Layer-Condensed KV Cache for Efficient Inference of Large Language Models
作者: Haoyi Wu, Kewei Tu
分类: cs.CL
发布日期: 2024-05-17 (更新: 2024-06-04)
备注: Accepted to ACL2024 main conference
🔗 代码/项目: GITHUB
💡 一句话要点
提出层压缩KV缓存,显著提升大语言模型推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 KV缓存 推理加速 内存优化 Transformer 层压缩
📋 核心要点
- 现有大语言模型推理时,Transformer架构中注意力机制的KV缓存消耗大量内存,限制了模型部署。
- 论文提出层压缩KV缓存方法,仅计算和缓存少量层的KV,从而降低内存消耗,提升推理速度。
- 实验表明,该方法相比标准Transformer,吞吐量提升高达26倍,并在语言建模和下游任务中表现出色。
📝 摘要(中文)
在实际应用中部署高吞吐量的大型语言模型的主要瓶颈在于巨大的内存消耗。除了大量的参数之外,Transformer架构中注意力机制的键值(KV)缓存消耗了大量的内存,特别是对于深度语言模型来说,层数很多时更是如此。本文提出了一种新颖的方法,该方法仅计算和缓存少量层的KV,从而显著节省内存消耗并提高推理吞吐量。在大型语言模型上的实验表明,我们的方法实现了高达26倍于标准Transformer的吞吐量,并在语言建模和下游任务中具有竞争力的性能。此外,我们的方法与现有的Transformer内存节省技术是正交的,因此可以直接将它们与我们的模型集成,从而进一步提高推理效率。我们的代码可在https://github.com/whyNLP/LCKV 获取。
🔬 方法详解
问题定义:大语言模型部署面临的主要挑战之一是其巨大的内存占用,特别是Transformer模型中的KV缓存。随着模型层数的增加,KV缓存消耗的内存量也随之线性增长,这限制了模型在资源受限环境中的部署和应用。现有方法要么牺牲模型性能,要么需要复杂的硬件加速,成本较高。
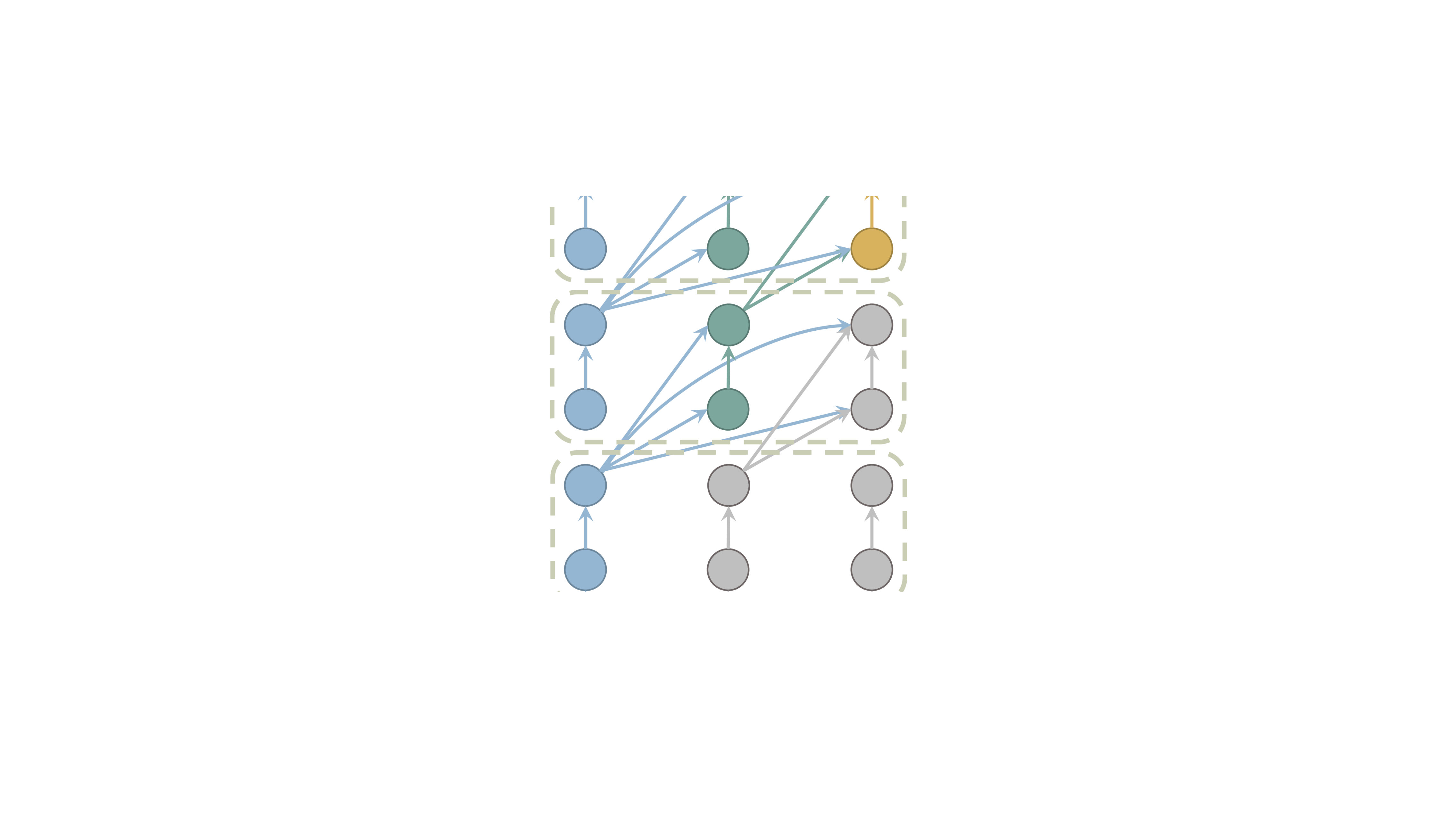
