Prompt Exploration with Prompt Regression
作者: Michael Feffer, Ronald Xu, Yuekai Sun, Mikhail Yurochkin
分类: cs.CL, cs.LG
发布日期: 2024-05-17 (更新: 2024-08-26)
备注: COLM 2024
💡 一句话要点
提出PEPR框架,通过提示回归预测提示组合效果,提升大语言模型提示工程效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 提示工程 提示回归 提示组合 模型预测
📋 核心要点
- 现有LLM提示工程主要依赖人工试错,缺乏系统性方法,难以高效地找到最优提示。
- PEPR框架通过提示回归预测提示组合效果,利用单个提示元素的结果来指导提示选择。
- 实验结果表明,该方法在不同大小的开源LLM和多个任务上均有效,提升了提示工程效率。
📝 摘要(中文)
随着大型语言模型(LLMs)的普及,人们越来越希望将LLM提示创建和选择过程系统化,而不仅仅是迭代试错。现有工作主要集中在搜索提示空间,而没有考虑提示变体之间的关系。本文提出了一个框架,即Prompt Exploration with Prompt Regression (PEPR),用于预测提示组合的效果,该框架基于单个提示元素的结果以及一种简单的方法来为给定的用例选择有效的提示。我们使用不同大小的开源LLM在几个不同的任务上评估了我们的方法。
🔬 方法详解
问题定义:现有的大语言模型提示工程主要依赖于人工迭代和试错,缺乏一种系统化的方法来探索和选择最佳的提示。这种方式效率低下,并且难以保证找到全局最优的提示组合。现有的方法主要集中在搜索提示空间,而忽略了不同提示变体之间的关系,无法有效地利用已有的提示信息。
核心思路:PEPR的核心思路是利用提示回归来预测提示组合的效果。它假设提示组合的效果可以通过对单个提示元素的效果进行回归分析来预测。通过这种方式,可以避免对所有可能的提示组合进行穷举搜索,从而提高提示工程的效率。
技术框架:PEPR框架主要包含两个阶段:提示探索阶段和提示回归阶段。在提示探索阶段,首先对单个提示元素进行评估,获取它们的效果数据。然后,在提示回归阶段,利用这些数据训练一个回归模型,该模型能够预测提示组合的效果。最后,利用该模型选择最佳的提示组合。整体流程是先分析单个提示的性能,然后利用这些信息预测组合提示的性能。
关键创新:PEPR的关键创新在于提出了利用提示回归来预测提示组合效果的思想。与现有方法相比,PEPR能够有效地利用单个提示元素的信息,避免了对整个提示空间进行盲目搜索。此外,PEPR还提供了一种简单的方法来选择有效的提示,从而简化了提示工程的流程。
