From Generalist to Specialist: Improving Large Language Models for Medical Physics Using ARCoT
作者: Jace Grandinetti, Rafe McBeth
分类: cs.CL, physics.med-ph
发布日期: 2024-05-17
备注: 8 pages, 3 figures, 1 table
💡 一句话要点
ARCoT框架提升大语言模型在医学物理领域的专业性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 医学物理 检索增强 思维链 领域知识 专业领域 提示工程
📋 核心要点
- 现有LLM在医学物理等专业领域应用受限,缺乏领域知识导致性能不足。
- ARCoT框架通过检索领域知识和思维链提示,提升LLM的专业领域准确性。
- 实验表明,ARCoT在医学物理考试中显著优于标准LLM,达到人类平均水平。
📝 摘要(中文)
大型语言模型(LLM)取得了显著进展,但由于需要特定领域的知识,它们在医学物理等专业领域的应用仍然具有挑战性。本研究介绍了一种名为ARCoT(Adaptable Retrieval-based Chain of Thought,自适应检索式思维链)的框架,旨在提高LLM的领域特定准确性,而无需进行微调或大量重新训练。ARCoT集成了一种检索机制,用于访问相关的领域特定信息,并采用step-back和思维链提示技术来指导LLM的推理过程,从而确保更准确和上下文感知的响应。在医学物理选择题考试中进行的基准测试表明,我们的模型优于标准LLM,并报告了平均人类水平的性能,性能提升高达68%,并获得了90分的高分。该方法减少了幻觉并提高了领域特定性能。ARCoT的多功能性和模型无关性使其易于适应各种领域,展示了其在提高LLM在专业领域中的准确性和可靠性方面的巨大潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在医学物理等专业领域应用时,由于缺乏领域特定知识而导致的性能不足问题。现有方法,如直接使用通用LLM,往往无法提供准确和可靠的答案,容易产生“幻觉”现象,影响实际应用。
核心思路:论文的核心思路是利用检索增强和思维链提示,使LLM能够访问和利用领域相关的知识,并引导其进行更深入和更合理的推理。通过检索相关信息,LLM可以避免依赖自身可能不准确或不完整的知识,从而提高答案的准确性。思维链提示则帮助LLM逐步分解问题,进行逻辑推理,减少错误。
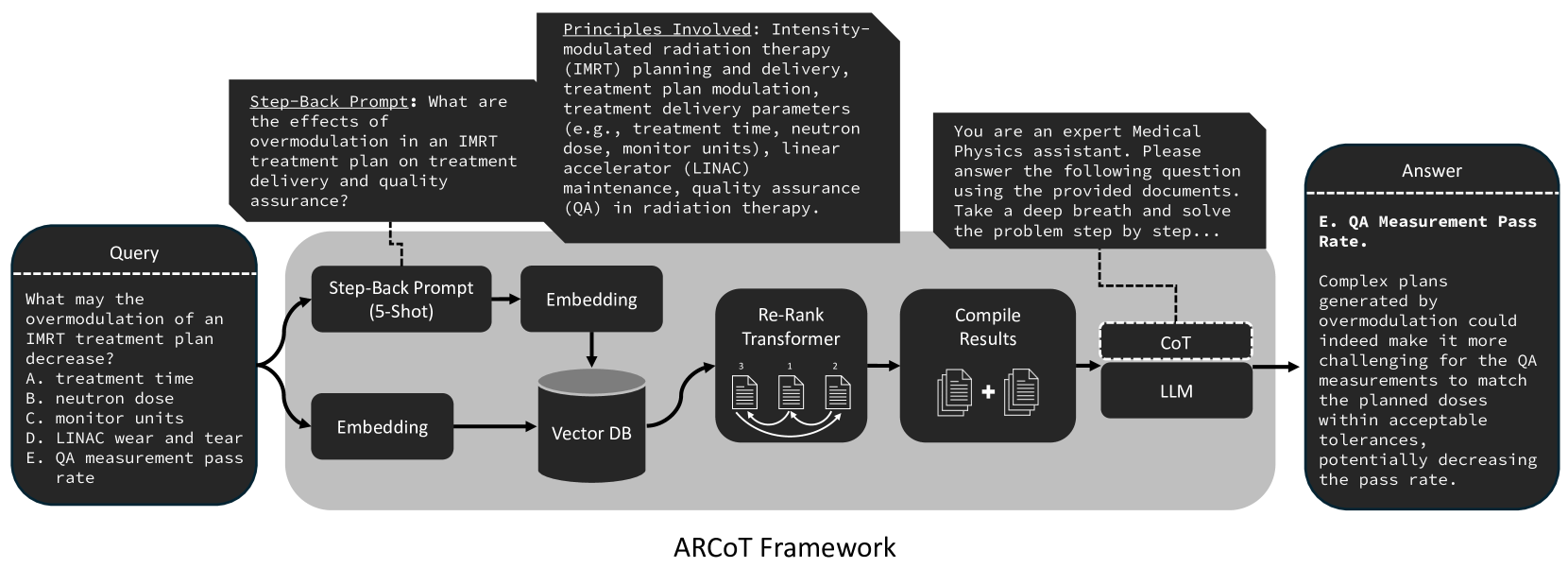
技术框架:ARCoT框架主要包含以下几个模块:1) 检索模块:根据输入问题,从领域知识库中检索相关信息。2) Step-Back Prompting模块:通过提出更一般性的问题,帮助LLM理解问题的本质。3) Chain-of-Thought Prompting模块:引导LLM逐步推理,生成中间步骤,最终得出答案。4) LLM推理模块:利用LLM进行推理和生成答案。
关键创新:ARCoT的关键创新在于将检索增强和思维链提示相结合,并将其应用于专业领域。与传统的微调方法相比,ARCoT无需对LLM进行大量训练,即可显著提高其在特定领域的性能。此外,ARCoT框架具有模型无关性,可以应用于不同的LLM。
