Dataset Decomposition: Faster LLM Training with Variable Sequence Length Curriculum
作者: Hadi Pouransari, Chun-Liang Li, Jen-Hao Rick Chang, Pavan Kumar Anasosalu Vasu, Cem Koc, Vaishaal Shankar, Oncel Tuzel
分类: cs.CL, cs.LG
发布日期: 2024-05-21 (更新: 2025-01-06)
备注: NeurIPS 2024
💡 一句话要点
提出数据集分解方法,通过变长序列训练加速LLM训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 变长序列训练 数据集分解 课程学习 长上下文 训练加速 自然语言处理
📋 核心要点
- 现有LLM训练方法concat-and-chunk效率低,固定长度序列忽略了文档的实际长度,且长序列注意力计算成本高昂。
- 论文提出数据集分解方法,将数据集分解为多个变长序列桶,并结合课程学习策略进行训练,降低计算成本。
- 实验结果表明,该方法在标准语言评估和长上下文基准测试中,训练速度提升高达6倍,性能显著提升。
📝 摘要(中文)
大型语言模型(LLM)通常在由固定长度token序列组成的数据集上进行训练。这些数据集通过随机连接不同长度的文档,然后将它们分块成预定的目标长度序列(concat-and-chunk)来创建。最近的注意力机制实现会屏蔽跨文档的注意力,从而降低了有效序列长度。此外,由于注意力的二次方成本,训练长序列在计算上变得非常昂贵。本文提出数据集分解,一种新的变长序列训练技术,以应对这些挑战。我们将数据集分解为多个桶的联合,每个桶包含从唯一文档中提取的相同大小的序列。在训练过程中,我们使用变长序列和batch size,同时从所有桶中进行课程学习采样。与concat-and-chunk基线相比,我们的方法在每一步训练中都会产生与实际文档长度成比例的计算成本,从而显著节省训练时间。我们以与使用基线方法训练的2k上下文长度模型相同的成本训练了一个8k上下文长度的1B模型。在网络规模语料库上的实验表明,我们的方法显著提高了标准语言评估和长上下文基准的性能,与基线相比,以高达6倍的速度更快地达到目标精度。我们的方法不仅能够有效地对长序列进行预训练,而且能够有效地扩展数据集大小。最后,我们阐明了训练大型语言模型的一个关键但较少研究的方面:序列长度的分布和课程学习,这导致了性能上的显著差异。
🔬 方法详解
问题定义:现有的大型语言模型训练方法,如concat-and-chunk,将不同长度的文档连接起来并分割成固定长度的序列。这种方法忽略了文档的实际长度,导致计算资源的浪费。此外,长序列的注意力机制计算复杂度是序列长度的平方,使得训练成本非常高昂。因此,如何高效地训练具有长上下文处理能力的大型语言模型是一个关键问题。
核心思路:论文的核心思路是根据文档的实际长度将数据集分解成多个桶,每个桶包含相同长度的序列。在训练过程中,采用变长序列和batch size,并结合课程学习策略,从不同的桶中进行采样。这样可以使得计算成本与文档的实际长度成比例,从而降低整体的训练成本。
技术框架:该方法主要包含以下几个阶段:1) 数据集分解:将原始数据集按照文档长度分解成多个桶,每个桶包含相同长度的序列。2) 课程学习采样:根据预定义的课程,从不同的桶中进行采样,构建训练batch。3) 模型训练:使用变长序列和batch size训练大型语言模型。4) 性能评估:在标准语言评估和长上下文基准测试中评估模型的性能。
关键创新:该方法最重要的创新点在于提出了数据集分解和变长序列训练的思想。通过将数据集分解成多个桶,并结合课程学习策略,可以有效地降低训练成本,并提高模型的性能。与传统的固定长度序列训练方法相比,该方法更加灵活和高效。
关键设计:在数据集分解阶段,需要确定桶的数量和每个桶的序列长度。在课程学习采样阶段,需要设计合适的采样策略,例如,可以从短序列开始,逐渐增加序列长度。在模型训练阶段,可以使用标准的Transformer架构,并采用Adam优化器进行优化。损失函数可以使用交叉熵损失函数。
🖼️ 关键图片

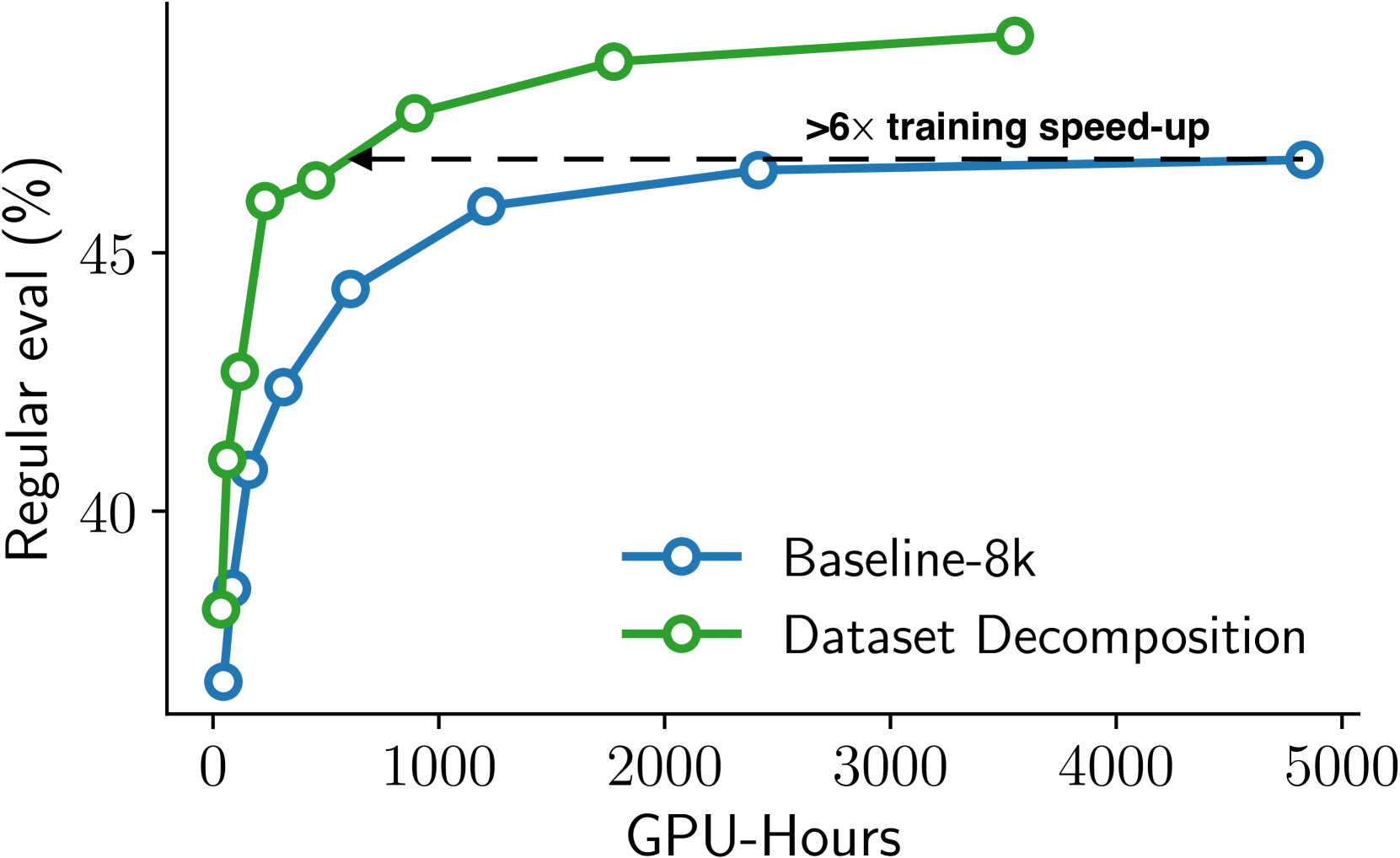

📊 实验亮点