关键设计:PEPR框架中,提示回归模型的选择是关键设计之一。论文中使用了简单的线性回归模型,但也可以根据具体任务选择更复杂的模型。另一个关键设计是提示元素的划分方式,需要根据任务的特点进行合理的划分,以保证回归模型的预测精度。损失函数通常采用均方误差等回归任务常用的损失函数。
🖼️ 关键图片

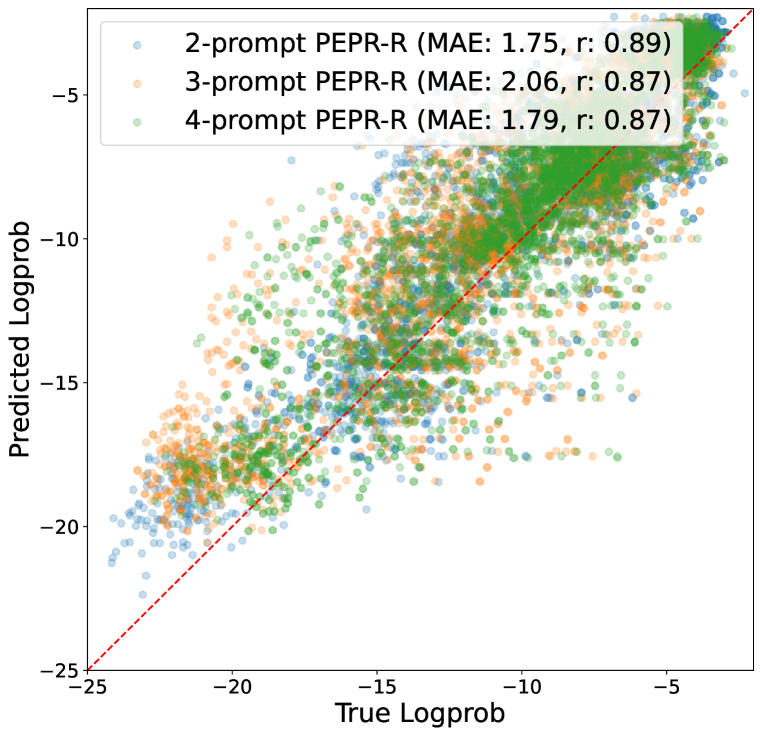
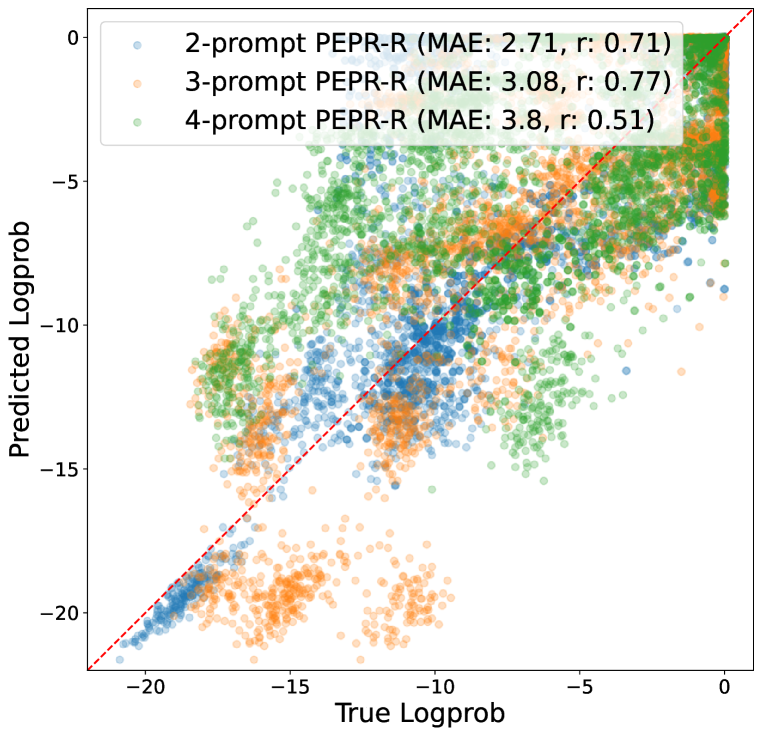
📊 实验亮点
论文在不同大小的开源LLM和多个任务上进行了实验评估,证明了PEPR框架的有效性。实验结果表明,PEPR能够有效地预测提示组合的效果,并选择出性能优异的提示。具体的性能数据和对比基线在论文中有详细描述,展示了PEPR相对于现有方法的优势。
🎯 应用场景
PEPR框架可应用于各种需要使用大语言模型的场景,例如文本生成、问答系统、机器翻译等。它可以帮助用户更高效地创建和选择有效的提示,从而提高LLM的性能和应用效果。该研究有助于推动LLM在实际应用中的普及和发展,降低LLM的使用门槛。
📄 摘要(原文)
In the advent of democratized usage of large language models (LLMs), there is a growing desire to systematize LLM prompt creation and selection processes beyond iterative trial-and-error. Prior works majorly focus on searching the space of prompts without accounting for relations between prompt variations. Here we propose a framework, Prompt Exploration with Prompt Regression (PEPR), to predict the effect of prompt combinations given results for individual prompt elements as well as a simple method to select an effective prompt for a given use-case. We evaluate our approach with open-source LLMs of different sizes on several different tasks.