INDUS: Effective and Efficient Language Models for Scientific Applications
作者: Bishwaranjan Bhattacharjee, Aashka Trivedi, Masayasu Muraoka, Muthukumaran Ramasubramanian, Takuma Udagawa, Iksha Gurung, Nishan Pantha, Rong Zhang, Bharath Dandala, Rahul Ramachandran, Manil Maskey, Kaylin Bugbee, Mike Little, Elizabeth Fancher, Irina Gerasimov, Armin Mehrabian, Lauren Sanders, Sylvain Costes, Sergi Blanco-Cuaresma, Kelly Lockhart, Thomas Allen, Felix Grezes, Megan Ansdell, Alberto Accomazzi, Yousef El-Kurdi, Davis Wertheimer, Birgit Pfitzmann, Cesar Berrospi Ramis, Michele Dolfi, Rafael Teixeira de Lima, Panagiotis Vagenas, S. Karthik Mukkavilli, Peter Staar, Sanaz Vahidinia, Ryan McGranaghan, Tsendgar Lee
分类: cs.CL, cs.IR
发布日期: 2024-05-17 (更新: 2024-10-30)
备注: EMNLP 2024 (Industry Track)
💡 一句话要点
INDUS:针对科学应用的高效语言模型,优于通用和领域特定模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 领域特定模型 科学应用 信息检索 知识蒸馏
📋 核心要点
- 通用领域LLM在NLP任务中表现出色,但领域特定LLM在专业任务上更具优势。
- INDUS模型套件针对多个科学领域,利用领域特定语料库训练,包含编码器、文本嵌入和蒸馏模型。
- INDUS在新建的科学基准数据集和现有任务上,均超越了通用和领域特定模型,并在工业界得到应用。
📝 摘要(中文)
本文介绍了INDUS,一套为地球科学、生物学、物理学、太阳物理学、行星科学和天体物理学等领域量身定制的大型语言模型(LLM)。INDUS使用来自不同数据源的精选科学语料库进行训练。该模型套件包括:(1)使用领域特定词汇和语料库训练的编码器模型,用于处理NLP任务;(2)基于对比学习的文本嵌入模型,使用多样化的数据集进行训练,用于处理信息检索任务;(3)使用知识蒸馏创建的较小版本模型,适用于具有延迟或资源约束的应用。此外,还创建了三个新的科学基准数据集:CLIMATE-CHANGE NER(实体识别)、NASA-QA(抽取式问答)和NASA-IR(信息检索),以加速这些多学科领域的研究。实验表明,INDUS模型在这些新任务以及相关领域的现有任务上,均优于通用模型(RoBERTa)和领域特定模型(SCIBERT)。最后,展示了这些模型在两个工业环境中的应用——作为大规模向量搜索应用中的检索模型和在自动内容标记系统中。
🔬 方法详解
问题定义:现有的大型语言模型虽然在通用领域表现出色,但在特定科学领域,由于缺乏针对性的训练数据和领域知识,性能往往受限。领域特定的模型虽然有所改进,但仍然存在性能瓶颈,并且缺乏统一的、高质量的基准数据集进行评估。
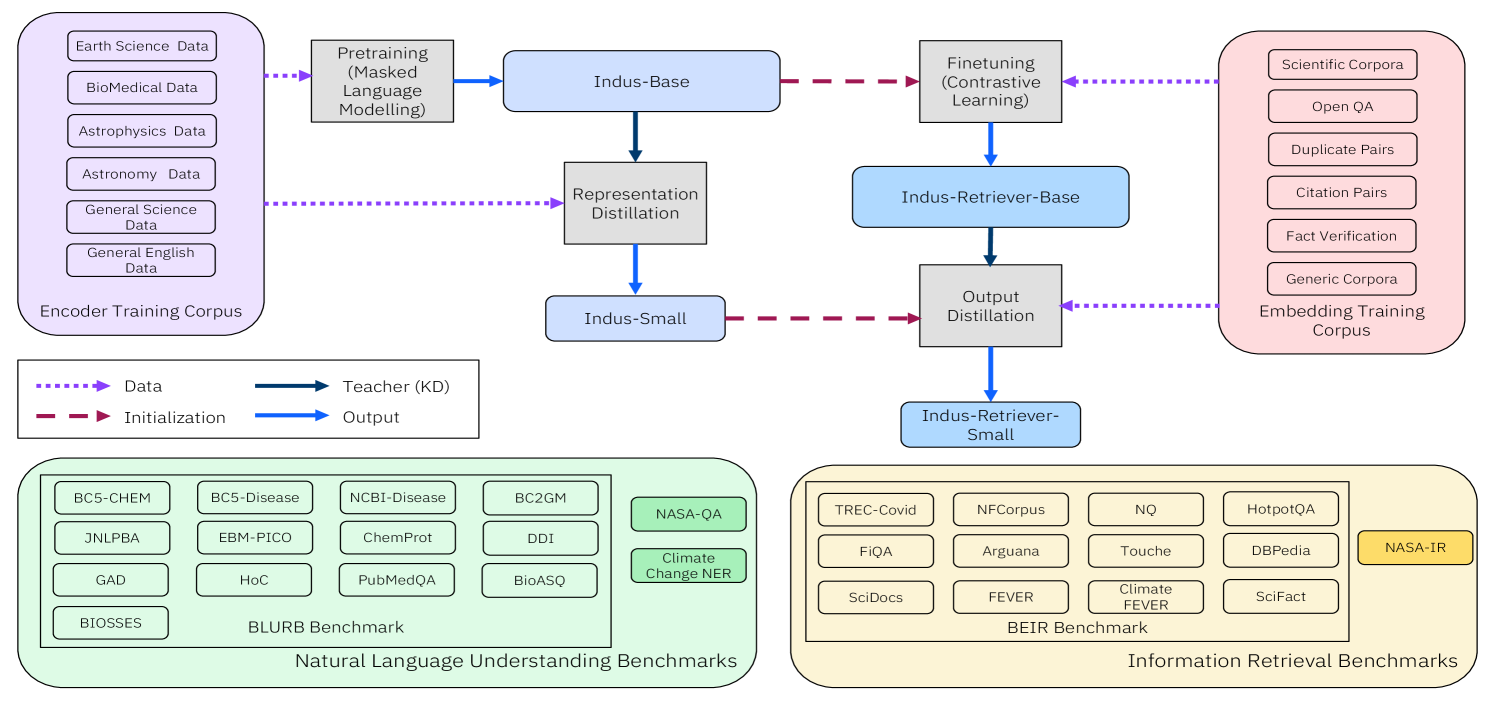
核心思路:本文的核心思路是构建一套专门针对多个科学领域(地球科学、生物学、物理学等)的大型语言模型INDUS。通过收集和整理大量的领域特定语料库,并采用领域相关的词汇表进行训练,使模型能够更好地理解和处理科学领域的文本数据。同时,利用知识蒸馏技术,创建更小、更高效的模型版本,以适应资源受限的应用场景。
