AudioSetMix: Enhancing Audio-Language Datasets with LLM-Assisted Augmentations
作者: David Xu
分类: eess.AS, cs.CL, cs.MM, cs.SD
发布日期: 2024-05-17 (更新: 2024-06-07)
备注: typos corrected
💡 一句话要点
提出AudioSetMix,利用LLM增强音频-语言数据集,提升模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频语言学习 多模态学习 数据增强 大型语言模型 AudioSet 音频信号处理 困难负样本
📋 核心要点
- 现有音频-语言数据集规模小、质量低,且人工标注成本高,限制了模型性能。
- 利用大型语言模型,通过音频增强和文本描述生成高质量的音频-文本对数据集AudioSetMix。
- AudioSetMix包含更多修饰语,并生成困难负样本,显著提升了模型在多个基准测试上的性能。
📝 摘要(中文)
近年来,音频-语言领域的多模态学习取得了显著进展。然而,与图像-语言任务相比,音频-语言学习面临着数据量有限和质量较低的挑战。现有的音频-语言数据集规模明显较小,并且手动标注需要收听整个音频片段才能进行准确标注,这阻碍了标注效率。本文提出了一种系统地生成音频-文本对的方法,通过使用自然语言标签和相应的音频信号处理操作来增强音频片段。利用大型语言模型,我们使用提示模板生成增强音频片段的描述。这种可扩展的方法生成了AudioSetMix,这是一个用于文本和音频相关模型的高质量训练数据集。集成我们的数据集通过提供多样化和更好对齐的示例来提高模型在基准测试中的性能。值得注意的是,我们的数据集解决了现有数据集中缺乏修饰语(形容词和副词)的问题。通过使模型能够学习这些概念,并在训练期间生成困难负样本,我们在多个基准测试中实现了最先进的性能。
🔬 方法详解
问题定义:现有音频-语言数据集规模较小,数据质量不高,且缺乏修饰语,限制了模型对细粒度音频信息的理解能力。人工标注成本高,难以扩展数据集规模。
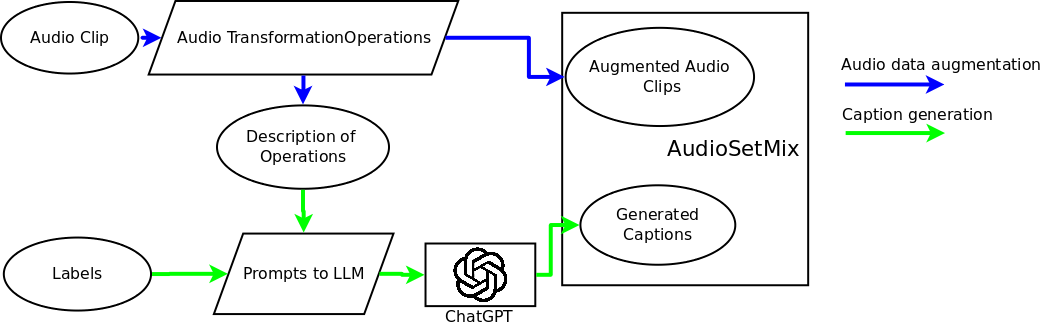
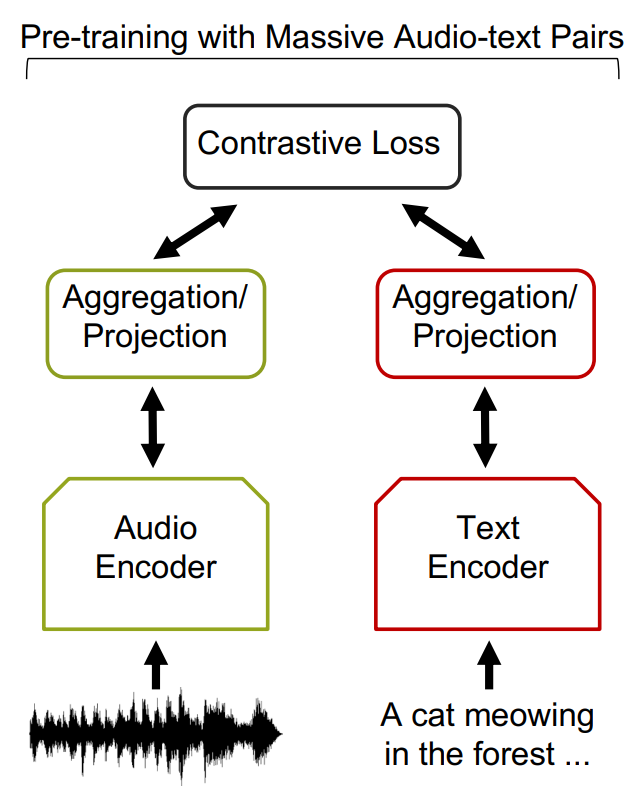
核心思路:利用大型语言模型(LLM)的强大文本生成能力,结合音频信号处理技术,自动生成高质量的音频-文本对。通过对原始音频进行增强,并使用LLM生成对应的文本描述,从而扩展数据集,并引入更多修饰语。
技术框架:该方法主要包含以下几个阶段:1) 音频增强:对原始音频片段应用各种音频信号处理操作,例如添加噪声、改变音调、调整音量等。2) 文本生成:使用预定义的提示模板,结合原始音频的标签和增强操作的信息,输入到LLM中,生成对应的文本描述。3) 数据集构建:将增强后的音频片段和生成的文本描述组成新的音频-文本对,添加到AudioSetMix数据集中。4) 困难负样本生成:通过特定的策略,生成与正样本相似但语义不同的负样本,用于提升模型的区分能力。
关键创新:该方法的核心创新在于利用LLM自动生成高质量的音频-文本对,从而克服了人工标注的局限性。通过音频增强和提示工程,使得生成的数据集包含更多样化的音频信息和更丰富的文本描述,特别是引入了现有数据集中缺乏的修饰语。