实验结果表明,使用数据集分解方法训练的1B模型,在8k上下文长度下,达到了与使用传统方法训练的2k上下文长度模型相同的训练成本。同时,该方法在标准语言评估和长上下文基准测试中,训练速度提升高达6倍,性能显著提升,证明了该方法的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于需要处理长文本序列的自然语言处理任务中,例如机器翻译、文本摘要、问答系统等。通过更高效地训练具有长上下文处理能力的LLM,可以提升这些应用在处理复杂文本时的性能,并降低训练成本,加速LLM在各领域的普及。
📄 摘要(原文)
Large language models (LLMs) are commonly trained on datasets consisting of fixed-length token sequences. These datasets are created by randomly concatenating documents of various lengths and then chunking them into sequences of a predetermined target length (concat-and-chunk). Recent attention implementations mask cross-document attention, reducing the effective length of a chunk of tokens. Additionally, training on long sequences becomes computationally prohibitive due to the quadratic cost of attention. In this study, we introduce dataset decomposition, a novel variable sequence length training technique, to tackle these challenges. We decompose a dataset into a union of buckets, each containing sequences of the same size extracted from a unique document. During training, we use variable sequence length and batch-size, sampling simultaneously from all buckets with a curriculum. In contrast to the concat-and-chunk baseline, which incurs a fixed attention cost at every step of training, our proposed method incurs a computational cost proportional to the actual document lengths at each step, resulting in significant savings in training time. We train an 8k context-length 1B model at the same cost as a 2k context-length model trained with the baseline approach. Experiments on a web-scale corpus demonstrate that our approach significantly enhances performance on standard language evaluations and long-context benchmarks, reaching target accuracy with up to 6x faster training compared to the baseline. Our method not only enables efficient pretraining on long sequences but also scales effectively with dataset size. Lastly, we shed light on a critical yet less studied aspect of training large language models: the distribution and curriculum of sequence lengths, which results in a non-negligible difference in performance.