Simple-Sampling and Hard-Mixup with Prototypes to Rebalance Contrastive Learning for Text Classification
作者: Mengyu Li, Yonghao Liu, Fausto Giunchiglia, Ximing Li, Xiaoyue Feng, Renchu Guan
分类: cs.CL
发布日期: 2024-05-19 (更新: 2026-01-23)
备注: WWW26
💡 一句话要点
提出SharpReCL模型,通过原型采样和Hard-Mixup重平衡对比学习,解决文本分类中的数据不平衡问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分类 对比学习 数据不平衡 原型学习 样本重平衡 Hard-Mixup 深度学习
📋 核心要点
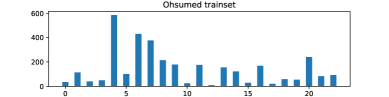
- 监督对比学习在文本分类中表现出色,但其学习机制对数据不平衡敏感,导致模型性能下降。
- SharpReCL模型通过平衡分类分支获取原型向量,并以此构建各类别的目标样本集,从而进行监督对比学习。
- 实验结果表明,SharpReCL模型在不平衡文本分类任务中表现出色,甚至超越了大型语言模型。
📝 摘要(中文)
本文针对Web内容挖掘中重要的文本分类任务,提出了一种名为SharpReCL的新模型,旨在解决监督对比学习在处理不平衡文本数据集时性能下降的问题。该模型利用平衡分类分支中每个类别的原型向量作为该类别的代表。通过显式地利用这些原型向量,模型构建了一个适当且充分的目标样本集,每个类别的大小相同,从而执行监督对比学习过程。实验结果表明,该模型有效,甚至在多个数据集上优于流行的大型语言模型。
🔬 方法详解
问题定义:现有的监督对比学习方法在处理不平衡文本分类数据集时,由于各类别样本数量差异大,模型容易偏向多数类,导致少数类的特征学习不充分,最终影响整体分类性能。此外,现有模型通常将交叉熵损失和监督对比学习分支独立使用,缺乏显式的互指导机制。
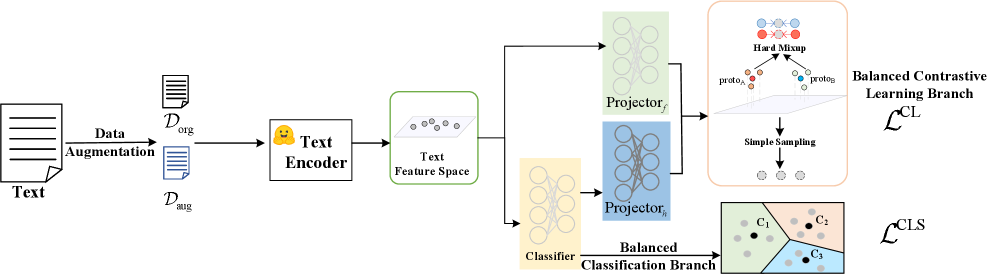
核心思路:论文的核心思路是利用原型向量来平衡各类别样本,从而缓解数据不平衡带来的问题。具体来说,首先通过一个平衡的分类分支学习每个类别的原型向量,该向量可以视为该类别的代表性特征。然后,利用这些原型向量,为每个类别构建一个大小相同的目标样本集,用于后续的监督对比学习。
技术框架:SharpReCL模型包含两个主要分支:一个平衡分类分支和一个监督对比学习分支。平衡分类分支用于学习每个类别的原型向量。监督对比学习分支则利用原型向量构建的目标样本集进行对比学习,从而学习更鲁棒的特征表示。两个分支通过共享底层特征提取器来实现信息共享。
关键创新:该论文的关键创新在于提出了基于原型向量的样本重平衡方法。通过原型向量,可以为每个类别构建一个大小相同的目标样本集,从而有效地缓解数据不平衡问题。此外,论文还提出了Hard-Mixup策略,通过混合原型向量和真实样本,进一步增强模型的泛化能力。
关键设计:模型使用交叉熵损失函数训练平衡分类分支,以获得准确的原型向量。监督对比学习分支使用标准的对比损失函数,但其输入是基于原型向量构建的目标样本集。Hard-Mixup策略通过随机选择原型向量和真实样本进行线性组合来生成新的样本。论文中没有明确说明具体的参数设置和网络结构细节,这部分信息可能需要在代码中查看。
🖼️ 关键图片
📊 实验亮点
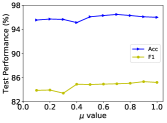
实验结果表明,SharpReCL模型在多个不平衡文本分类数据集上取得了显著的性能提升,甚至超越了流行的大型语言模型。具体的性能数据和对比基线需要在论文中查找。该模型在不平衡数据集上的优越表现验证了基于原型向量的样本重平衡方法的有效性。
🎯 应用场景
该研究成果可广泛应用于各种存在数据不平衡问题的文本分类场景,例如情感分析、垃圾邮件检测、欺诈检测、医学文本分类等。通过提升模型在不平衡数据集上的性能,可以更有效地识别和处理少数类别的样本,具有重要的实际应用价值和社会意义。未来可以进一步探索将该方法应用于其他类型的数据和任务。
📄 摘要(原文)
Text classification is a crucial and fundamental task in web content mining. Compared with the previous learning paradigm of pre-training and fine-tuning by cross entropy loss, the recently proposed supervised contrastive learning approach has received tremendous attention due to its powerful feature learning capability and robustness. Although several studies have incorporated this technique for text classification, some limitations remain. First, many text datasets are imbalanced, and the learning mechanism of supervised contrastive learning is sensitive to data imbalance, which may harm the model's performance. Moreover, these models leverage separate classification branches with cross entropy and supervised contrastive learning branches without explicit mutual guidance. To this end, we propose a novel model named SharpReCL for imbalanced text classification tasks. First, we obtain the prototype vector of each class in the balanced classification branch to act as a representation of each class. Then, by further explicitly leveraging the prototype vectors, we construct a proper and sufficient target sample set with the same size for each class to perform the supervised contrastive learning procedure. The empirical results show the effectiveness of our model, which even outperforms popular large language models across several datasets. Our code is available here.