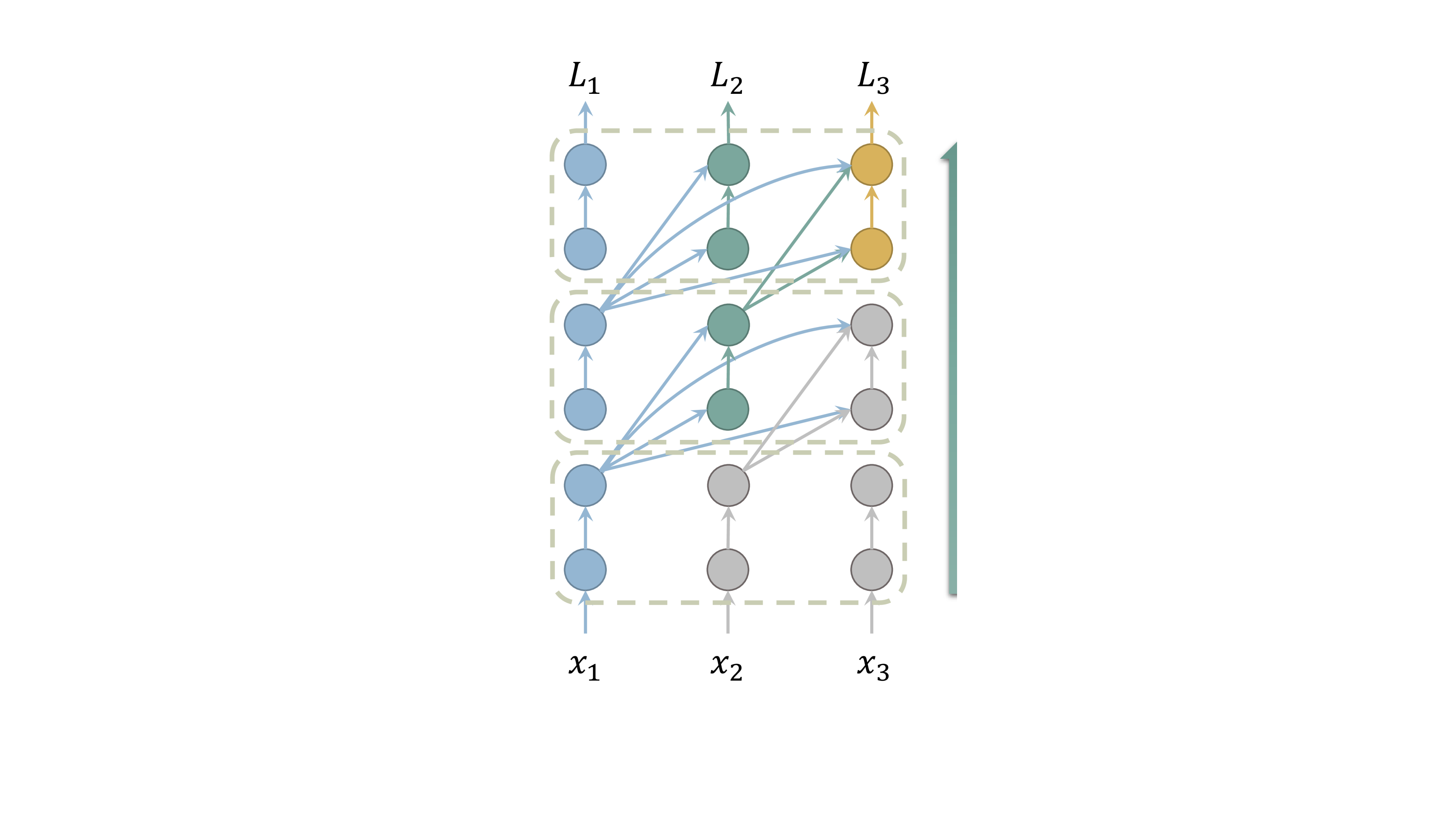
核心思路:论文的核心思路是只保留部分层的KV缓存,而不是所有层都进行缓存。通过选择性地缓存关键层的KV,可以在显著减少内存占用的同时,尽可能地保持模型的性能。这种方法基于一个假设,即并非所有层的KV信息都对最终的预测结果具有同等的重要性。
技术框架:该方法的核心在于选择哪些层来计算和缓存KV。整体流程包括:首先,确定需要压缩的层数比例;然后,设计一种策略来选择要保留KV的层(例如,均匀选择、基于重要性选择等);最后,在推理过程中,只计算和缓存选定层的KV,而其他层的KV则不进行计算和缓存。该方法可以很容易地集成到现有的Transformer架构中。
关键创新:该方法最重要的创新点在于提出了层压缩的概念,即通过减少需要缓存的层数来降低内存占用。与现有方法相比,该方法不需要修改Transformer的整体结构,也不需要引入额外的硬件加速,因此具有更高的灵活性和易用性。此外,该方法与现有的Transformer内存优化技术是正交的,可以结合使用以获得更好的性能。
关键设计:关键设计包括如何选择需要保留KV的层。论文可能探讨了不同的选择策略,例如均匀选择、基于层的重要性进行选择等。此外,可能还涉及一些超参数的调整,例如需要保留的层数比例,以及如何平衡内存占用和模型性能。具体的损失函数和网络结构与原始Transformer模型保持一致,无需修改。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在大型语言模型上实现了显著的性能提升。与标准Transformer相比,吞吐量提高了高达26倍。同时,在语言建模和下游任务中,该方法也取得了具有竞争力的性能。此外,该方法可以与现有的Transformer内存节省技术相结合,进一步提高推理效率。
🎯 应用场景
该研究成果可广泛应用于大语言模型的部署和推理加速,尤其是在资源受限的环境中,如移动设备、边缘计算等。通过减少内存占用,可以支持更大规模的模型部署,提高推理吞吐量,从而提升用户体验。此外,该方法还可以应用于各种自然语言处理任务,如文本生成、机器翻译、问答系统等。
📄 摘要(原文)
Huge memory consumption has been a major bottleneck for deploying high-throughput large language models in real-world applications. In addition to the large number of parameters, the key-value (KV) cache for the attention mechanism in the transformer architecture consumes a significant amount of memory, especially when the number of layers is large for deep language models. In this paper, we propose a novel method that only computes and caches the KVs of a small number of layers, thus significantly saving memory consumption and improving inference throughput. Our experiments on large language models show that our method achieves up to 26$\times$ higher throughput than standard transformers and competitive performance in language modeling and downstream tasks. In addition, our method is orthogonal to existing transformer memory-saving techniques, so it is straightforward to integrate them with our model, achieving further improvement in inference efficiency. Our code is available at https://github.com/whyNLP/LCKV.