MBIAS: Mitigating Bias in Large Language Models While Retaining Context
作者: Shaina Raza, Ananya Raval, Veronica Chatrath
分类: cs.CL
发布日期: 2024-05-18 (更新: 2024-06-28)
🔗 代码/项目: GITHUB
💡 一句话要点
MBIAS:在保留上下文的同时减轻大型语言模型中的偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见缓解 指令微调 安全性 公平性 毒性检测 上下文保留
📋 核心要点
- 现有大型语言模型在安全微调或对抗测试中,往往牺牲上下文信息以换取安全性,无法有效处理细微的偏见和毒性。
- MBIAS通过在定制的安全干预数据集上进行指令微调,旨在减少LLM输出中的偏见和毒性,同时保留关键信息。
- 实验结果表明,MBIAS在标准评估中将偏见和毒性降低了30%以上,在多样化的人口统计测试中降低了90%以上。
📝 摘要(中文)
大型语言模型(LLMs)在各种应用中的部署需要确保安全性,同时不损害生成内容的上下文完整性。传统的安全方法,如安全微调或对抗性测试,通常以牺牲上下文含义为代价来产生安全输出,导致处理细微偏见和毒性的能力下降,例如对不同人群的代表性不足或负面描述。为了解决这些挑战,我们引入了MBIAS,这是一个LLM框架,通过在专门为安全干预设计的自定义数据集上进行指令微调。MBIAS旨在显著减少LLM输出中的偏见和毒性元素,同时保留主要信息。这项工作还详细介绍了我们进一步使用LLM作为人工监督下的注释器和生成内容的评估器。实证分析表明,MBIAS在标准评估中将偏见和毒性降低了30%以上,在各种人口统计测试中降低了90%以上,突出了我们方法的稳健性。我们将数据集和微调模型提供给研究社区,以供进一步研究,并确保可重复性。该项目的代码可以在https://github.com/shainarazavi/MBIAS/tree/main 访问。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在生成内容时存在的偏见和毒性问题。现有方法,如安全微调或对抗性测试,虽然可以提高安全性,但往往会损害生成内容的上下文完整性,降低模型处理细微偏见和毒性的能力。这些方法无法很好地处理对不同人群的代表性不足或负面描述等问题。
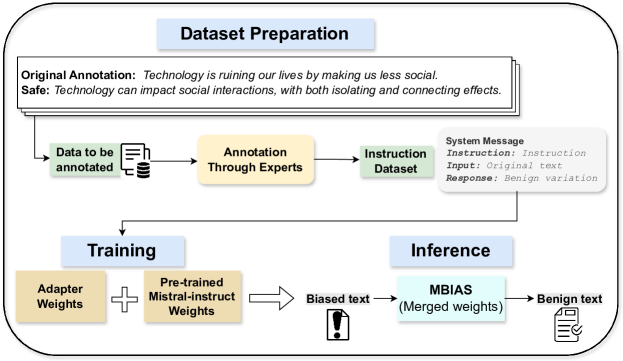
核心思路:MBIAS的核心思路是通过指令微调,使LLM能够更好地理解和处理与偏见和毒性相关的问题。通过构建一个专门为安全干预设计的自定义数据集,并在此数据集上对LLM进行微调,MBIAS旨在让模型学习如何在生成内容时避免偏见和毒性,同时保留主要信息。这种方法避免了传统方法中牺牲上下文信息以换取安全性的问题。
技术框架:MBIAS框架主要包含以下几个阶段:1)构建自定义数据集,该数据集包含各种与偏见和毒性相关的情境和指令;2)使用该数据集对LLM进行指令微调,使其能够更好地理解和处理与偏见和毒性相关的问题;3)使用LLM作为人工监督下的注释器,进一步改进数据集的质量;4)使用LLM作为评估器,评估生成内容的偏见和毒性程度。
关键创新:MBIAS的关键创新在于其指令微调方法和自定义数据集的设计。与传统的安全微调方法不同,MBIAS的指令微调更加注重保留上下文信息,避免牺牲生成内容的质量。自定义数据集的设计也更加注重覆盖各种与偏见和毒性相关的情境,使模型能够更好地学习如何避免这些问题。此外,利用LLM作为注释器和评估器也提高了数据质量和评估效率。
关键设计:论文中没有明确给出关键的参数设置、损失函数、网络结构等技术细节。但是,可以推断,指令微调过程中会使用标准的交叉熵损失函数,并可能采用一些正则化技术来防止过拟合。数据集的构建可能涉及多种数据增强技术,以增加数据的多样性和覆盖范围。具体的网络结构取决于所使用的LLM模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MBIAS在减少偏见和毒性方面取得了显著效果。在标准评估中,MBIAS将偏见和毒性降低了30%以上。在多样化的人口统计测试中,MBIAS将偏见和毒性降低了90%以上。这些结果表明,MBIAS是一种有效的减轻LLM偏见和毒性的方法,并且具有良好的泛化能力。
🎯 应用场景
MBIAS可应用于各种需要生成文本的场景,例如聊天机器人、内容创作、机器翻译等。通过减少LLM输出中的偏见和毒性,MBIAS可以提高这些应用的安全性、公平性和可靠性,避免产生歧视性或冒犯性的内容。该研究有助于推动LLM在更广泛领域的应用,并促进人工智能技术的负责任发展。
📄 摘要(原文)
The deployment of Large Language Models (LLMs) in diverse applications necessitates an assurance of safety without compromising the contextual integrity of the generated content. Traditional approaches, including safety-specific fine-tuning or adversarial testing, often yield safe outputs at the expense of contextual meaning. This can result in a diminished capacity to handle nuanced aspects of bias and toxicity, such as underrepresentation or negative portrayals across various demographics. To address these challenges, we introduce MBIAS, an LLM framework carefully instruction fine-tuned on a custom dataset designed specifically for safety interventions. MBIAS is designed to significantly reduce biases and toxic elements in LLM outputs while preserving the main information. This work also details our further use of LLMs: as annotator under human supervision and as evaluator of generated content. Empirical analysis reveals that MBIAS achieves a reduction in bias and toxicity by over 30\% in standard evaluations, and by more than 90\% in diverse demographic tests, highlighting the robustness of our approach. We make the dataset and the fine-tuned model available to the research community for further investigation and ensure reproducibility. The code for this project can be accessed here https://github.com/shainarazavi/MBIAS/tree/main. Warning: This paper contains examples that may be offensive or upsetting.