MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation
作者: Jianbo Dai, Jianqiao Lu, Yunlong Feng, Guangtao Zeng, Rongju Ruan, Ming Cheng, Dong Huang, Haochen Tan, Zhijiang Guo
分类: cs.CL
发布日期: 2024-05-19 (更新: 2025-08-16)
备注: 43 pages, dataset and code are available at https://github.com/SparksofAGI/MHPP, leaderboard can be found at https://sparksofagi.github.io/MHPP/
🔗 代码/项目: GITHUB
💡 一句话要点
提出MHPP数据集,用于更全面评估语言模型在复杂Python代码生成中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 基准测试 Python编程 自然语言理解
📋 核心要点
- 现有代码生成基准(如HumanEval和MBPP)在评估LLM的函数级代码生成能力方面存在质量、难度和粒度上的局限性。
- 提出MHPP数据集,包含210个由人工设计的Python难题,侧重于自然语言理解、代码推理和多步逻辑推理。
- 实验表明,在HumanEval上表现良好的LLM在MHPP上表现不佳,MHPP能够有效揭示LLM在代码生成方面的潜在局限性。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成方面取得了显著进展,例如GPT-4o在HumanEval上的通过率达到91.0%。然而,现有基准测试在全面评估函数级代码生成能力方面可能存在不足。本研究分析了HumanEval和MBPP两个常用基准,发现它们在质量、难度和粒度方面存在局限性,可能无法充分评估LLM的代码生成能力。为了解决这个问题,我们引入了Mostly Hard Python Problems(MHPP)数据集,它包含210个独特的人工设计的难题。MHPP侧重于自然语言和代码推理的结合,旨在衡量LLM理解规范和约束、进行多步推理以及有效应用编码知识的能力。对26个LLM的初步评估表明,在HumanEval上表现出色的许多模型在MHPP上未能取得类似的成功。此外,MHPP揭示了各种LLM中先前未被发现的局限性,这使我们相信它可以为更好地理解LLM的能力和局限性铺平道路。MHPP、评估流程和排行榜可在https://github.com/SparksofAGI/MHPP找到。
🔬 方法详解
问题定义:现有代码生成基准(如HumanEval和MBPP)无法充分评估LLM在复杂场景下的代码生成能力。这些基准在题目质量、难度和粒度上存在不足,难以区分LLM在理解复杂约束、进行多步推理和应用编码知识方面的能力。现有方法难以有效衡量LLM在处理需要深度推理和复杂逻辑的Python编程问题时的真实水平。
核心思路:MHPP数据集的核心思路是提供一组更具挑战性的Python编程问题,这些问题需要LLM具备更强的自然语言理解能力、代码推理能力和多步逻辑推理能力。通过增加问题的难度和复杂性,MHPP旨在更全面地评估LLM在实际编程场景中的表现。这种设计能够更好地揭示LLM在处理复杂任务时的局限性,从而推动LLM代码生成能力的进一步发展。
技术框架:MHPP数据集包含210个独特的人工设计的Python编程问题。每个问题都包含自然语言描述和相应的代码实现要求。评估流程包括:1)将问题输入LLM;2)LLM生成代码;3)使用预定义的测试用例评估生成的代码;4)根据代码的正确性计算得分。研究团队还提供了一个在线排行榜,用于比较不同LLM在MHPP上的表现。
关键创新:MHPP的关键创新在于其问题设计的难度和复杂性。与现有基准相比,MHPP中的问题更侧重于自然语言理解和代码推理的结合,需要LLM进行多步推理才能解决。此外,MHPP还引入了更多的约束条件和限制,以模拟实际编程场景中的复杂性。这种设计使得MHPP能够更有效地评估LLM在处理复杂编程问题时的能力。
关键设计:MHPP的问题设计遵循以下原则:1)问题应该具有一定的难度,能够区分不同LLM的能力;2)问题应该具有一定的多样性,覆盖不同的编程领域和算法;3)问题应该具有明确的描述和测试用例,方便评估LLM生成的代码。此外,MHPP还提供了一个评估脚本,用于自动评估LLM生成的代码,并计算相应的得分。
🖼️ 关键图片
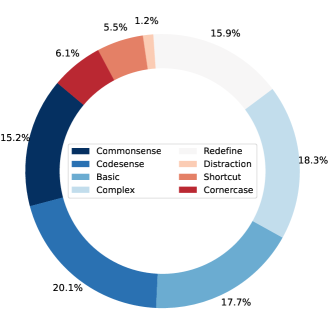

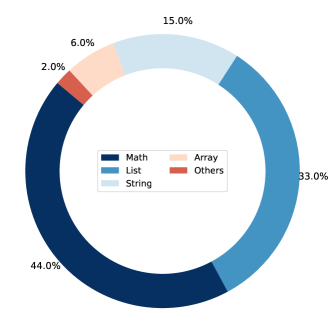
📊 实验亮点
对26个LLM的评估结果表明,在HumanEval上表现出色的许多模型在MHPP上未能取得类似的成功,这表明现有基准可能无法充分评估LLM的代码生成能力。例如,一些在HumanEval上达到较高通过率的模型在MHPP上的通过率显著下降。MHPP能够有效揭示LLM在处理复杂编程问题时的局限性,为未来的研究提供了新的方向。
🎯 应用场景
MHPP数据集可用于评估和比较不同LLM的代码生成能力,帮助研究人员更好地理解LLM的优势和局限性。此外,MHPP还可以用于指导LLM的训练和优化,提高其在复杂编程任务中的表现。该数据集的发布将促进代码生成领域的研究和发展,并推动LLM在软件开发、自动化测试等领域的应用。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have greatly improved code generation, specifically at the function level. For instance, GPT-4o has achieved a 91.0\% pass rate on HumanEval. However, this draws into question the adequacy of existing benchmarks in thoroughly assessing function-level code generation capabilities. Our study analyzed two common benchmarks, HumanEval and MBPP, and found that these might not thoroughly evaluate LLMs' code generation capacities due to limitations in quality, difficulty, and granularity. To resolve this, we introduce the Mostly Hard Python Problems (MHPP) dataset, consisting of 210 unique human-curated problems. By focusing on the combination of natural language and code reasoning, MHPP gauges LLMs' abilities to comprehend specifications and restrictions, engage in multi-step reasoning, and apply coding knowledge effectively. Initial evaluations of 26 LLMs using MHPP showed many high-performing models on HumanEval failed to achieve similar success on MHPP. Moreover, MHPP highlighted various previously undiscovered limitations within various LLMs, leading us to believe that it could pave the way for a better understanding of LLMs' capabilities and limitations. MHPP, evaluation pipeline, and leaderboard can be found in https://github.com/SparksofAGI/MHPP.