoRE-Adapt在多个流行的LLM和数据集上,都优于其他微调方法。即使在模型与检索增强生成(RAG)结合使用时,RE-Adapt仍然表现出显著的性能优势。具体的数据提升幅度取决于具体的模型和数据集,但总体趋势是RE-Adapt能够有效地保持指令遵循能力,并在新领域取得更好的性能。
🎯 应用场景
RE-Adapt可广泛应用于各种需要对大型语言模型进行领域自适应的场景,例如:特定行业的文本生成、专业领域的问答系统、以及需要持续学习和适应新任务的智能助手。该方法能够有效提升模型在特定领域的性能,同时保持其通用的指令遵循能力,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
We introduce RE-Adapt, an approach to fine-tuning large language models on new domains without degrading any pre-existing instruction-tuning. We reverse engineer an adapter which isolates what an instruction-tuned model has learned beyond its corresponding pretrained base model. Importantly, this requires no additional data or training. We can then fine-tune the base model on a new domain and readapt it to instruction following with the reverse engineered adapter. RE-Adapt and our low-rank variant LoRE-Adapt both outperform other methods of fine-tuning, across multiple popular LLMs and datasets, even when the models are used in conjunction with retrieval-augmented generation.