关键设计:ARCoT的关键设计包括:1) 领域知识库的构建:需要构建一个包含医学物理领域相关知识的知识库,用于检索。2) 检索策略:需要设计有效的检索策略,以确保检索到与问题最相关的信息。3) Prompt的设计:需要精心设计Step-Back Prompting和Chain-of-Thought Prompting,以引导LLM进行有效的推理。论文中使用了医学物理选择题作为测试用例,并针对该用例设计了相应的Prompt。
🖼️ 关键图片

📊 实验亮点
ARCoT在医学物理选择题考试中表现出色,显著优于标准LLM。实验结果显示,ARCoT的性能提升高达68%,并达到了人类平均水平,获得了90分的高分。这表明ARCoT能够有效提高LLM在专业领域的准确性和可靠性,减少“幻觉”现象。
🎯 应用场景
ARCoT框架可广泛应用于需要专业知识的领域,例如医疗诊断、法律咨询、金融分析等。通过集成领域知识和推理能力,ARCoT可以帮助LLM提供更准确、可靠的答案,从而提高工作效率和决策质量。未来,ARCoT有望成为各行业智能化升级的重要工具。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable progress, yet their application in specialized fields, such as medical physics, remains challenging due to the need for domain-specific knowledge. This study introduces ARCoT (Adaptable Retrieval-based Chain of Thought), a framework designed to enhance the domain-specific accuracy of LLMs without requiring fine-tuning or extensive retraining. ARCoT integrates a retrieval mechanism to access relevant domain-specific information and employs step-back and chain-of-thought prompting techniques to guide the LLM's reasoning process, ensuring more accurate and context-aware responses. Benchmarking on a medical physics multiple-choice exam, our model outperformed standard LLMs and reported average human performance, demonstrating improvements of up to 68% and achieving a high score of 90%. This method reduces hallucinations and increases domain-specific performance. The versatility and model-agnostic nature of ARCoT make it easily adaptable to various domains, showcasing its significant potential for enhancing the accuracy and reliability of LLMs in specialized fields.