关键设计:提示模板的设计至关重要,需要包含原始音频的标签、增强操作的信息以及上下文信息,以引导LLM生成准确且相关的文本描述。困难负样本的生成策略也需要仔细设计,以保证负样本与正样本具有一定的相似性,从而提升模型的学习难度和泛化能力。具体的音频增强操作的选择和参数设置也需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
AudioSetMix数据集的引入显著提升了模型在音频-语言任务上的性能。实验结果表明,在多个基准测试中,使用AudioSetMix训练的模型取得了state-of-the-art的性能。尤其是在需要理解细粒度音频信息的任务上,提升幅度更为明显,验证了该方法的有效性。
🎯 应用场景
该研究成果可广泛应用于音频内容理解、语音助手、智能音乐推荐、声音事件检测等领域。通过提升模型对音频和文本之间关系的理解能力,可以改善语音搜索、音频字幕生成、以及基于音频的智能交互体验。未来,该方法可以扩展到其他多模态学习任务中,例如视频-文本、图像-音频等。
📄 摘要(原文)
Multi-modal learning in the audio-language domain has seen significant advancements in recent years. However, audio-language learning faces challenges due to limited and lower-quality data compared to image-language tasks. Existing audio-language datasets are notably smaller, and manual labeling is hindered by the need to listen to entire audio clips for accurate labeling. Our method systematically generates audio-caption pairs by augmenting audio clips with natural language labels and corresponding audio signal processing operations. Leveraging a Large Language Model, we generate descriptions of augmented audio clips with a prompt template. This scalable method produces AudioSetMix, a high-quality training dataset for text-and-audio related models. Integration of our dataset improves models performance on benchmarks by providing diversified and better-aligned examples. Notably, our dataset addresses the absence of modifiers (adjectives and adverbs) in existing datasets. By enabling models to learn these concepts, and generating hard negative examples during training, we achieve state-of-the-art performance on multiple benchmarks.