技术框架:INDUS模型套件包含三个主要部分:1) 领域特定编码器模型,用于处理NLP任务;2) 基于对比学习的文本嵌入模型,用于信息检索任务;3) 通过知识蒸馏得到的轻量级模型,适用于低延迟或资源受限的场景。整个训练流程包括数据收集与清洗、模型预训练、领域特定微调和知识蒸馏等步骤。此外,还构建了三个新的科学基准数据集,用于评估模型的性能。
关键创新:INDUS的关键创新在于其针对多个科学领域构建了统一的、高质量的语言模型套件。与以往的领域特定模型相比,INDUS覆盖的领域更广,并且采用了对比学习和知识蒸馏等先进技术,提高了模型的性能和效率。此外,新构建的科学基准数据集为该领域的研究提供了重要的评估工具。
关键设计:领域特定编码器模型基于Transformer架构,采用领域相关的词汇表进行训练。对比学习的文本嵌入模型使用多种损失函数,以提高嵌入向量的质量。知识蒸馏过程使用教师-学生框架,将大型模型的知识迁移到小型模型中。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
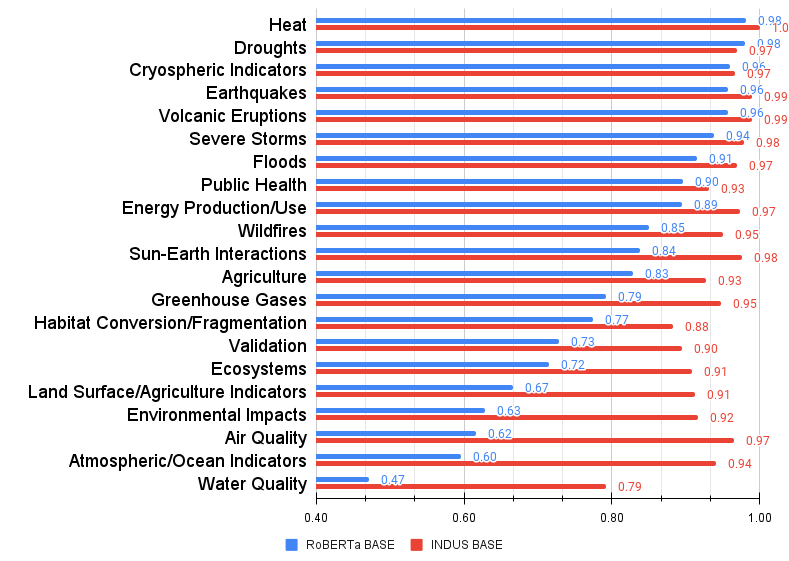
INDUS模型在新建的CLIMATE-CHANGE NER、NASA-QA和NASA-IR数据集上,以及相关领域的现有任务上,均优于通用模型RoBERTa和领域特定模型SCIBERT。具体的性能提升数据未在摘要中给出,属于未知信息。该模型还在大规模向量搜索和自动内容标记系统中得到了实际应用验证。
🎯 应用场景
INDUS模型具有广泛的应用前景,包括科学文献检索、自动内容标记、知识发现、科学数据分析等。例如,可以用于构建更智能的科学搜索引擎,帮助研究人员快速找到所需的文献资料;可以用于自动标注科学论文,提高文献管理的效率;还可以用于从科学数据中提取有用的信息,促进科学研究的进展。在工业界,INDUS可以应用于大规模向量搜索和自动内容标记系统。
📄 摘要(原文)
Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this insight, we developed INDUS, a comprehensive suite of LLMs tailored for the closely-related domains of Earth science, biology, physics, heliophysics, planetary sciences and astrophysics, and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address NLP tasks, (2) a contrastive-learning based text embedding model trained using a diverse set of datasets to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation for applications which have latency or resource constraints. We also created three new scientific benchmark datasets, CLIMATE-CHANGE NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. We show that our models outperform both general-purpose (RoBERTa) and domain-specific (SCIBERT) encoders on these new tasks as well as existing tasks in the domains of interest. Furthermore, we demonstrate the use of these models in two industrial settings -- as a retrieval model for large-scale vector search applications and in automatic content tagging systems.