xFinder: Large Language Models as Automated Evaluators for Reliable Evaluation
作者: Qingchen Yu, Zifan Zheng, Shichao Song, Zhiyu Li, Feiyu Xiong, Bo Tang, Ding Chen
分类: cs.CL
发布日期: 2024-05-20 (更新: 2025-02-25)
备注: Accepted by ICLR 2025
💡 一句话要点
xFinder:利用大语言模型作为自动评估器,提升LLM评估的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 自动评估 答案提取 正则表达式 关键答案查找器
📋 核心要点
- 现有LLM评估框架依赖正则表达式进行答案提取,易受格式过拟合影响,且提取准确率有限,导致评估结果不可靠。
- xFinder通过训练小型语言模型来精确提取答案,避免了正则表达式的局限性,从而提升了答案提取的准确性和泛化能力。
- 实验表明,xFinder在答案提取和最终判断准确率上均优于现有评估框架和评判模型,显著提升了LLM评估的可靠性。
📝 摘要(中文)
大型语言模型(LLM)的持续发展使得开发公平可靠的评估方法变得至关重要。诸如测试集泄露和提示格式过拟合等作弊现象对LLM的可靠评估提出了重大挑战。现有的评估框架通常使用正则表达式(RegEx)进行答案提取,这可能导致模型调整其响应以适应RegEx易于处理的格式,但基于RegEx的关键答案提取模块经常出现提取错误。此外,最近提出的微调LLM作为自动评估的评判模型在泛化能力和公平性方面面临挑战。本文全面分析了整个LLM评估链,并证明优化关键答案提取模块可以提高提取准确率并增强评估可靠性。研究表明,改进关键答案提取模块可以带来更高的判断准确率和评估效率,优于评判模型。为此,我们提出了xFinder,一种用于LLM评估中答案提取和匹配的新型评估器。作为该过程的一部分,我们创建了一个专门的数据集,即关键答案查找器(KAF)数据集,以确保有效的模型训练和评估。泛化测试和真实评估表明,参数仅为5亿的最小xFinder模型实现了93.42%的平均提取准确率,而最佳评估框架中的RegEx准确率仅为74.38%。xFinder的最终判断准确率达到97.61%,优于现有的评估框架和评判模型。
🔬 方法详解
问题定义:现有LLM评估框架在答案提取环节存在问题。具体来说,框架通常使用正则表达式(RegEx)从模型的输出中提取关键答案,但RegEx容易出错,且模型可能会针对RegEx的格式进行优化,导致评估结果失真。此外,使用微调的LLM作为评判模型存在泛化能力和公平性问题。
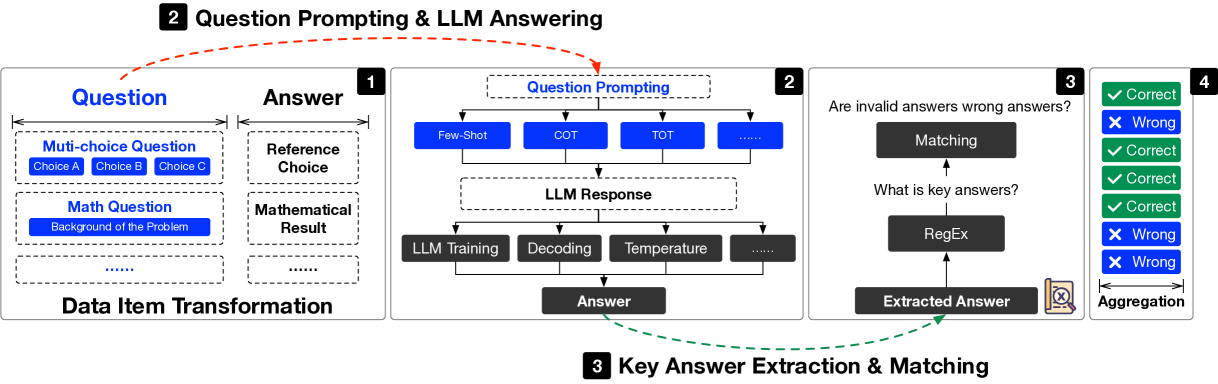
核心思路:xFinder的核心思路是将答案提取任务转化为一个序列标注问题,并利用小型语言模型学习如何从LLM的输出中准确提取关键答案。通过训练模型直接识别和提取答案,避免了RegEx的局限性,提高了提取的准确性和鲁棒性。
技术框架:xFinder的整体框架包括以下几个主要模块:1) 数据集构建:构建专门的关键答案查找器(KAF)数据集,用于训练和评估答案提取模型。2) 模型训练:使用KAF数据集训练小型语言模型,使其能够准确提取答案。3) 答案匹配:将提取的答案与标准答案进行匹配,判断LLM的回答是否正确。4) 评估:根据答案匹配结果,评估LLM的性能。
关键创新:xFinder最重要的技术创新在于使用小型语言模型进行答案提取,取代了传统的正则表达式方法。这种方法能够更好地处理复杂的文本结构和语义信息,从而提高提取的准确性和泛化能力。此外,KAF数据集的构建也为模型训练提供了高质量的数据支持。
关键设计:xFinder使用了一个参数量为5亿的小型语言模型。模型的训练目标是最大化答案提取的准确率。KAF数据集包含了多种类型的问答数据,覆盖了不同的领域和任务。在答案匹配阶段,xFinder使用了多种匹配策略,包括精确匹配、模糊匹配和语义匹配,以提高匹配的准确性。
🖼️ 关键图片


📊 实验亮点
xFinder在答案提取准确率和最终判断准确率上均取得了显著提升。实验结果表明,xFinder的平均提取准确率达到93.42%,而最佳评估框架中的RegEx准确率仅为74.38%。xFinder的最终判断准确率达到97.61%,优于现有的评估框架和评判模型。这些结果表明,xFinder能够更准确地评估LLM的性能。
🎯 应用场景
xFinder可应用于各种LLM的自动评估场景,例如模型开发、性能监控和基准测试。它能够提供更准确、更可靠的评估结果,帮助研究人员和开发者更好地了解LLM的性能,并进行有针对性的改进。此外,xFinder还可以用于检测LLM的作弊行为,例如测试集泄露和提示格式过拟合,从而维护LLM评估的公平性。
📄 摘要(原文)
The continuous advancement of large language models (LLMs) has brought increasing attention to the critical issue of developing fair and reliable methods for evaluating their performance. Particularly, the emergence of cheating phenomena, such as test set leakage and prompt format overfitting, poses significant challenges to the reliable evaluation of LLMs. As evaluation frameworks commonly use Regular Expression (RegEx) for answer extraction, models may adjust their responses to fit formats easily handled by RegEx. Nevertheless, the key answer extraction module based on RegEx frequently suffers from extraction errors. Furthermore, recent studies proposing fine-tuned LLMs as judge models for automated evaluation face challenges in terms of generalization ability and fairness. This paper comprehensively analyzes the entire LLM evaluation chain and demonstrates that optimizing the key answer extraction module improves extraction accuracy and enhances evaluation reliability. Our findings suggest that improving the key answer extraction module can lead to higher judgment accuracy and improved evaluation efficiency compared to the judge models. To address these issues, we propose xFinder, a novel evaluator for answer extraction and matching in LLM evaluation. As part of this process, we create a specialized dataset, the \textbf{K}ey \textbf{A}nswer \textbf{F}inder (KAF) dataset, to ensure effective model training and evaluation. Generalization tests and real-world evaluations show that the smallest xFinder model, with only 500 million parameters, achieves an average extraction accuracy of 93.42\%. In contrast, RegEx accuracy in the best evaluation framework is 74.38\%. The final judgment accuracy of xFinder reaches 97.61\%, outperforming existing evaluation frameworks and judge models.